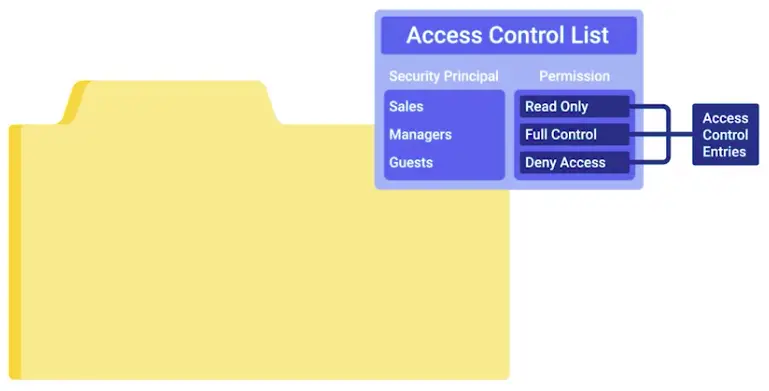
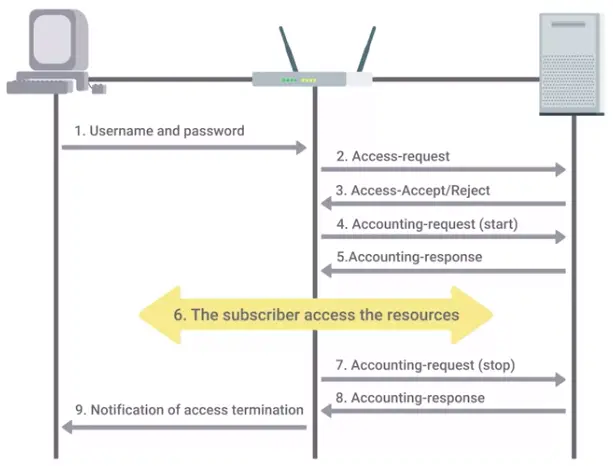
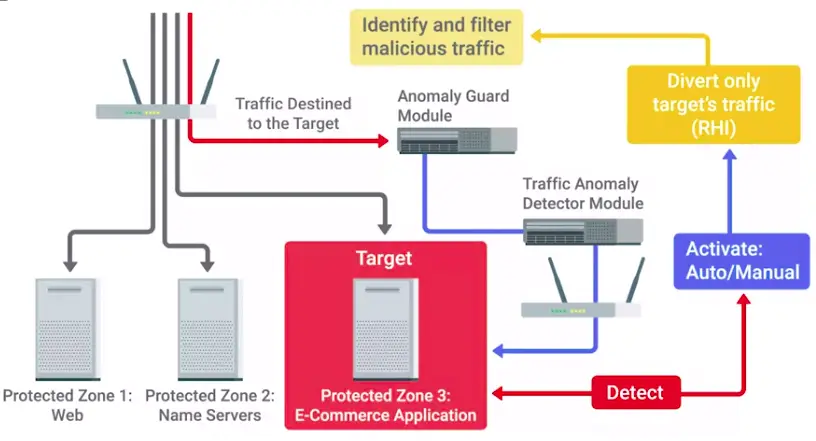
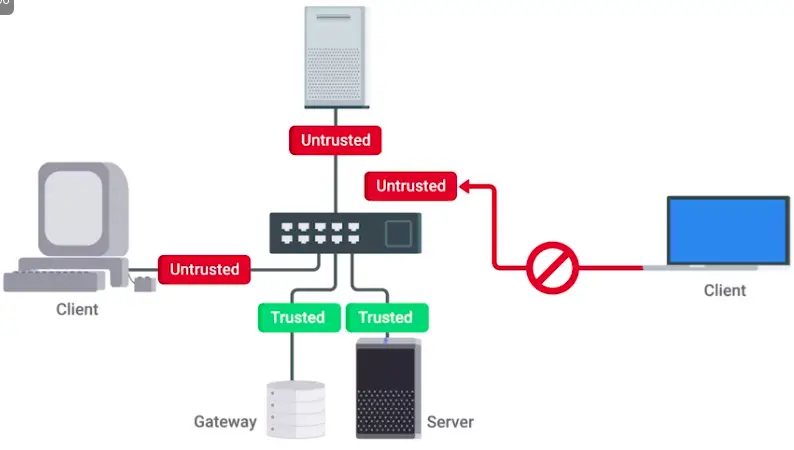
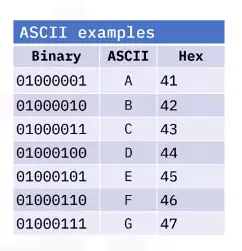
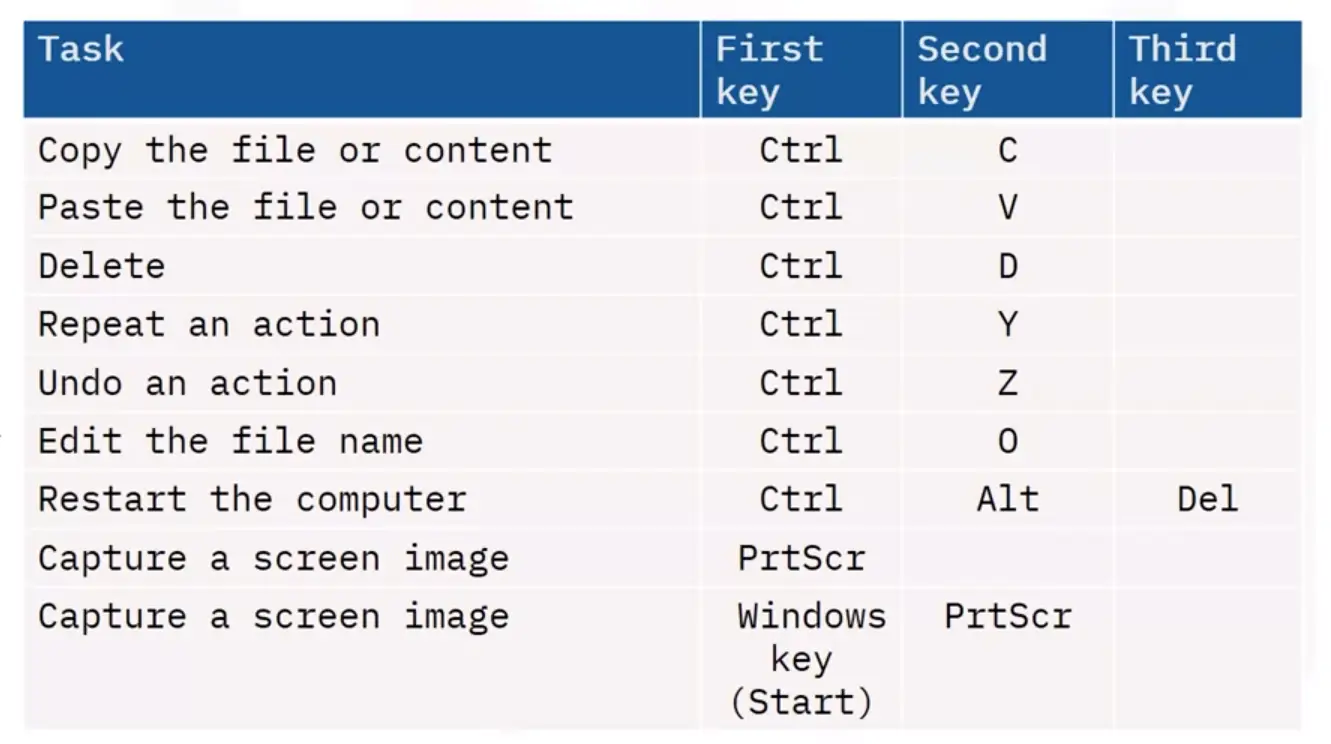
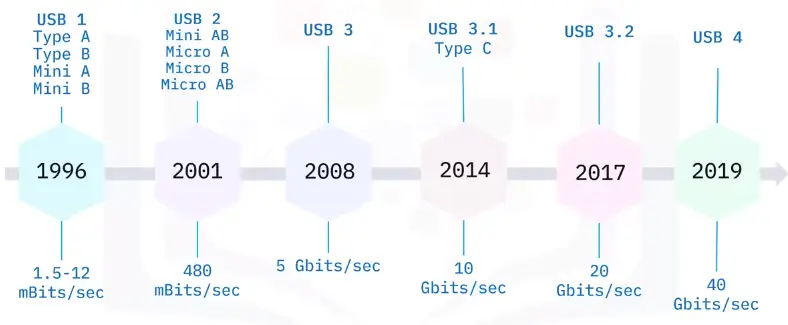
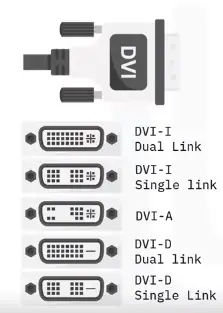
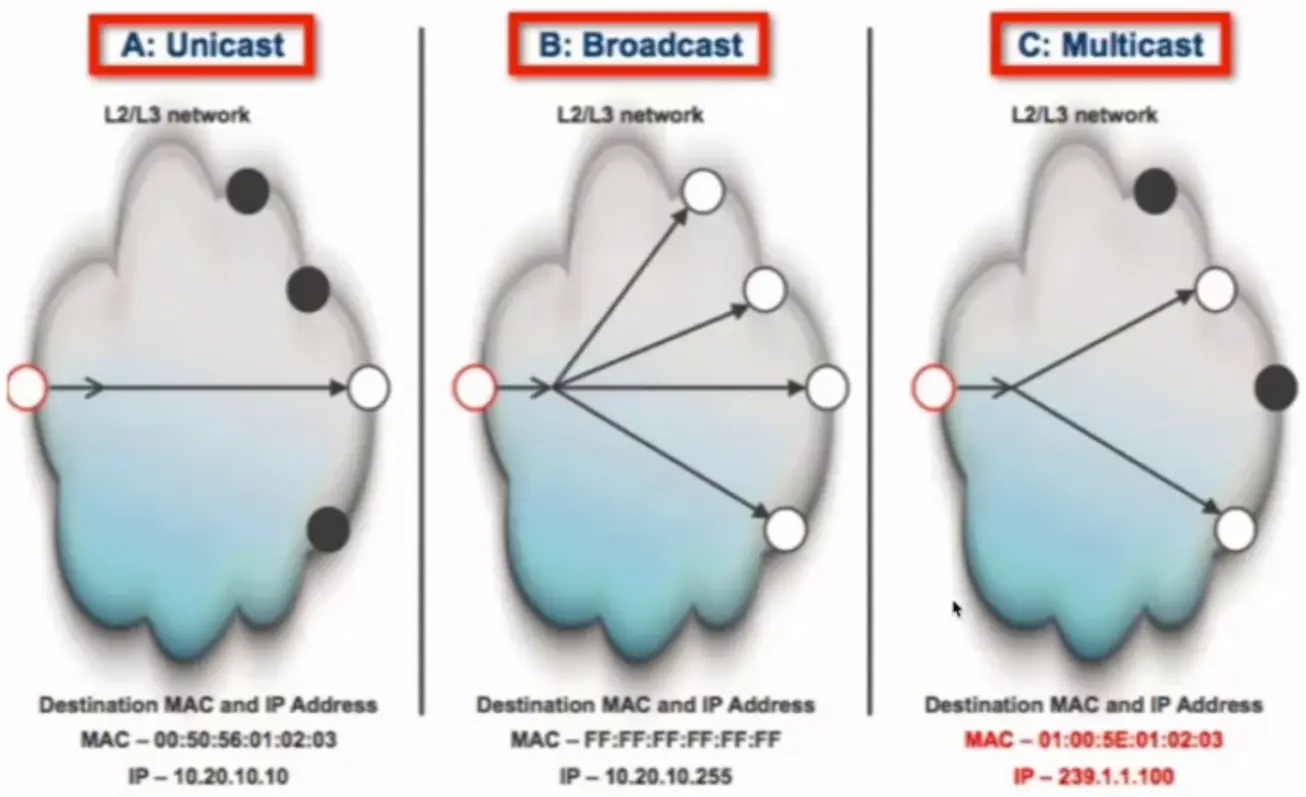
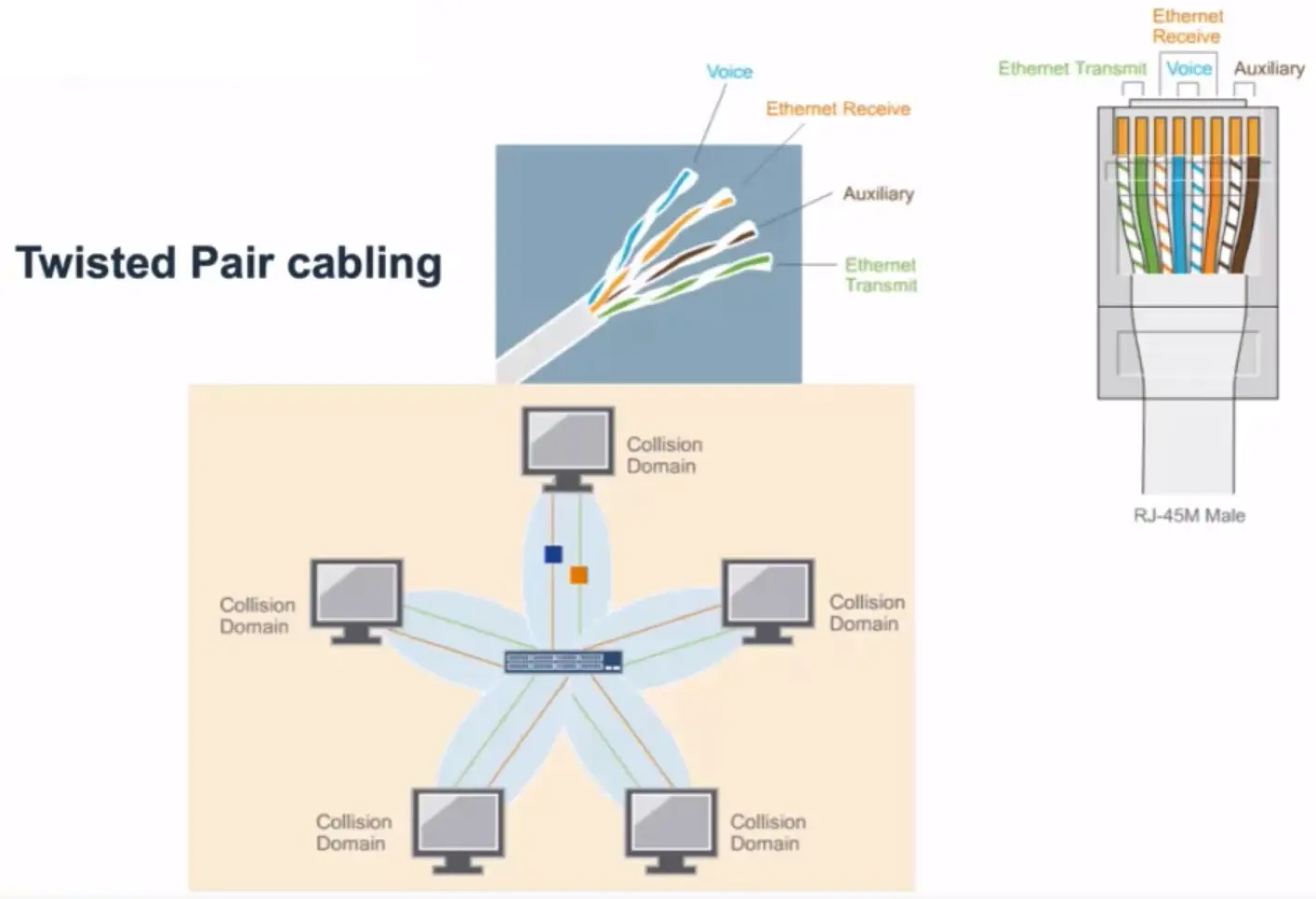
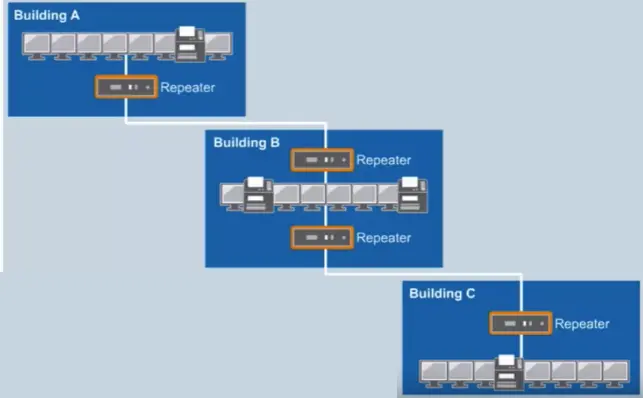
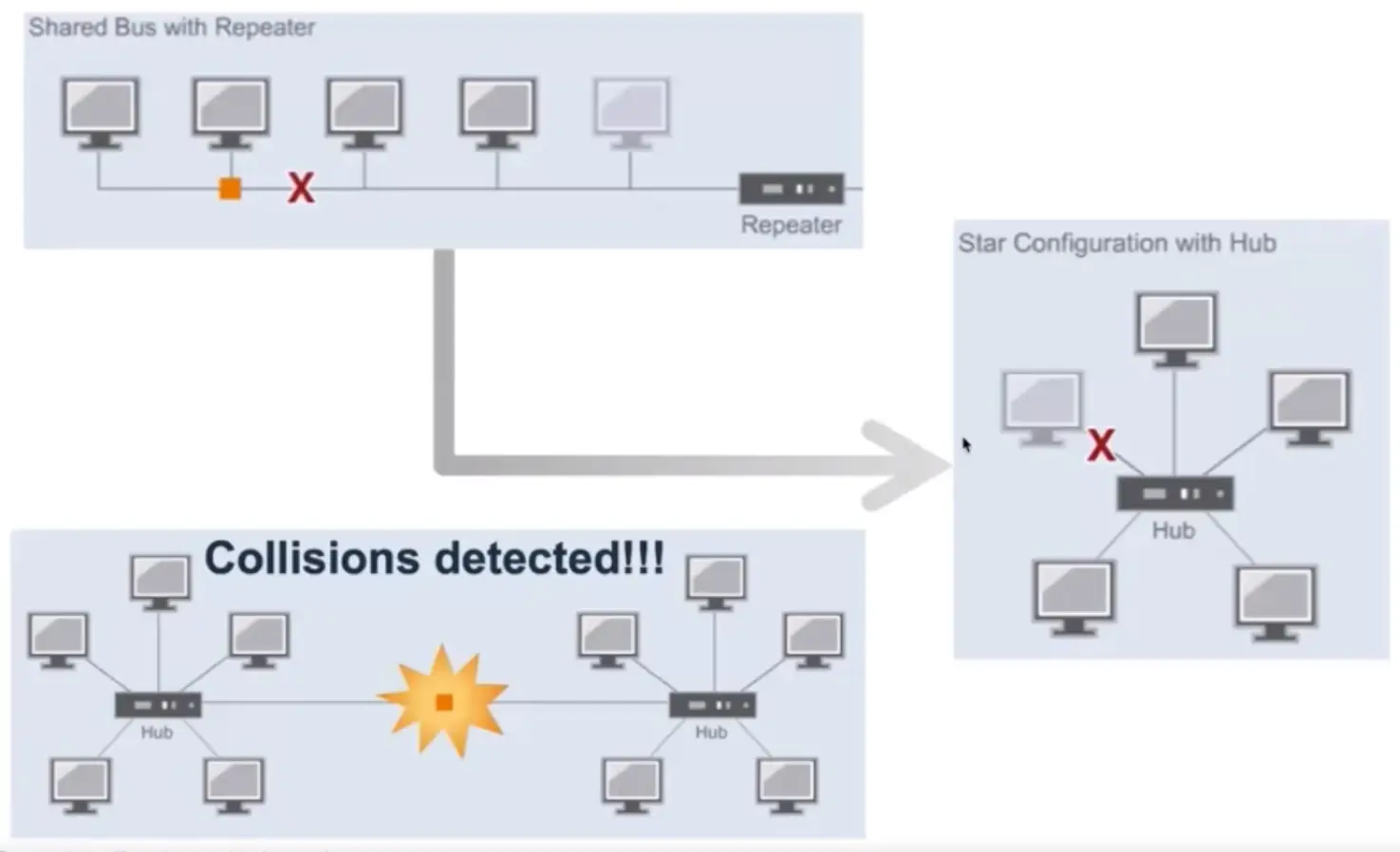
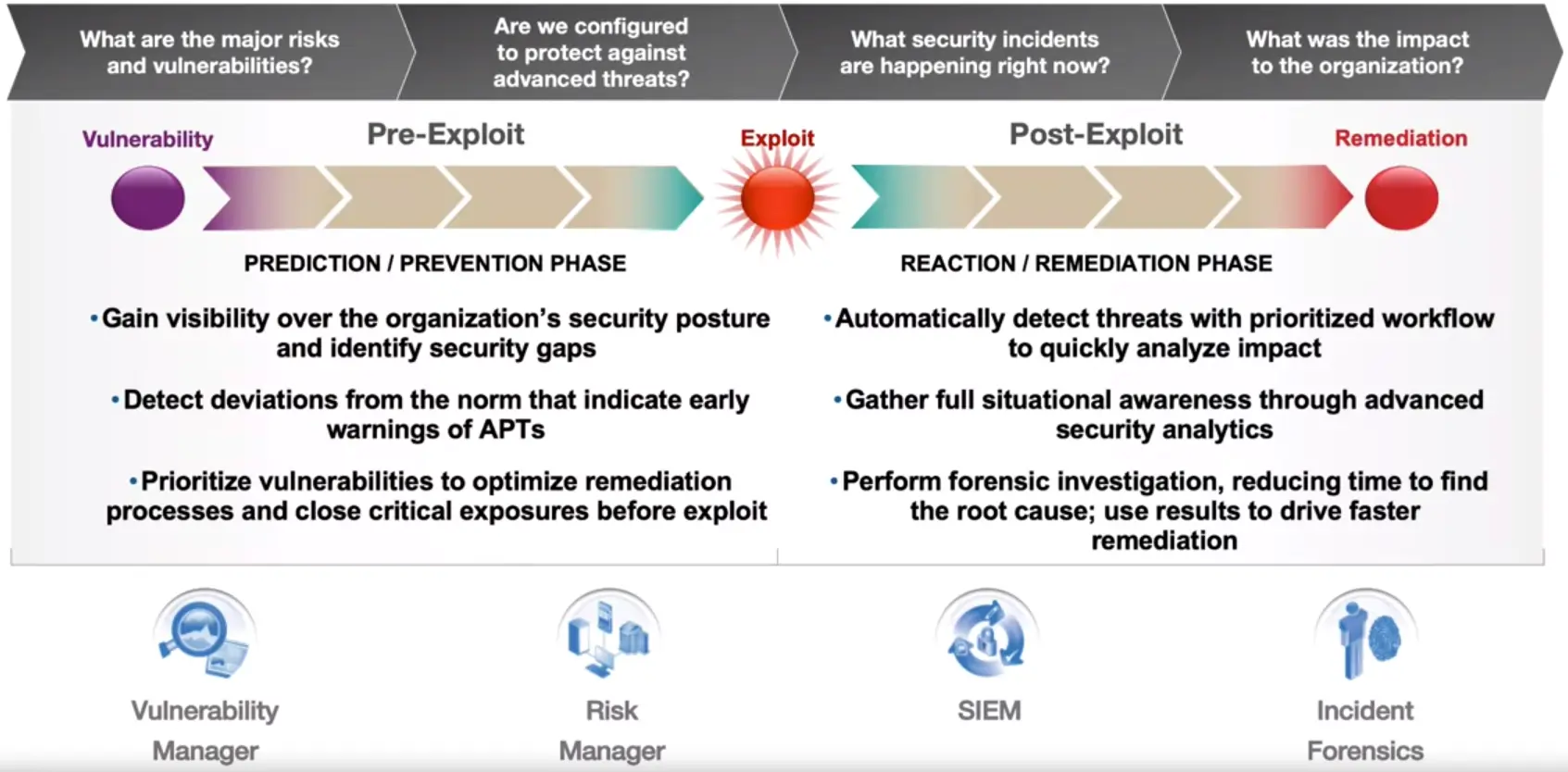
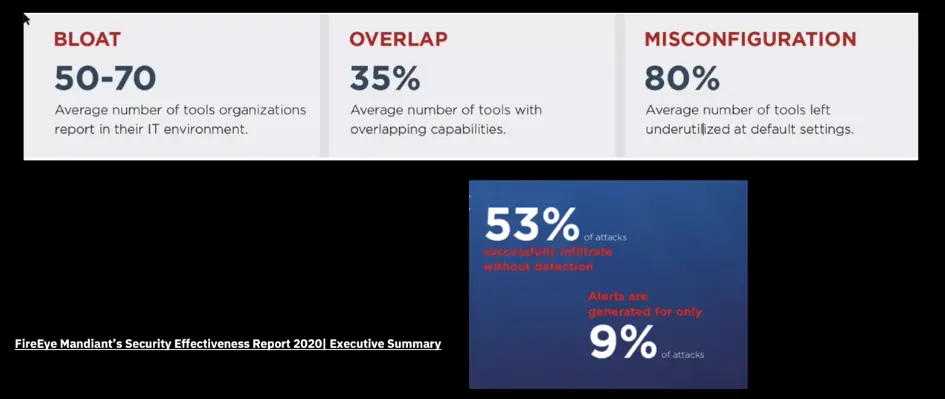
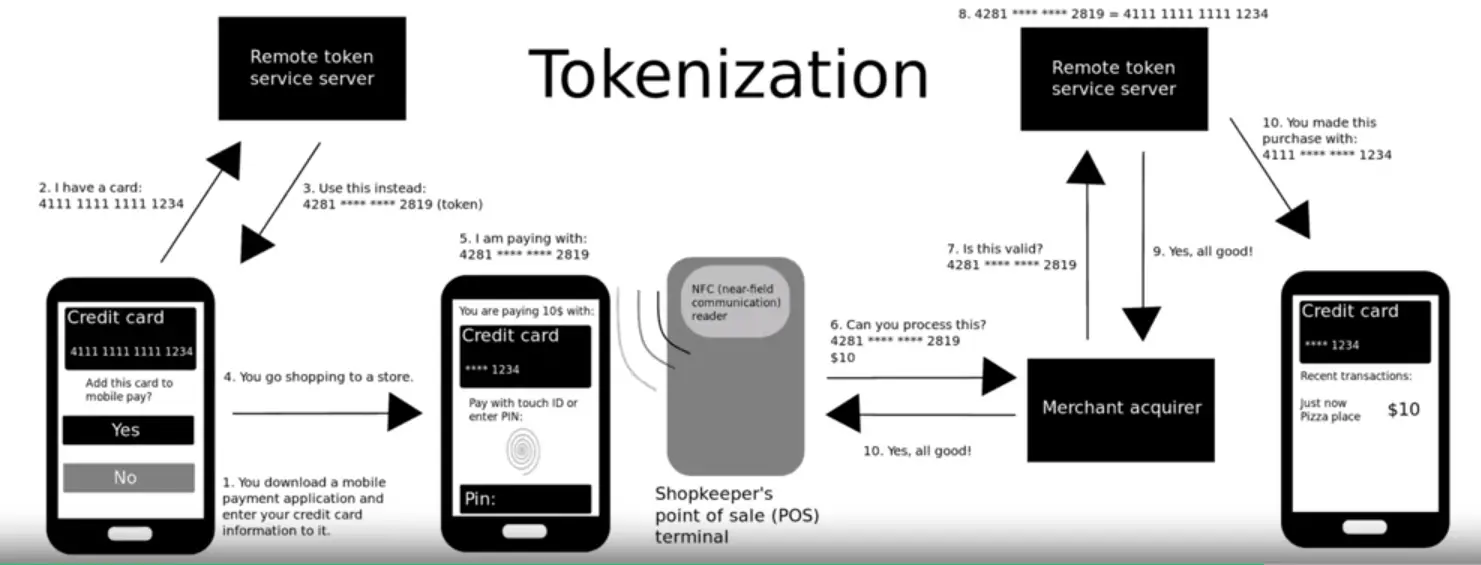
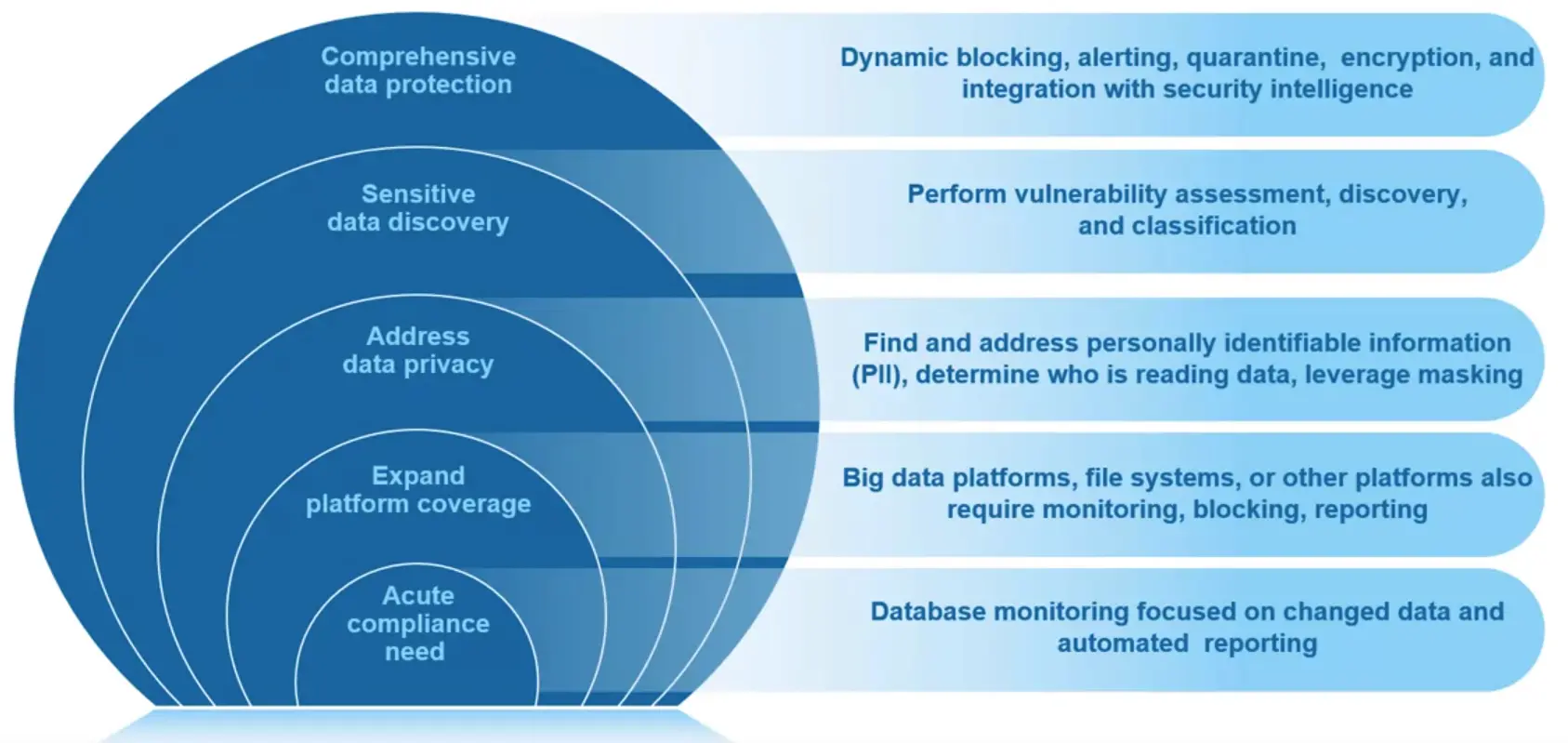
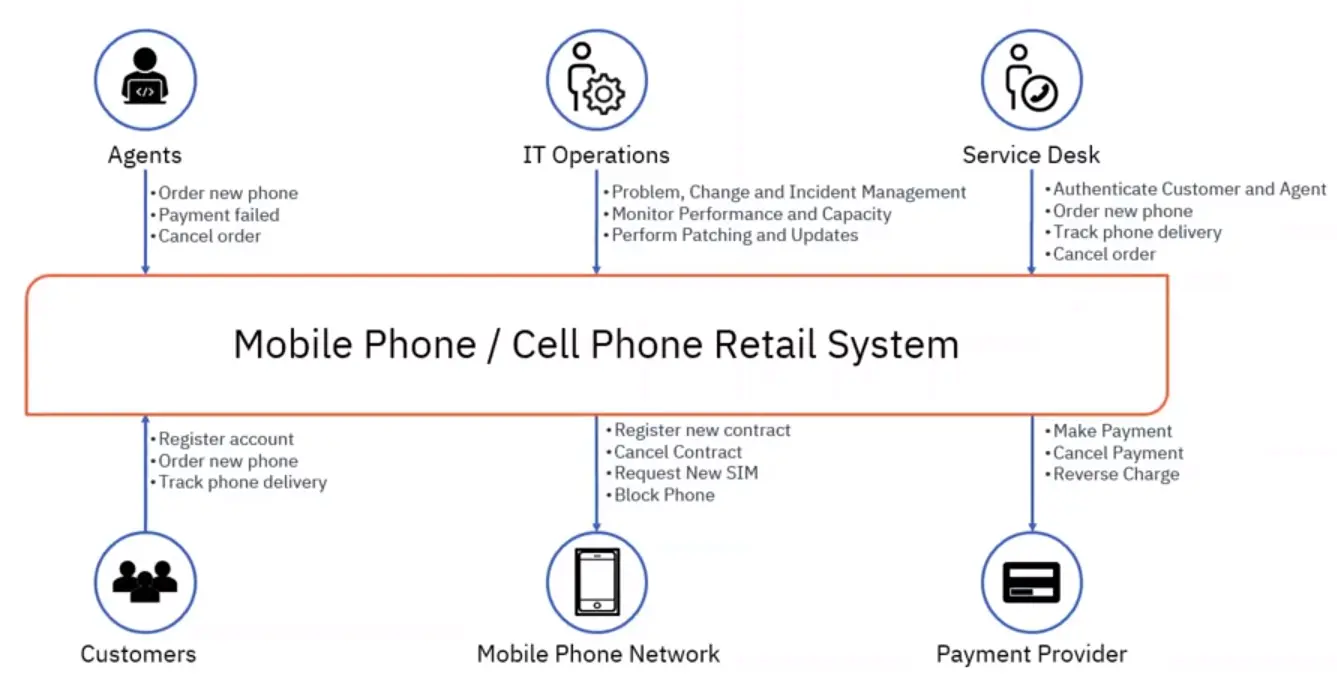
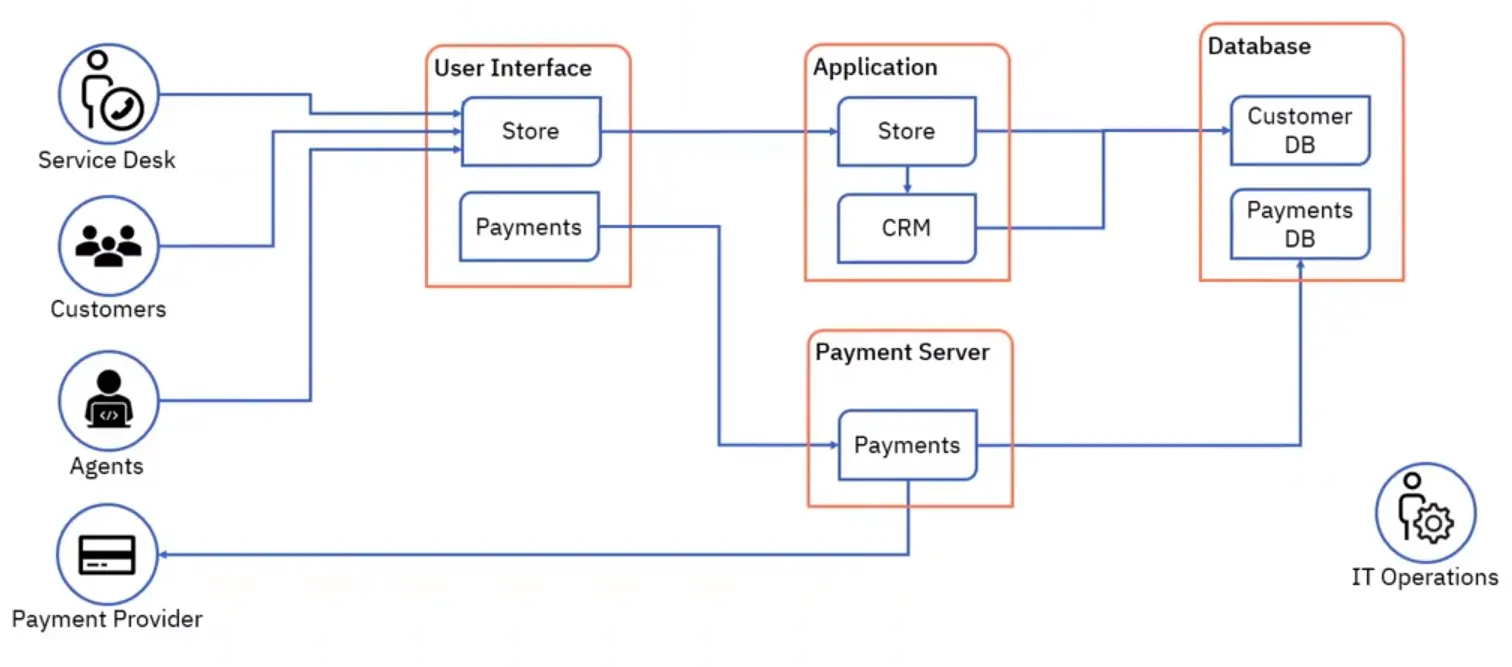
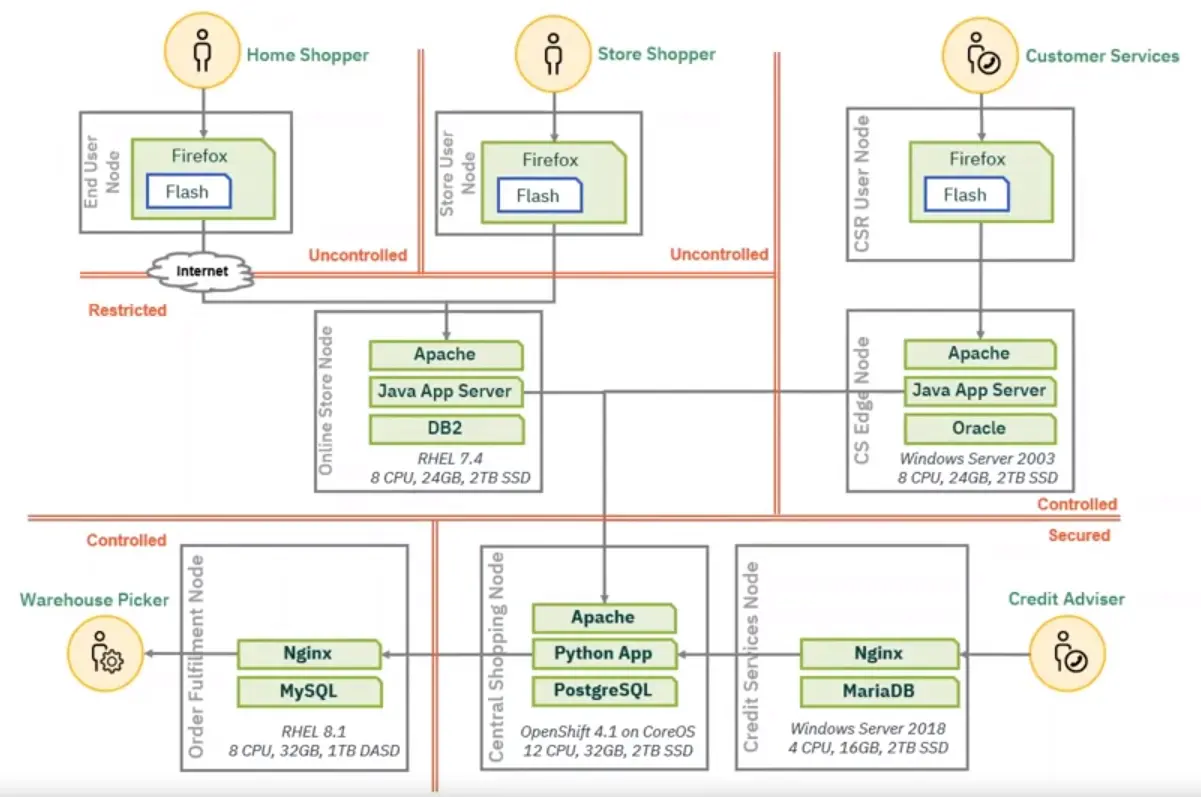
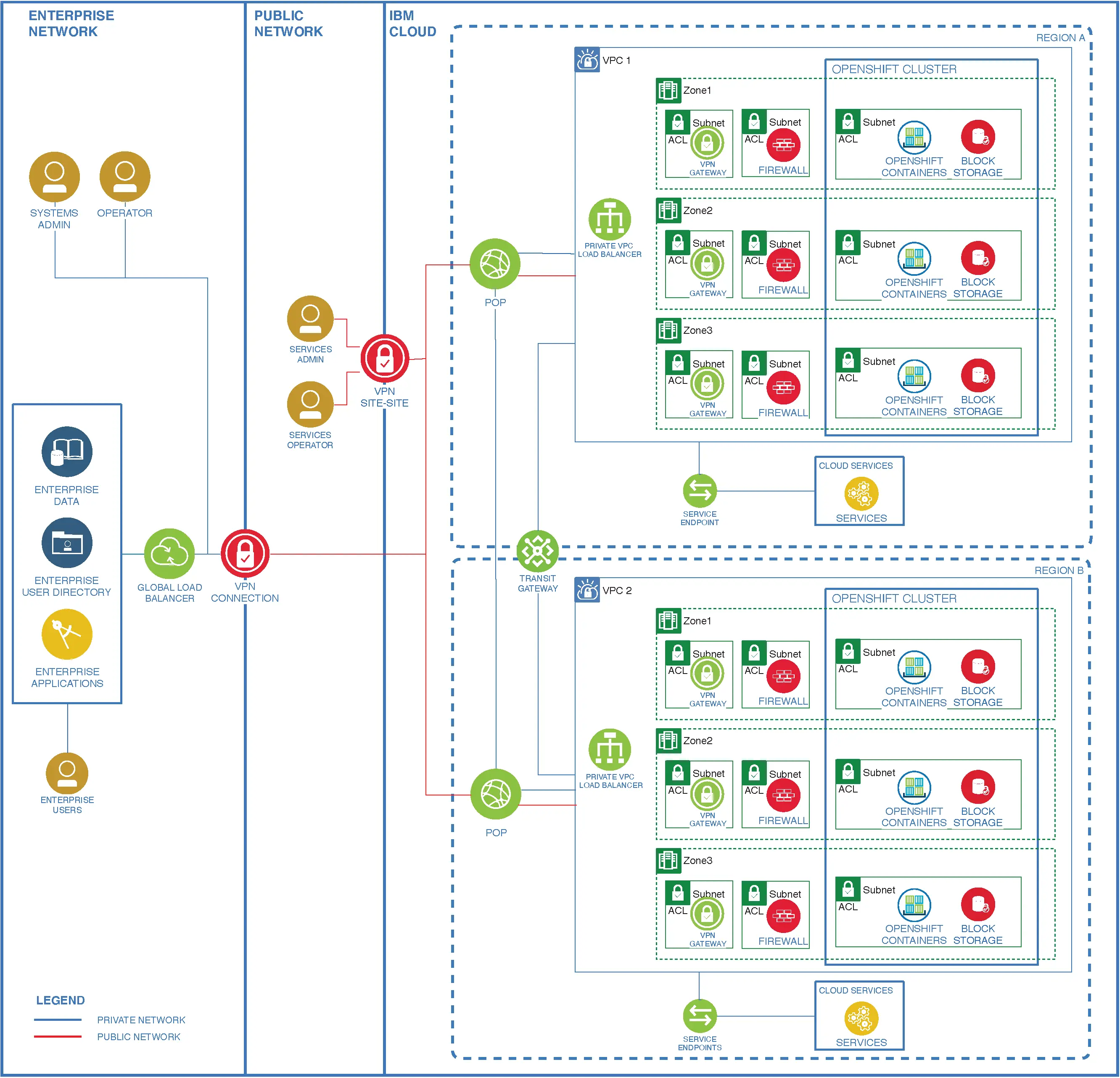
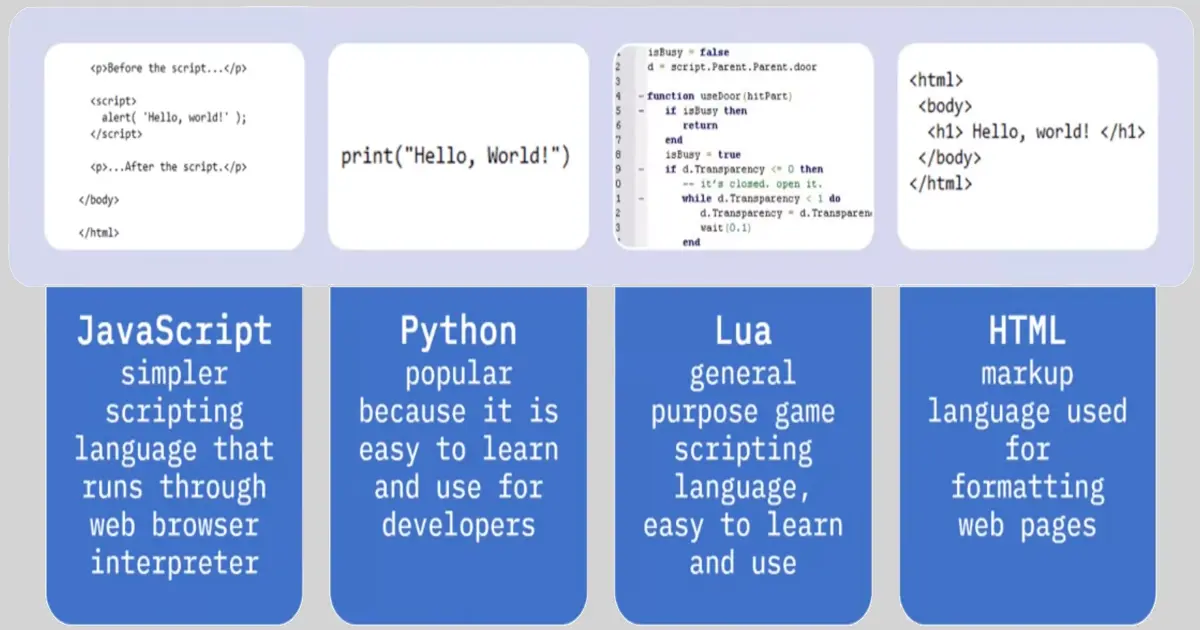
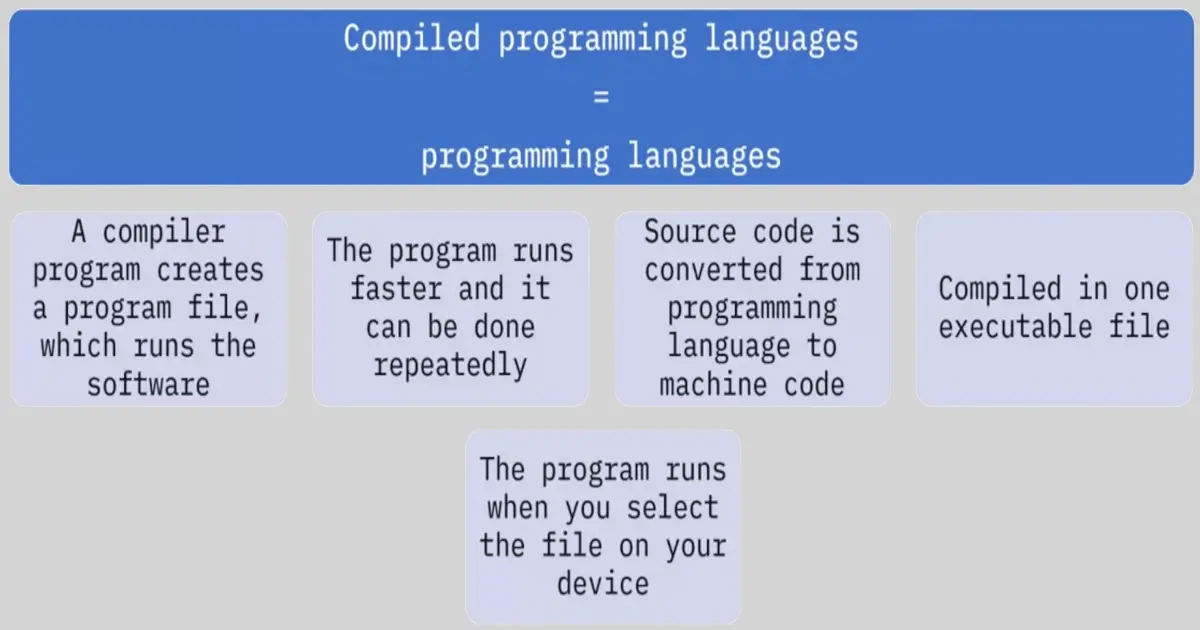
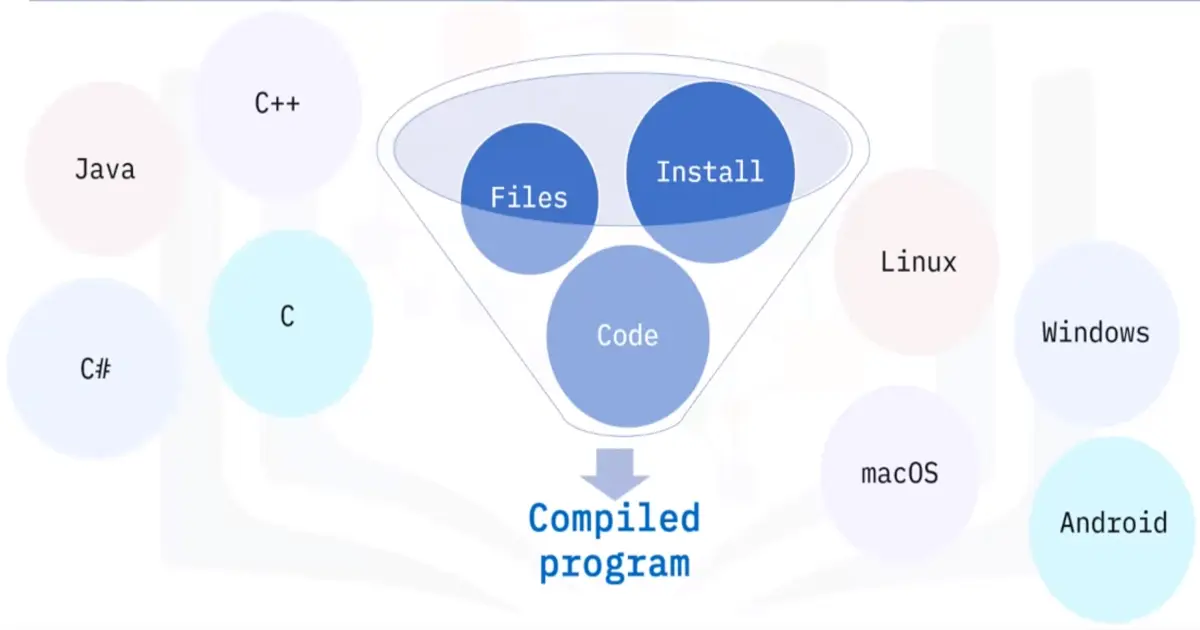
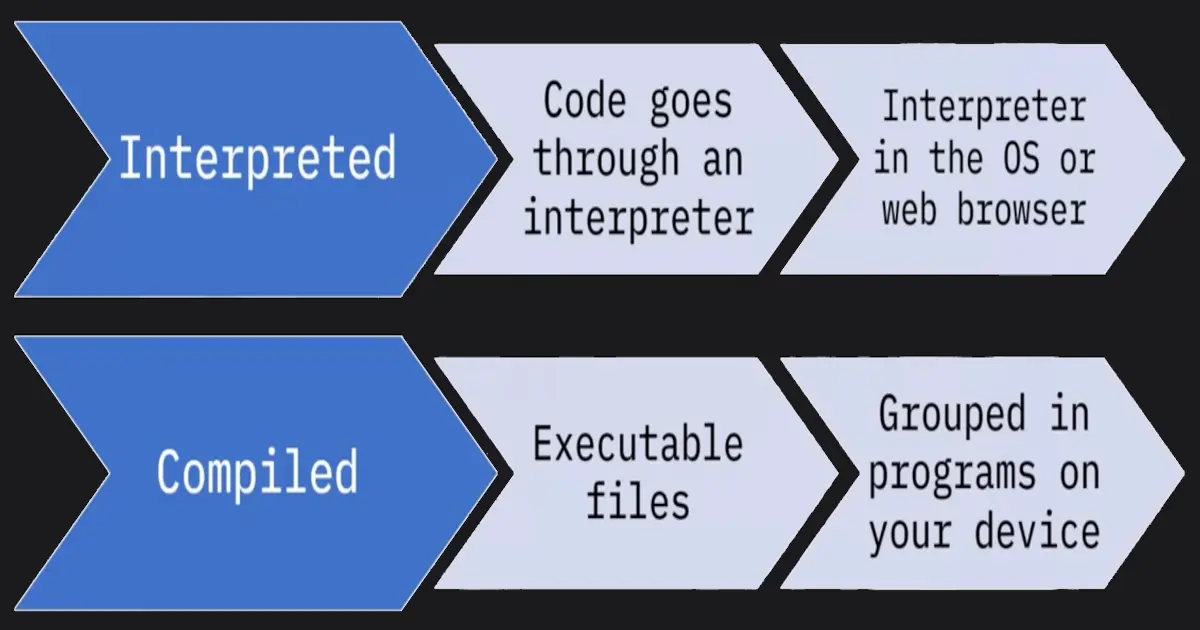
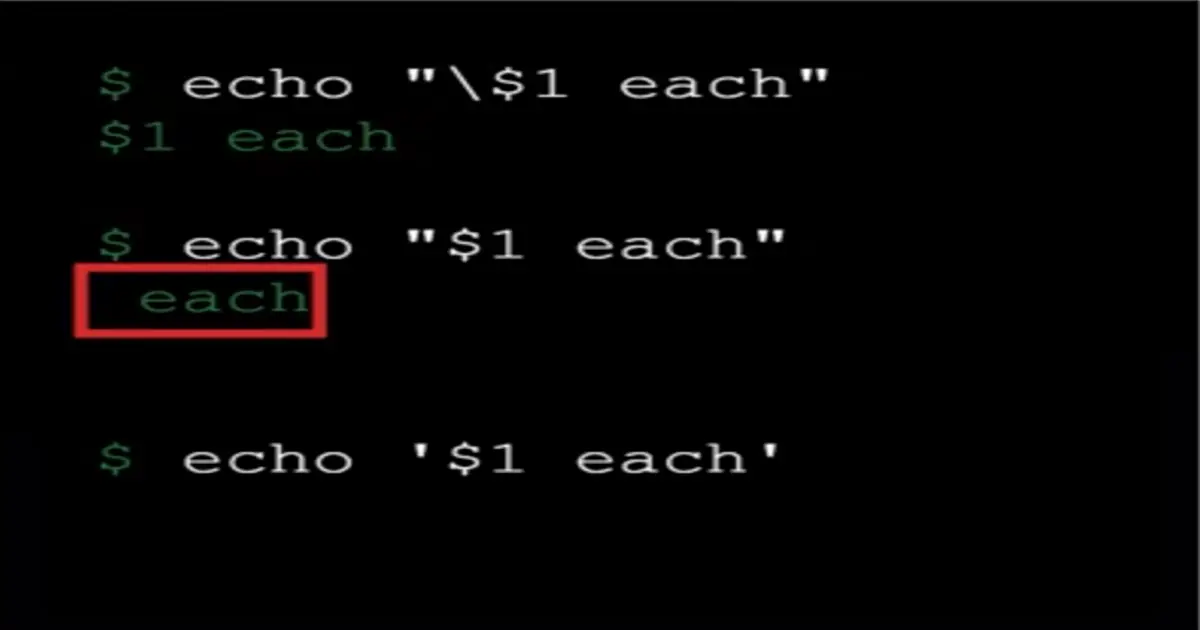
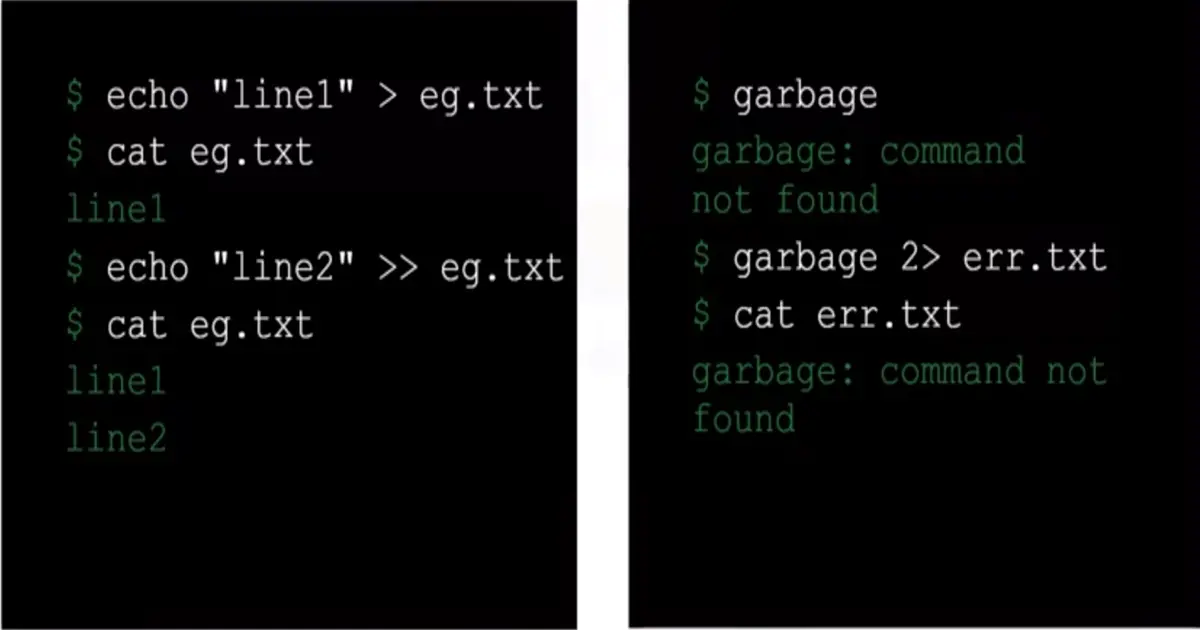
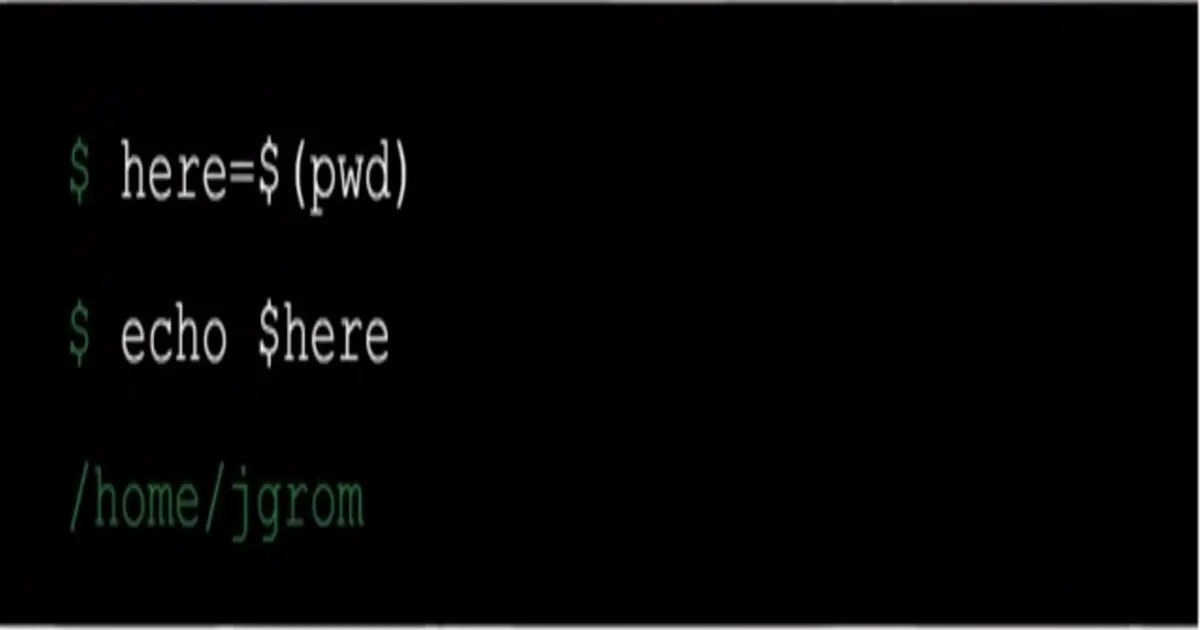
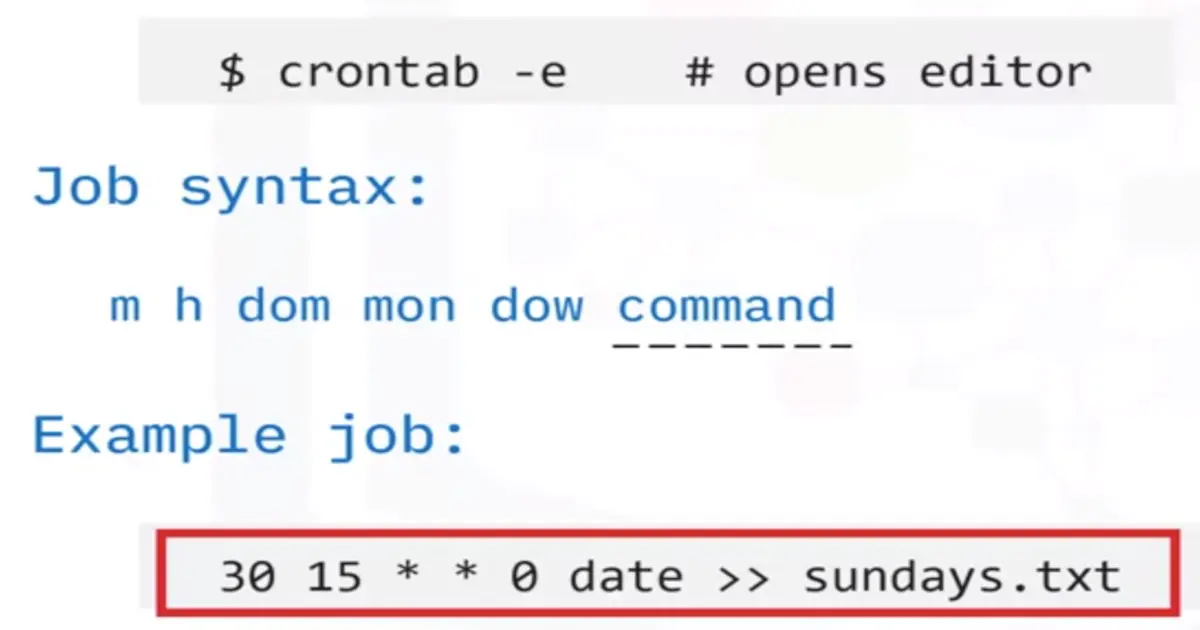
📚 This is where I share insights and knowledge from the many courses I’ve explored throughout my learning journey.
💡 Learning never stops! I’m always on the lookout for new opportunities to expand my understanding and sharpen my skills.
🔄 This Wiki is a dynamic space, regularly updated with fresh content and evolving knowledge streams.
🌱 Stay curious, and let’s grow together! 🚀
📖 Looking for more tech insights? Check out my blog at CYBERFRONT.ME, where I delve into topics like technology, cybersecurity, cloud computing, operating systems, and more! 🔐☁️💻
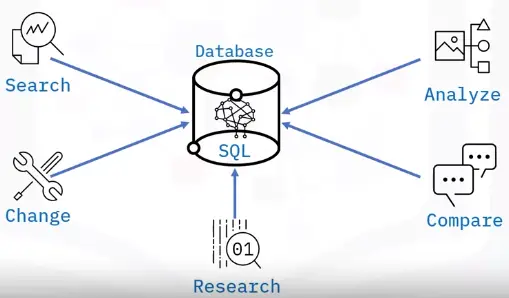
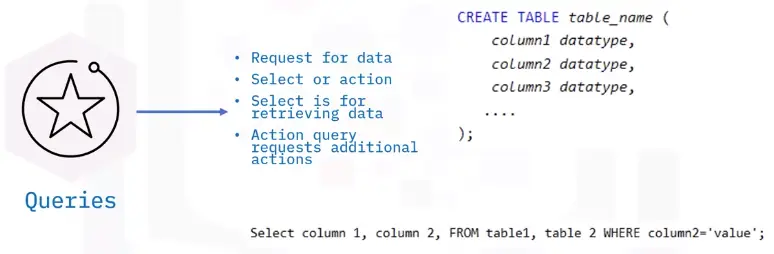
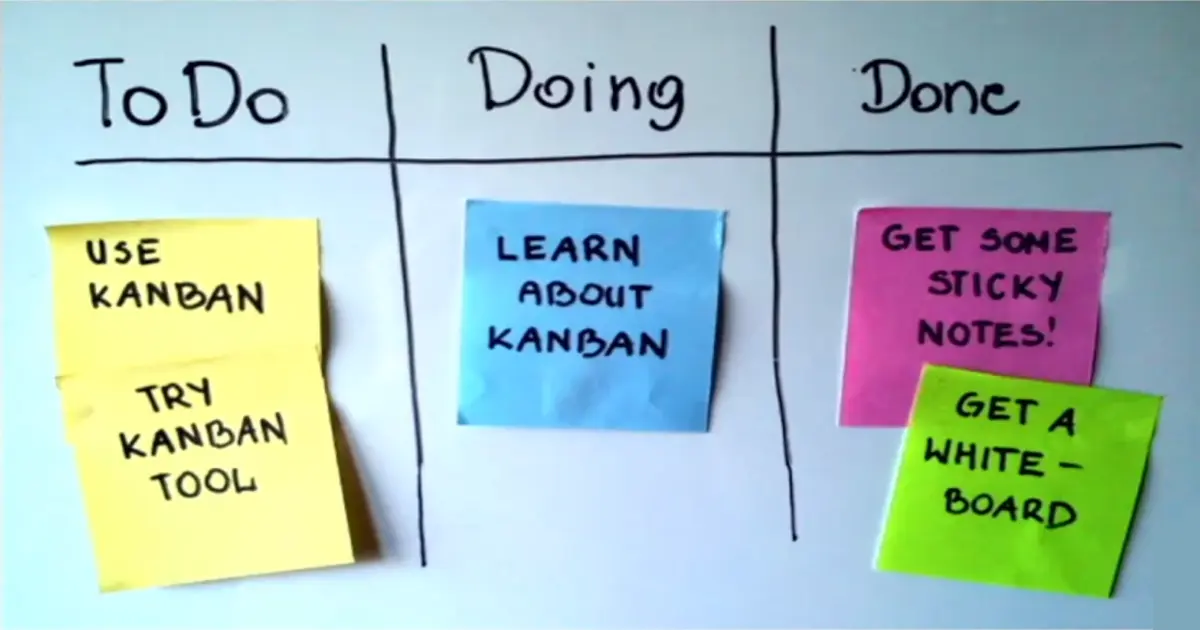
🎓 Educational Profiles 🎓
Following are my education profiles on different MOOC’s platforms.
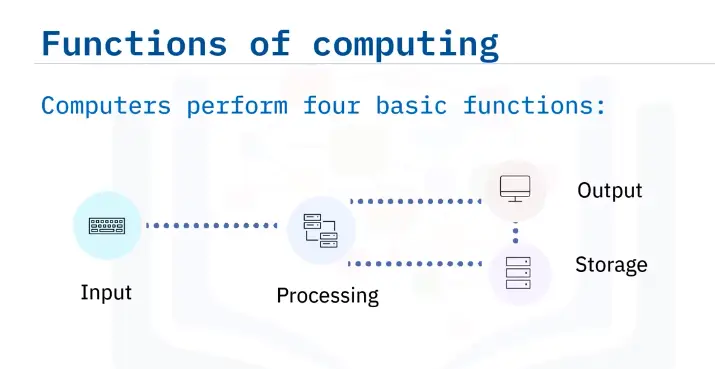
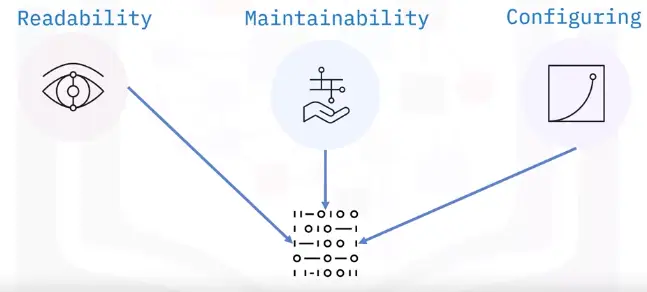
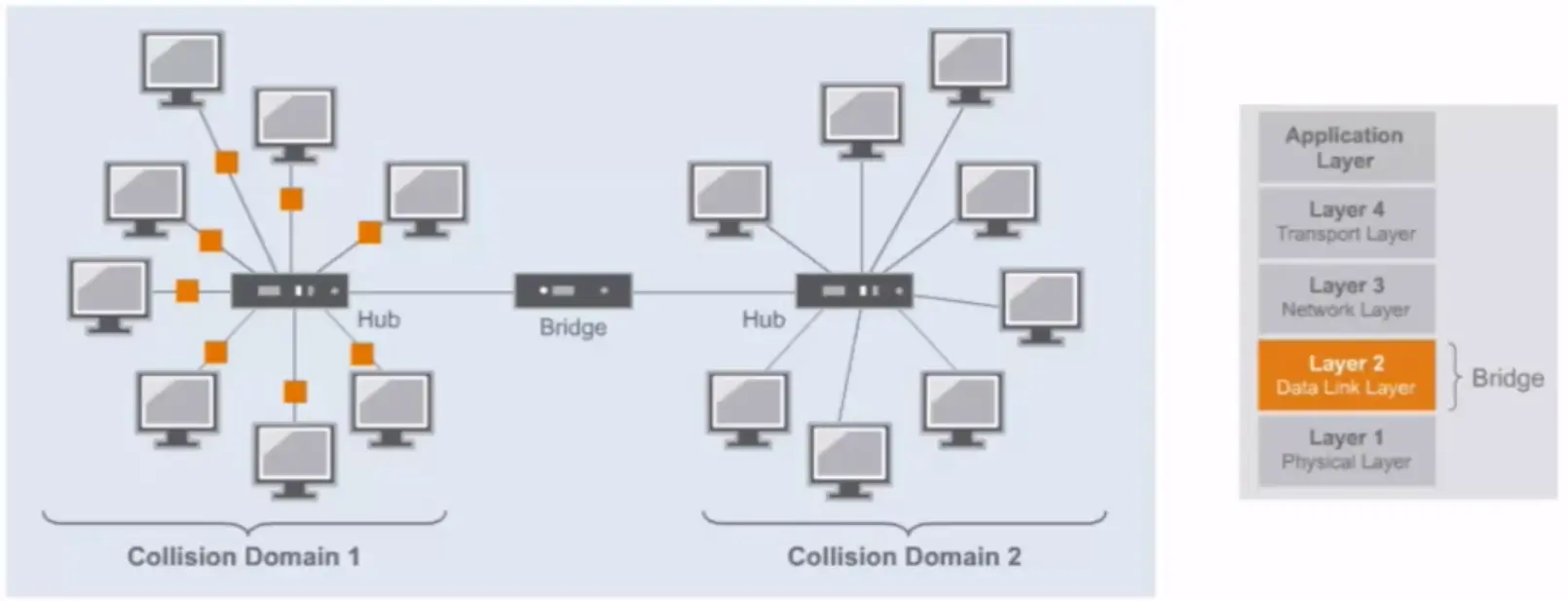
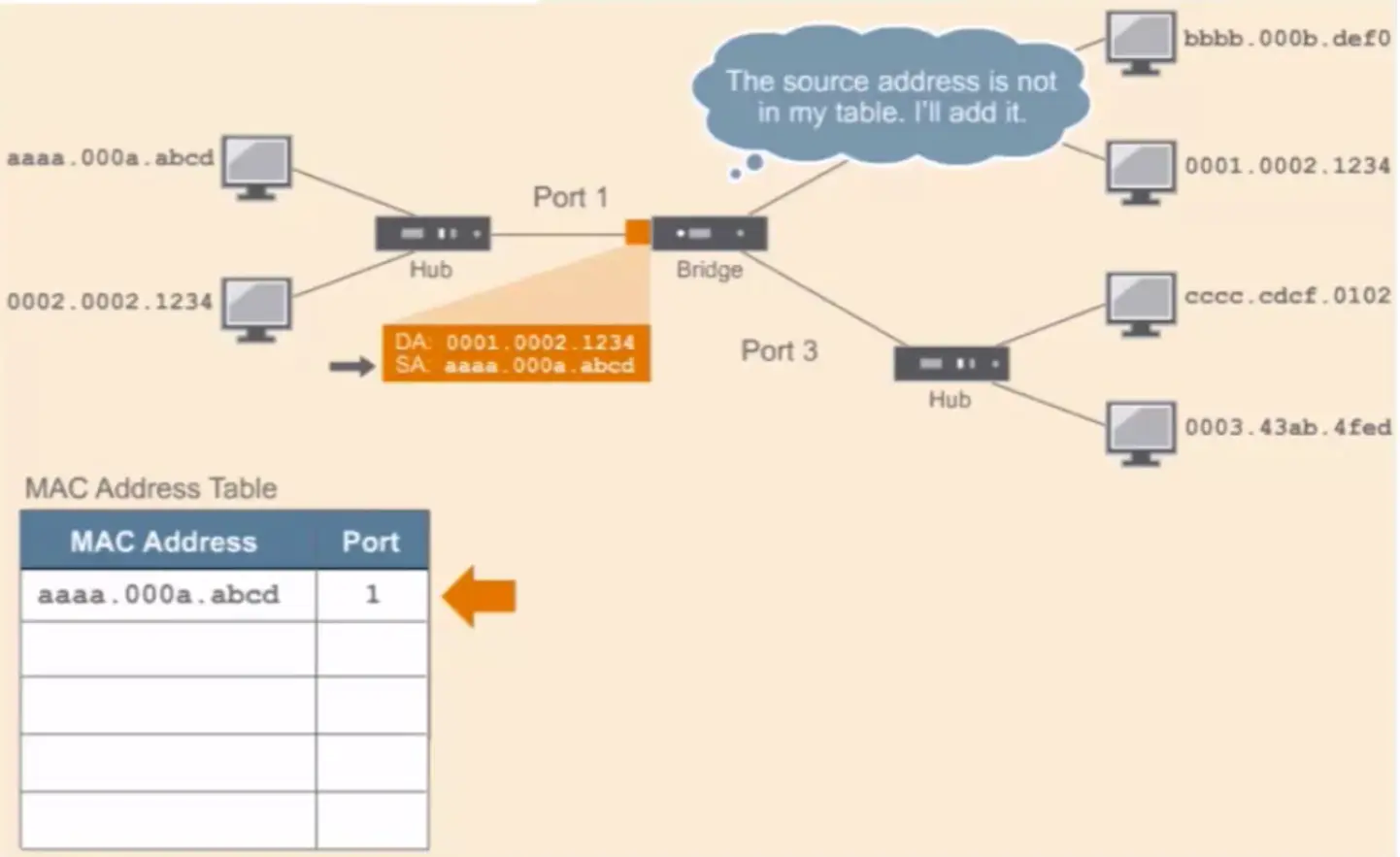
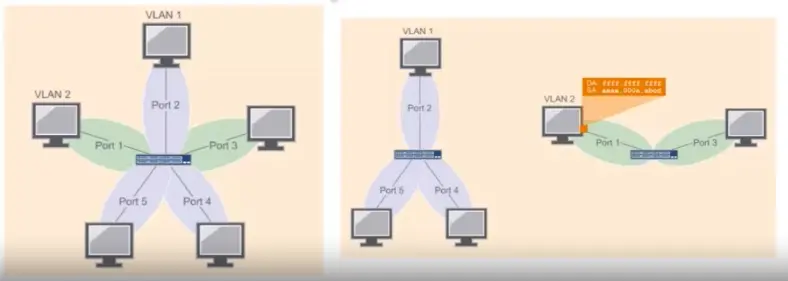
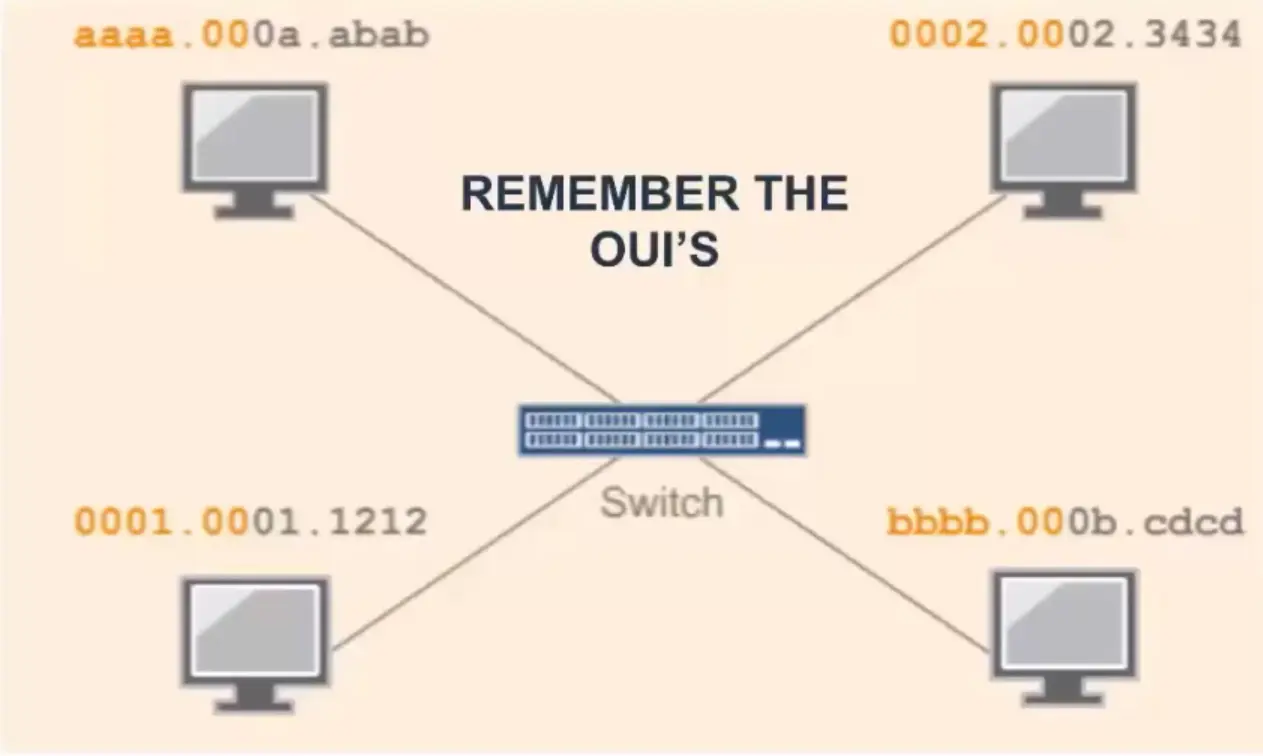
In computer science, an algorithm is a set of setups for a computer to accomplish a task.
Algorithm are reason why there is a science in a computer science.
Examples:
YouTube use compression algorithms to store and deliver videos efficiently in less cost
Google Maps use routing finding algorithms to find the shortest possible route between point A and point B
Why to use algorithms?
To perform the task faster
To reduce cost by eliminating the unnecessary steps
Computer scientists have written an algorithm for a checker game, where the computer never lose.
What makes a good algorithm?
Correctness
Efficiency
Sometimes we need the algorithm to give us efficient but not necessarily the 100% accurate answer. For example, a truck needs to find a route between two locations, algorithm may take a lot of time to calculate the correct and the most efficient route. We will be okay for the program to calculate the good but maybe not the best route in the matter of seconds.
How to measure the efficiency?
Computer Scientists use Asymptotic Analysis to find out the efficiency of an algorithm.
Asymptotic analysis is a method used in mathematical analysis and computer science to describe the limiting behavior of functions, particularly focusing on the performance of algorithms. It helps in understanding how an algorithm’s resource requirements, such as time and space, grow as the input size increases.
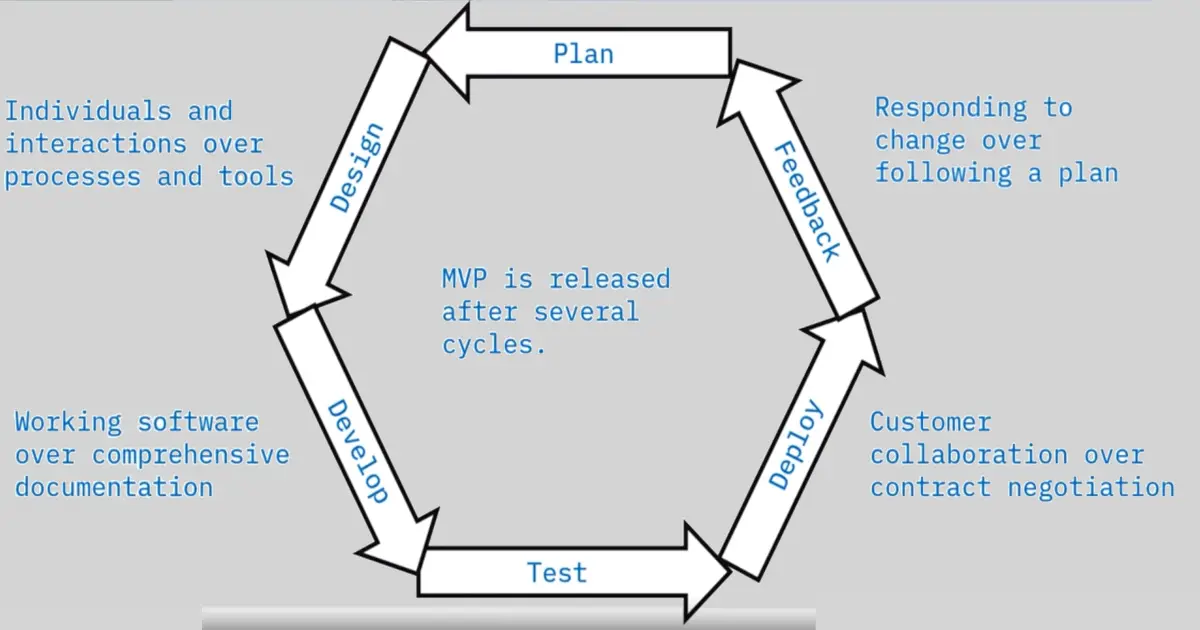
Guessing Game
If we have to guess the number between 1 and 15, how and every time we guess, we are told, if our guessed number is lower or higher the actual number.
We will start from either 1 to keep increasing one digit until we reach the correct number, or start from 15 and keep decreasing 1 until the guess is right.
The method we use here is called a linear search.
Linear search, also known as sequential search, is a simple searching algorithm used to find an element within a list. It sequentially checks each element of the list until it finds a match or reaches the end of the list.
— Wikipedia
This is the inefficient way of finding the right number. If computer has selection 15, we will need to 15 guesses to reach the correct digit. If we are lucky and computer has selected 1, we can reach it in a single guess.
Binary Search
Another approach we can use is by taking average before each. First guess will be 8, if the guess is lower, we can eliminate all the numbers before 8, if the guess is higher, we can eliminate all the numbers from 8 to 15 and so on.
This approach is called Halving method. And in computer terms, it’s called Binary Search.
Using this technique maximum number of guesses needed can be found:
$$
\text{Maximum number of guesses} = \log_{2}(n)
$$
Where n = Maximum Possible Guess
Binary search is a fast search algorithm used in computer science to find a specific element in a sorted array. It works on the principle of divide and conquer, reducing the search space by half with each step. The algorithm starts by comparing the target value with the middle element of the array. If the target value matches the middle element, the search is complete. If the target value is less or greater than the middle element, the search continues in the lower or upper half of the array, respectively. This process repeats until the target value is found, or the search space is exhausted.
— Wikipedia
Binary Search
Binary search is an algorithm for finding an item inside a sorted list. It finds it, by dividing the portion of the list in half repeatedly, which can possibly contain the item. The process goes on until the list is reduced to the last location.
Example
If we want to find a particular star in a Tycho-2 star catalog which contains information about the brightest 2,539,913 stars, in our galaxy.
Linear search would have to go through million of stars until the desired star is found. But through binary search algorithm, we can greatly reduce these guesses. For binary search to work, we need these start array to be sorted alphabetically.
Using this formula:
$$
\text{Maximum number of guesses} = \log_{2}(n)
$$
where n = 2,539,913
$$
\text{Maximum number of guessess} \approx 22
$$
So, using binary search, the number of guesses are reduced to merely 22, to reach the desired name of the star.
Describing Binary Search
When describing a computer algorithm to a fellow human, an incomplete description is often good enough. While describing a recipe, some details are intentionally left out, considering the reader/listener knows that anyway. For example, for a cake recipe, we don’t need to tell how to open a refrigerator to get ingredients out, or how to crack an egg. People might know to fill in the missing pieces, but the computer doesn’t. That’s why while giving instructions, we need to tell everything.
You need to provide answers to the following questions while writing an algorithm for a computer:
Inputs of the problem?
The outputs?
What variables to create?
Intermediary steps to reach the output?
For repeated instructions, how to make use of loops?
Here is the step-by-step guide of using binary search to play the guessing game:
Let min = 1 and max = n.
Guess the avg of max and min, rounded it, so that it’s an integer.
If your guess is right, stop.
If the guess is too low, set min to be one larger than the guess.
If the guess was too high, set max to be one smaller than the guess.
Repeat the step-2.
Implementing binary search of an array
JavaScript and many other programming languages, already provide a way to find out if a given element is in the array or not. But to understand the logic behind it, we need to implement it ourselves.
Let’s suppose we want to know if 67 is a prime number or not. If 67 is in the array, then it’s a prime.
We might also want to know how many primes are smaller than 67, we can do this by finding its index (position) in the array.
The position of an element in an array is known as its index.
Using binary search, $\text min = 2 , max = 97, guess = 41$
As $[ 41 < 67 ]$ so the elements less 41 would be discarded, and now
The next guess would be:
The binary search algorithm will stop here, as it has reached correct integer.
The binary search took only 2 guesses instead of 19 for linear search, to reach the right answer.
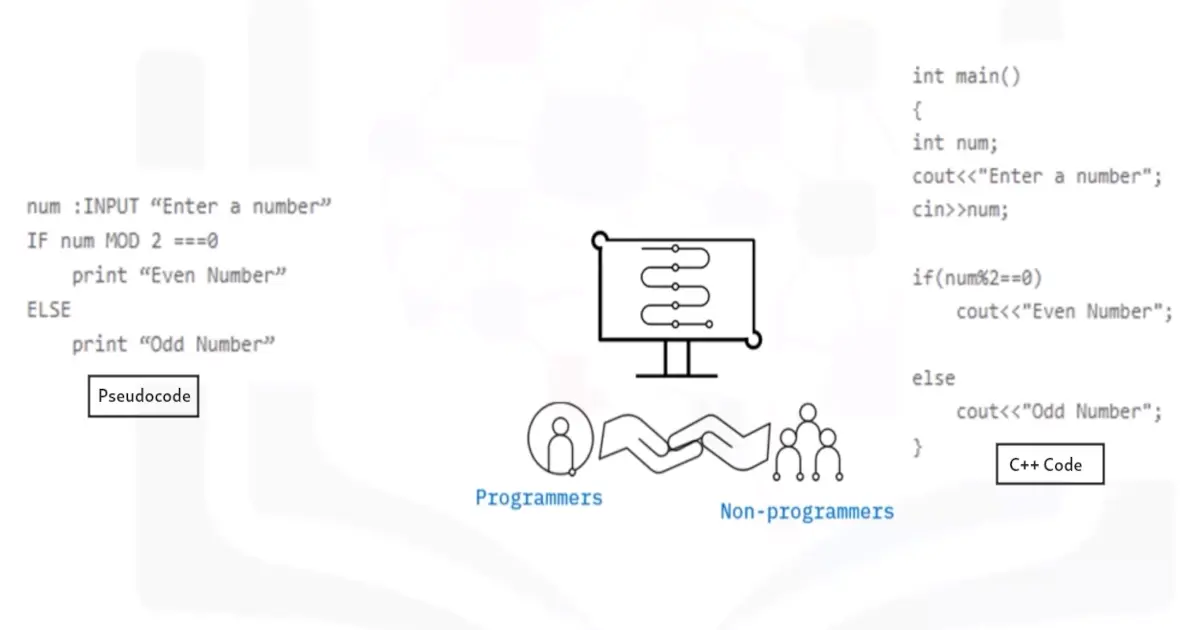
Pseudocode
Here’s the pseudocode for binary search, modified for searching in an array. The inputs are the array, which we call array; the number n of elements in array; and target, the number being searched for. The output is the index in array of target:
Let min = 0 and max = n-1.
Compute guess as the average of max and min, rounded down (so that it is an integer).
If array[guess] equals target, then stop. You found it! Return guess.
If the guess was too low, that is, array[guess] < target, then set min = guess + 1.
Otherwise, the guess was too high. Set max = guess - 1.
Go back to step 2.
Implementing Pseudocode
To turn pseudocode intro a program, we should create a function, as we’re writing a code that accepts an input and returns an output, and we want that code to be reusable for different inputs.
Then let’s go into the body of the function, and decide how to implement that. Step-6 says go back to step-2. That sound like a loop. Both for and while loops can be used here. But due to non-sequential guessing of the indexes, while loop will be more suitable.
Let min = 0 and max = n-1.
If max < min, then stop: target is not present in array. Return -1.
Compute guess as the average of max and min, rounded down (so that it is an integer).
If array[guess] equals target, then stop. You found it! Return guess.
If the guess was too low, that is, array[guess] < target, then set min = guess + 1.
Otherwise, the guess was too high. Set max = guess - 1.
Go back to step-2.
Challenge
Implementing binary search...
(If you don’t know JavaScript, you can skip the code challenges, or you can do the Intro to JS course and come back to them.)
Complete the doSearch function so that it implements a binary search, following the pseudo-code below (this pseudo-code was described in the previous article):
Let min = 0 and max = n-1.
If max < min, then stop: target is not present in array. Return -1.
Compute guess as the average of max and min, rounded down (so that it is an integer).
If array[guess] equals target, then stop. You found it! Return guess.
If the guess was too low, that is, array[guess] < target, then set min = guess + 1.
Otherwise, the guess was too high. Set max = guess - 1.
Go back to step 2.
Once implemented, uncomment the Program.assertEqual() statement at the bottom to verify that the test assertion passes.
TBD
Running time of binary search
Linear search on an array of n elements might have to make as many as n guesses. We know, binary search need a lot less guesses. We also learned that as the length of an array increases, the efficiency of binary search goes up.
The idea is, when binary search makes an incorrect guess, number of reasonable guess left, are at least cut half. Binary search halves the size of the reasonable portion upon every incorrect guess.
Every time we double the size of an array, we require at most one more guess.
Let’s look at the general case of an array of length n, We can express the number of guesses, in the worst case, as “the number of time we can repeatedly halve, starting at n, until we get the value 1, plus one.” But this is inconvenient to write out.
Luckily, there’s a mathematical function that means the same thing as the base-2 logarithm of n. That’s the most often written as $\log_{2}(n)$.
n
$\log_{2}(n)$
1
0
2
1
4
2
8
3
16
4
32
5
64
6
128
7
256
8
512
9
1024
10
1,048,576
20
2,097,152
21
Graph of the same table:
Zooming in on smaller values of n:
The logarithm function grows very slowly. Logarithms are the inverse of exponentials, which grow very rapidly, so that if $\log_{2}(n) = x$, then $\ n = 2^{x}$. For example, $\ log_2 128 = 7$, we know that $\ 2^7 = 128$.
That makes it easy to calculate the runtime of a binary search algorithm on an $n$ that’s exactly a power of $2$. If $n$ is $128$, binary search will require at most $8 (log_2 128 + 1)$ guesses.
What if $n$ isn’t a power of $2$? In that case, we can look at the closest lower power of $2$. For an array whose length is 1000, the closest lower power of $2$ is $512$, which equals $2^9$. We can thus estimate that $log_2 1000$ is a number greater than $9$ and less than $10$, or use a calculator to see that its about $9.97$. Adding one to that yields about $10.97$. In the case of a decimal number, we round down to find the actual number of guesses. Therefore, for a 1000-element array, binary search would require at most 10 guesses.
For the Tycho-2 star catalog with 2,539,913 stars, the closest lower power of 2 is $2^{21}$ (which is 2,097,152), so we would need at most 22 guesses. Much better than linear search!
Compare $n$ vs $log_{2} {n}$ below:
Asymptotic Notation
So far, we analyzed linear search and binary search by counting the max number of guesses we need to make. But what we really want to know is how long these algorithms take. We are interested in time not just guesses. The running time of both include the time needed to make and check guesses.
The running time an algorithm depends on:
The time it takes to run the lines of code by the computer
Speed of computer
programming language
The compiler that translates program into machine code
Let’s think more carefully about the running time. We can use a combination of two ideas.
First, we need to determine how long the algorithm takes, in terms of the size of its input. This idea makes intuitive sense, doesn’t it? We’ve already seen that the maximum number of guesses in linear search and binary search increases as the length of the array increases. Or think about a GPS. If it knew about only the interstate highway system, and not about every little road, it should be able to find routes more quickly, right? So we think about the running time of the algorithm as a function of the size of its input.
Second, we must focus on how fast a function grows with the input size. We call this the rate of growth of the running time. To keep things simple, we need to distill the most important part and cast aside the less important parts. For example, suppose that an algorithm, running on an input of size $n$, takes $6n^2+100n+300$ machine instructions. The $6n^2$ term becomes larger than the remaining terms, $100n+300$, once $n$ becomes large enough, $20$ in this case. Here’s a chart showing values of $6n^2$ and $100n+300$ for values of $n$ from $0$ to $100$:
We should say that running time of this algorithm grows as $n^2$, dropping the coefficient 6 and the remaining terms $100n+300$. It doesn’t really matter what coefficients we use; as long as the running time is $an^2+bn+c$, for some numbers a > 0, b, and c, there will always be a value of $n$ for which $an^2$ is greater than $bn+c$, and this difference increases as $n$ increases. For example, here’s a chart showing values of $0.6n^2$ and $1000n+3000$ so that we’ve reduced the coefficient of $n^2$ by a factor of 10 and increased the other two constants by a factor of 10:
The value of $n$ at which $0.6n^2$ becomes greater than $1000n+3000$ has increased, but there will always be such a crossover point, no matter what the constants.
By dropping the less significant terms and the constant coefficients, we can focus on the important part of an algorithm’s running time—its rate of growth—without getting mired in details that complicate our understanding. When we drop the constant coefficients and the less significant terms, we use asymptotic notation. We’ll see three forms of it: big-$\Theta$ (theta) notation, big-O notation, and big-$\Omega$ (omega) notation.
TBD
CS50’s Introduction to Programming with Python
This course is offered by Harvard University, with David J. Malan as an instructor.
Subsections of Automate the Boring Stuff with Python
Section 1: Python Basics
Everyone in their life, spent a lot of time on repetitive tasks, which can be automated through a simple script.
Automate the boring stuff with Python uses Python 3.
How to get help?
Being stuck while coding is a normal happening, but not asking for help isn’t.
When you go online to ask for help, make sure:
Explain what you are trying to do, not just what you did.
If you get an error message, specify the point at which the error happens.
Copy and paste the entire body of the error message and your code to a Pastebin site like Pastebin.com or GitHub Gist.
Explain what you’ve already tried to do to solve your problem.
List the version of Python you’re using.
Say whether you’re able to reproduce the error every time you run the program or whether it happens only after you perform certain actions. If the latter, then explain what those actions are.
Specify what Operating System you’re on, what version of that OS you’re using.
Basic Terminology and using an IDLE
IDLE stands for Integrated Development and Learning Environment.
There are different programming text editors available:
Visual Studio Code
Sublime Text
PyCharm
Expressions = Values + Operators
In python, these expressions always evaluate to a single result. Arithmetic Operators are:
Operator
Operation
Example
Evaluates to . . .
**
Exponent
2 ** 3
8
%
Modulus/remainder
22 % 8
6
//
Integer division/floored quotient
22 // 8
2
/
Division
22 / 8
2.75
*
Multiplication
3 * 5
15
-
Subtraction
5 - 2
3
+
Addition
2 + 2
4
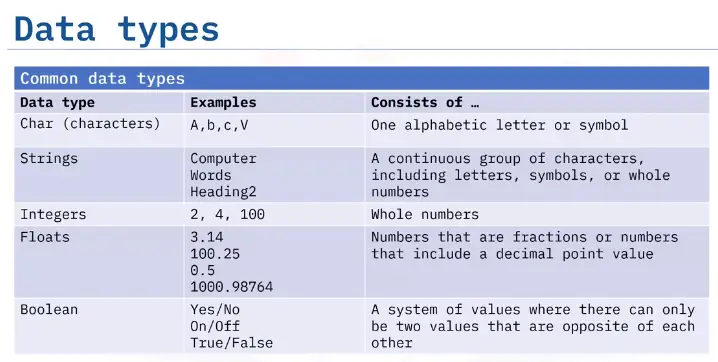
Data Types
Integers — “ints” (1,2,3…)
Floating point — “floats” (1.0, 1.1…)
Strings (“Hello World”)
Strings Concatenation: When two strings are joined together using a + symbol. (“Hello " + “World”)
String Replication: A string can be replicated by using * operator. (3 * “Hello World!”)
Both These operations can be combined like this "Hello World" + "!" * 5
Both concatenation and replication accepts strings values only.
Variables
Variable can store different values, like a box:
spam = 42
A too generic name given to a variable is a bad practice, which can create headache down the line while interacting with your code.
If a python instruction evaluates to a single value, it’s called an expression.
If it doesn’t evaluate to a single value, it’s called a statement.
We can update the variable value by calling it down the line in the program:
Just like the box, we can remove the old item with the new one.
Variable Names
You can name your variable anything, but Python does have some restrictions too:
It can be only one word with no spaces.
It can use only letters, numbers, and the underscores (_) character.
It can’t begin with a number.
Var names are case-sensitive too.
Though Spam is a valid var, but it is a Python convention to start var name with a lowercase letter.
camelCase for variables can be used though Python PEP8 style guide instead recommends the use of underscores like this camel_case.
Though PEP8 guide itself says:
Consistency with the style guide is important. But most importantly: know when to be inconsistent—sometimes the style guide just doesn’t apply. When in doubt, use your best judgment.
Writing Our First Program
Python ignore comments starting with #.
It also skips the blank lines.
Functions — They are like mini-programs in Python.
print("Hello World!")# Ask for their nameyourName=input("Type your name: ")print("It is good to meet you, "+str(yourName))print("Your name length is: "+str(len(yourName)))# Ask for their ageprint("What is your age?")yourAge=input("Type your age: ")print("You will be "+str(int(yourAge)+1)+" in a year.")
len(): It prints out the total number of characters in a string.
input() function always returns a string value, so you may have to convert it according to your need to float(), int() etc.
You can not concatenate str() and int() together, you will need to convert int() to str(int()), to concatenate them.
hello.py Evaluation steps look like this:
Extras (BOOK)
Python round(number, ndigits=None) Function
Return number rounded to ndigits precision after the decimal point. If ndigits is omitted or is None, it returns the nearest integer to its input.
The behavior of round() for floats can be surprising: for example, round(2.675, 2) gives 2.67 instead of the expected 2.68. This is not a bug: it’s a result of the fact that most decimal fractions can’t be represented exactly as a float. See Floating-Point Arithmetic: Issues and Limitations for more information.
Section 2: Flow Control
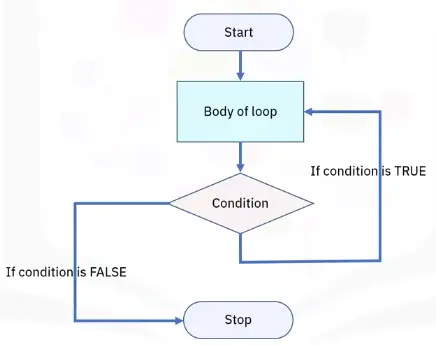
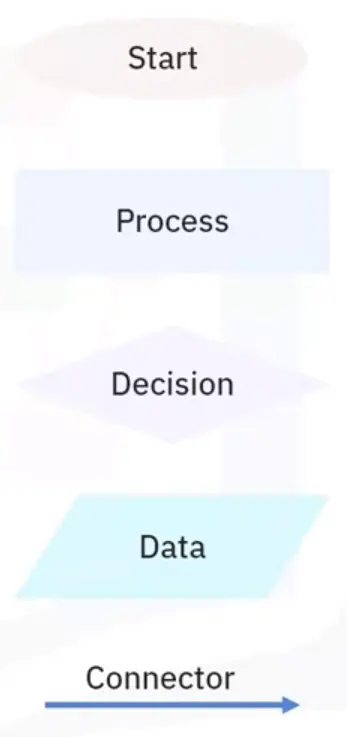
Flow Charts and Basic Flow Control Concepts
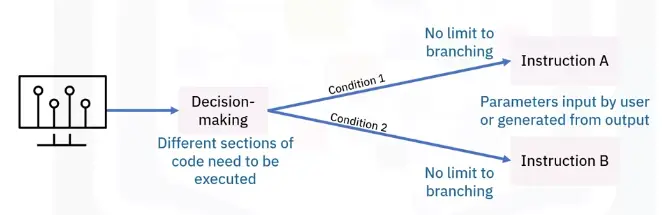
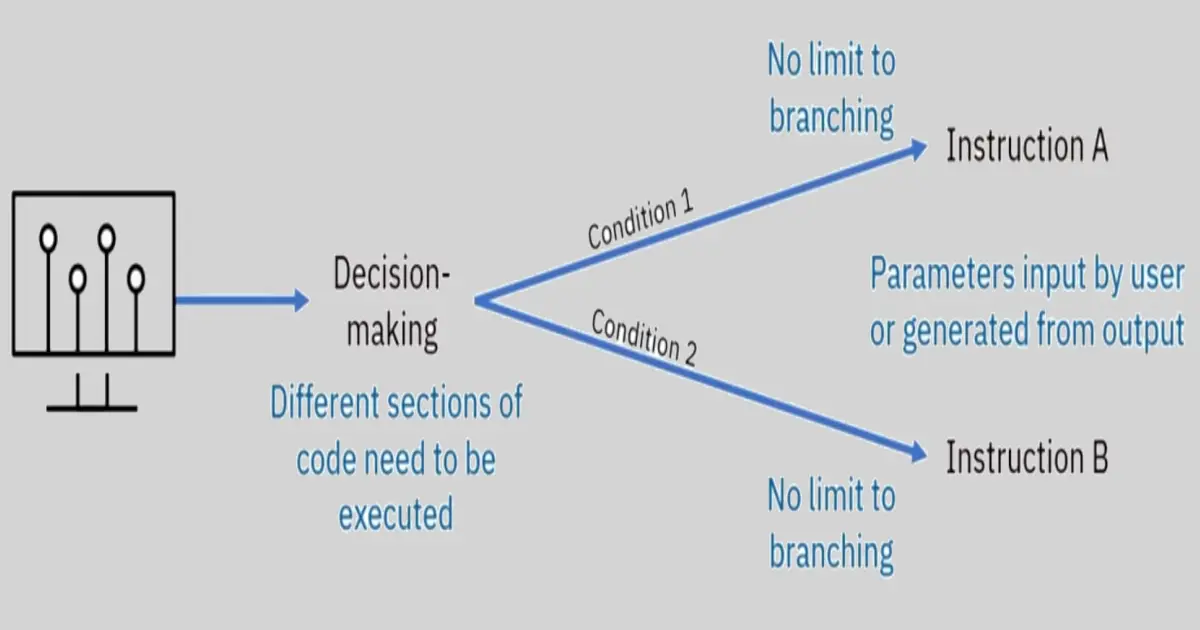
A flowchart starts at the start box, and you follow the arrow at the other boxes until you reach the end box. You take a different path depending on the conditions.
Based on how expression evaluate, a program can decide to skip instructions, repeat them, or choose one of several instructions to run. In fact, you almost never want your programs to start from the first line of ode and simply execute every line, straight to the end.
Flow control statements can decide which Python instructions to execute under which conditions.
These flow control statements directly correspond to the symbols in a flowchart.
In a flowchart, there is usually more than one way to go from the start to the end. The same is true for lines of code in a computer program. Flowcharts represent these branching points with diamonds, while the other steps are represented with rectangles. The starting and ending steps are represented with rounded rectangles.
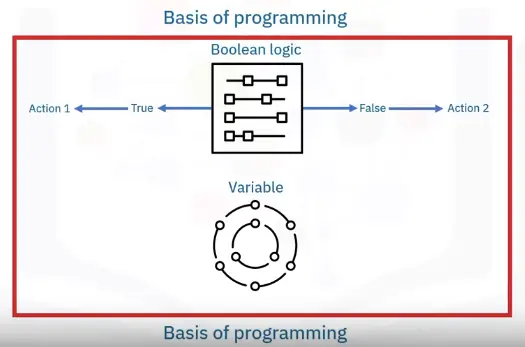
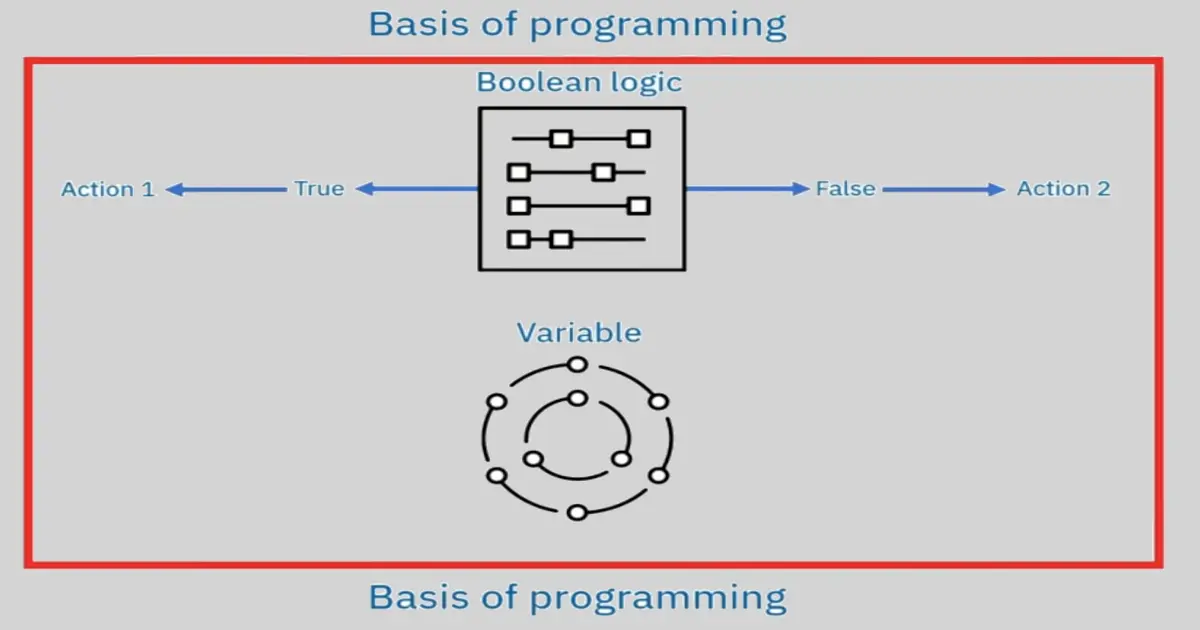
Boolean Values
Boolean Data Type has only to values True and False.
How to represent YES and NO values:
Boolean Values
Comparison Operators
Boolean Operators
When entered as Python code, the Boolean always starts with a capital T or F, with the rest of the word in lowercase.
(Boolean is capitalized because the data type is named after mathematician George Boole)
➊>>>spam=True>>>spamTrue➋>>>trueTraceback(mostrecentcalllast):File"<pyshell#2>",line1,in<module>trueNameError:name'true'isnotdefined➌>>>True=2+2SyntaxError:can't assign to keyword
Like any other value, Boolean values are used in expressions and can be stored in variables ➊. If you don’t use the proper case ➋ or you try to use True and False for variable names ➌, Python will give you an error message.
Comparison Operators
They also called relational operators, compare two values and evaluate down to a single Boolean value.
Operator
Meaning
==
Equal to
!=
Not equal to
<
Less than
>
Greater than
<=
Less than or equal to
>=
Greater than or equal to
These operators evaluate to True or False depending on the values you give them.
The == and != operators can actually work with values of any data type.
An integer or floating point value will always be unequal to a string value. There 42 == '42'➊ evaluates to False because Python considers the integer 42 to be different from the string '42'.
The <, >, <=, and >= operators, on the other hand, work properly only with integer and floating-point values.
Boolean Operators
The three Boolean operators (and, or, and not) are used to compare Boolean values. Like comparison operators, they evaluate these expressions down to a Boolean value.
Binary Boolean Operators
The and and or operators always take two Boolean values (or expressions), so they’re considered binary operators.
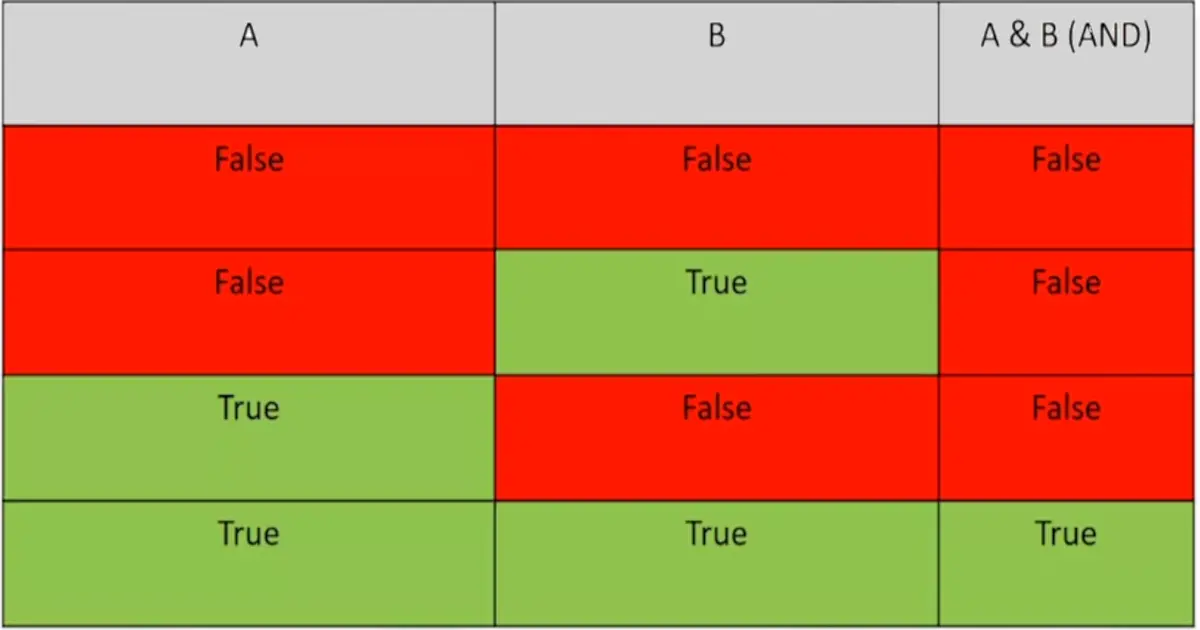
and Operator: It evaluates to True only if both Boolean values are True.
Expression
Evaluates to…
True and True
True
True and False
False
False and True
False
False and False
False
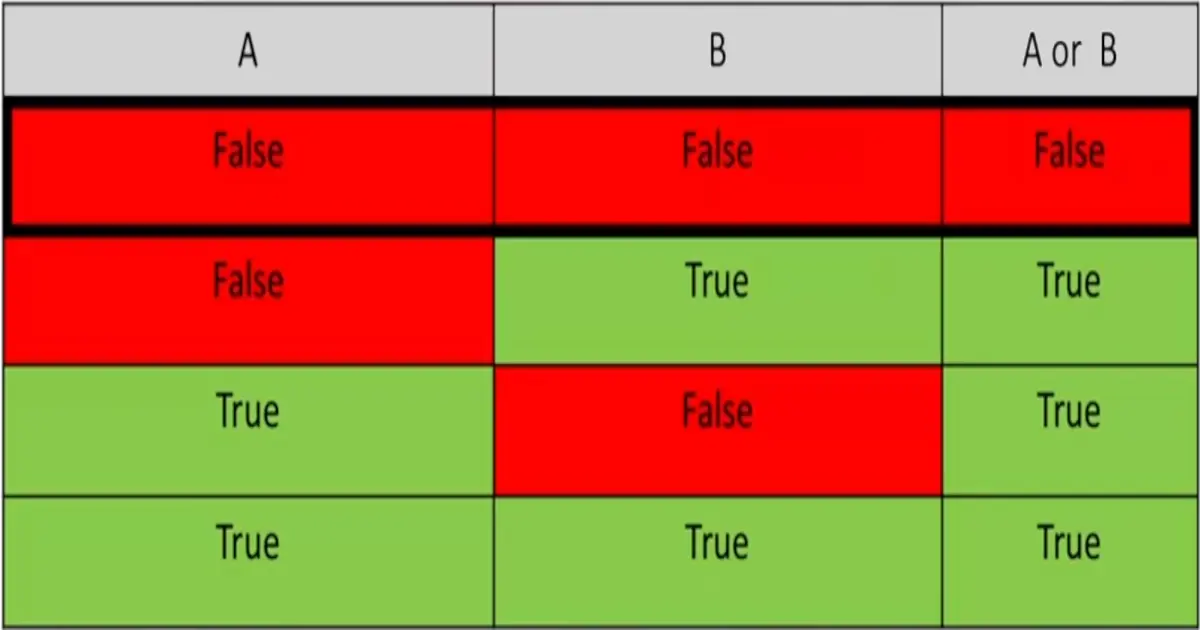
or Operator: It evaluates to True if one of the Boolean values is True.
Expression
Evaluates to…
True or True
True
True or False
True
False or True
True
False or False
False
The not Operator
It has only one Boolean value (or expression)
Expression
Evaluates to…
not True
False
not False
True
Mixing Boolean and Comparison Operators
Since the comparison operators evaluate to Boolean values, you can use them in expressions with the Boolean operators.
You can also use multiple Boolean operators in an expression, along with the comparison operators:
>>>2+2==4andnot2+2==5and2*2==2+2True
The Boolean operators have an order of operations just like the math operators do. After any math and comparison operators evaluate, Python evaluates the not operators first, then the and operators, and then the or operators.
Elements of Flow Control
Flow control statements often start with a part called the condition and are always followed by a block of code called the clause.
Conditions
The Boolean expressions you’ve seen so far could all be considered conditions, which are the same thing as expressions; condition is just a more specific name in the context of flow control statements.
Conditions always evaluate down to a Boolean value, True or False. A flow control statement decides what to do based on whether its condition is True or False, and almost every flow control statement uses a condition.
Blocks of Code
Lines of Python code can be grouped together in blocks.
There are 3 rules for block:
Blocks begin when the indentation increases.
Blocks can contain other blocks.
Blocks end when the indentation decreases to zero or to a containing block’s indentation.
You can view the execution of this program at https://autbor.com/blocks/. The first block of code ➊ starts at the line print(‘Hello, Mary’) and contains all the lines after it. Inside this block is another block ➋, which has only a single line in it: print(‘Access Granted.’). The third block ➌ is also one line long: print(‘Wrong password.’).
If, Else, and Elif Statements
The statements represent the diamonds in the flowchart. They are the actual decisions your programs will make.
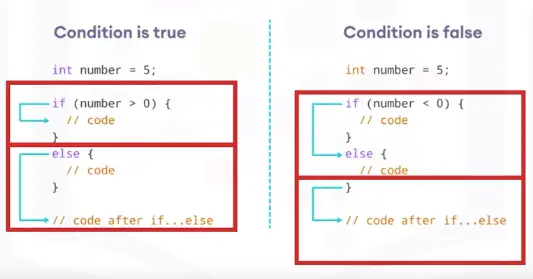
if Statements
If this condition is true, execute the code in the clause. if statement, consists of the following:
The if keyword
A condition (that is, an expression that evaluates to True or False)
A colon
Starting on the next line, an indented block of code (called the if clause)
else Statements
An if clause can optionally be followed by an else statement. The else clause is executed only when the if statement’s condition is False.
An else statement doesn’t have a condition. In code, an else statement always consists of the following:
The else keyword
A colon
Starting on the next line, an indented block of code (called the else clause)
elif Statements
While only one of the if or else clauses will execute, you may have a case where you want one of many possible clauses to execute.
The elif statement is an “else if” statement that always follows an if or another elif statement. It provides another condition that is checked only if all the previous conditions were False.
In code, an elif statement always consists of the following:
The elif keyword
A condition (that is, an expression that evaluates to True or False)
A colon
Starting on the next line, an indented block of code (called the elif clause)
ifname=='Alice':print('Hi, Alice.')elifage<12:print('You are not Alice, kiddo.')
The elif clause executes if age < 12 is True and name == 'Alice' is False. However, if both of the conditions are False, then both of the clauses are skipped. It is not guaranteed that at least one of the clauses will be executed. When there is a chain of elif statements, only one or none of the clauses will be executed. Once one of the statements’ conditions is found to be True, the rest of the elif clauses are automatically skipped.
name='Carol'age=3000ifname=='Alice':print('Hi, Alice.')elifage<12:print('You are not Alice, kiddo.')elifage>2000:print('Unlike you, Alice is not an undead, immortal vampire.')elifage>100:print('You are not Alice, grannie.')
The program vampire.py has 3 elif statements. If any of the three, is found True program execution will stop.
The order of elif statements is also important.
Optionally, you can have an else statement after the last elif statement. In that case, it is guaranteed that at least one (and only one) of the clauses will be executed. If the conditions in every if and elif statement are False, then the else clause is executed.
For example, let’s re-create the Alice program to use if, elif, and else clauses.
age=3000ifname=='Alice':print('Hi, Alice.')elifage<12:print('You are not Alice, kiddo.')else:print('You are neither Alice nor a little kid.')
When you use if, elif, and else statements together, remember these rules about how to order them to avoid bugs like the one in Figure 2.7. First, there is always exactly one if statement. Any elif statements you need should follow the if statement. Second, if you want to be sure that at least one clause is executed, close the structure with an else statement.
name='Carol'age=3000ifname=='Alice':print('Hi, Alice.')elifage<12:print('You are not Alice, kiddo.')elifage>100:print('You are not Alice, grannie.')elifage>2000:print('Unlike you, Alice is not an undead, immortal vampire.')
Figure 2-7: The flowchart for the vampire2.py program. The X path will logically never happen, because if age were greater than 2000, it would have already been greater than 100.
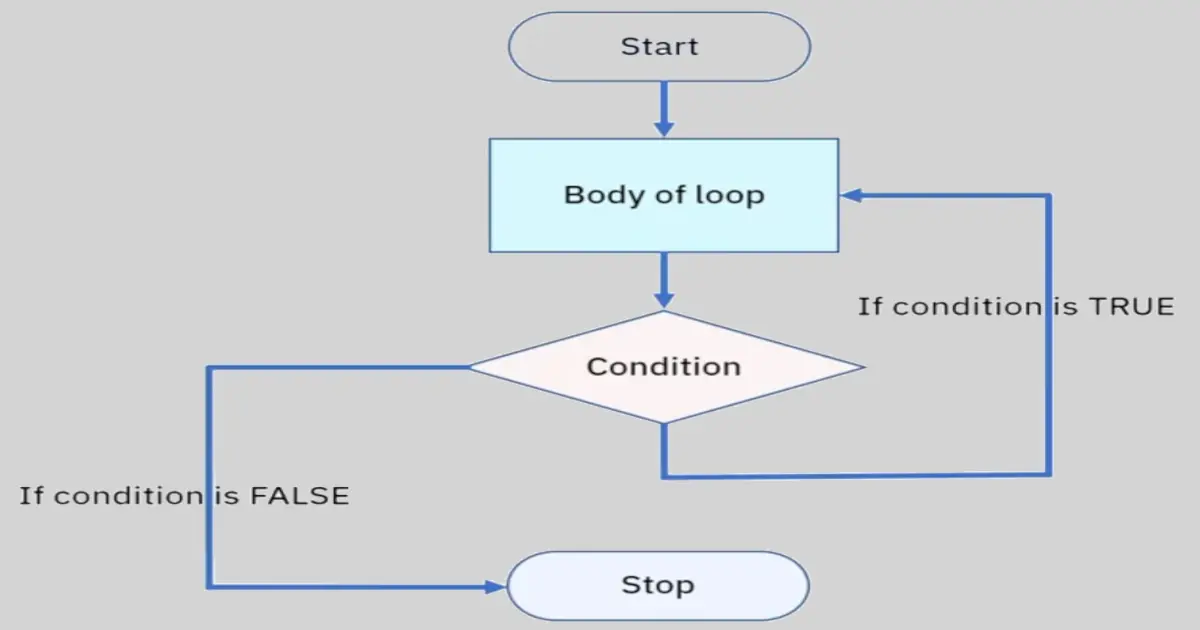
While Loops
The while statement always consists of the following:
The while keyword
A condition (that is, an expression that evaluates to True or False)
A colon
Starting on the next line, an indented block of code (called the whileclause)
You can see that a while statement looks similar to an if statement. The difference is in how they behave. At the end of an ifclause, the program execution continues after the if statement. But at the end of a whileclause, the program execution jumps back to the start of the while statement. The while clause is often called the while loop or just the loop.
Here is the code, which will keep asking your name until you literally type your name in the prompt:
name=""whilename!='your name':print("Please type your name.")name=input()print("Thank you!")
break Statements
If the execution reaches a break statement, it immediately exits the while loop’s clause.
➊whileTrue:print('Please type your name.')➋name=input()➌ifname=='your name':➍break➎print('Thank you!')
The first line ➊ creates an infinite loop; it is a while loop whose condition is always True. (The expression True, after all, always evaluates down to the value True.) After the program execution enters this loop, it will exit the loop only when a break statement is executed. (An infinite loop that never exits is a common programming bug.)
Just like before, this program asks the user to enter your name ➋. Now, however, while the execution is still inside the while loop, an if statement checks ➌ whether name is equal to ‘your name’. If this condition is True, the break statement is run ➍, and the execution moves out of the loop to print(‘Thank you!’) ➎. Otherwise, the if statement’s clause that contains the break statement is skipped, which puts the execution at the end of the while loop. At this point, the program execution jumps back to the start of the while statement ➊ to recheck the condition.
continue Statements
continue Statements are used inside loops
When the program execution reaches a continue statement, the program execution immediately jumps back to the start of the loop and re-evaluates the loop’s condition (This is also what happens when the execution reaches the end of the loop).
whileTrue:print('Who are you?')name=input()➊ifname!='Joe':➋continueprint('Hello, Joe. What is the password? (It is a fish.)')➌password=input()ifpassword=='swordfish':➍break➎print('Access granted.')
If the user enters any name besides Joe ➊, the continue statement ➋ causes the program execution to jump back to the start of the loop. When the program reevaluates the condition, the execution will always enter the loop, since the condition is simply the value True. Once the user makes it past that if statement, they are asked for a password ➌. If the password entered is swordfish, then the break statement ➍ is run, and the execution jumps out of the while loop to print Access granted ➎. Otherwise, the execution continues to the end of the while loop, where it then jumps back to the start of the loop.
Truthy and Fasely Values
Conditions will consider some values in other data types equivalent to True and False. When used in conditions, 0, 0.0, and ’’ (the empty string) are considered False, while all other values are considered True. For example, look at the following program:
name=''# `not` is a Boolean operator which flips the `True` or `False` values➊whilenotname:print('Enter your name:')name=input()print('How many guests will you have?')numOfGuests=int(input())➋ifnumOfGuests:➌print('Be sure to have enough room for all your guests.')print('Done')
If the user enters a blank string for name, then the while statement’s condition will be True ➊, and the program continues to ask for a name. If the value for numOfGuests is not 0 ➋, then the condition is considered to be True, and the program will print a reminder for the user ➌.
You could have entered not name != ’’ instead of not name, and numOfGuests != 0 instead of numOfGuests, but using the truthy and falsey values can make your code easier to read.
For Loops
The while loop keeps looping while its condition is True (which is the reason for its name), but what if you want to execute a block of code only a certain number of times? You can do this with a for loop statement and the range() function.
In code, a for statement looks something like for i in range(5): and includes the following:
The for keyword
A variable name
The in keyword
A call to the range() method with up to three integers passed to it
A colon
Starting on the next line, an indented block of code (called the for clause)
print("My name is")foriinrange(5):print("Alex Five Times ("+str(i)+")")
The code in the for loop’s clause is run five times. The first time it is run, the variable i is set to 0. The print() call in the clause will print Jimmy Five Times (0). After Python finishes an iteration through all the code inside the for loop’s clause, the execution goes back to the top of the loop, and the for statement increments i by one. This is why range(5) results in five iterations through the clause, with i being set to 0, then 1, then 2, then 3, and then 4. The variable i will go up to, but will not include, the integer passed to range().
NOTE
You can use break and continue statements inside for loops as well. The continue statement will continue to the next value of the for loop’s counter, as if the program execution had reached the end of the loop and returned to the start. In fact, you can use continue and break statements only inside while and for loops. If you try to use these statements elsewhere, Python will give you an error.
Counting the sums of all the numbers to 100 using both for and while loops:
# For Loop to Count the sums of numbers upto 100sum=0foriinrange(101):sum=sum+i# print(sum, i)print("The sum of 100 using for loop is: ",sum)# While Loop#sum=0i=0whilei<101:sum=sum+ii=i+1print("The sum of 100 using while loop is: ",sum)
The use of for is more efficient though while can also get the job done.
The Starting, Stopping, and Stepping Arguments to range()
Some functions can be called with multiple arguments separated by a comma, and range() is one of them. This lets you change the integer passed to range() to follow any sequence of integers, including starting at a number other than zero.
foriinrange(12,16):print(i)
The first argument will be where the for loop’s variable starts, and the second argument will be up to, but not including, the number to stop at.
12
13
14
15
The range() function can also be called with three arguments. The first two arguments will be the start and stop values, and the third will be the step argument. The step is the amount that the variable is increased by after each iteration.
foriinrange(0,10,2):print(i)
So calling range(0, 10, 2) will count from zero to eight by intervals of two.
0
2
4
6
8
The range() function is flexible in the sequence of numbers it produces for for loops. You can even use a negative number for the step argument to make the for loop count down instead of up.
foriinrange(5,-1,-1):print(i)
This for loop would have the following output:
5
4
3
2
1
0
Running a for loop to print i with range(5, -1, -1) should print from five down to zero.
Importing Modules
All Python programs can call a basic set of functions called built-in functions, including the print(), input(), and len() functions you’ve seen before.
Python also comes with a set of modules called the standard library.
Each module is a Python program that contains a related group of functions that can be embedded in your programs. For example, the math module has mathematics-related functions, the random module has random number-related functions, and so on.
Before you can use the functions in a module, you must import the module with an import statement. In code, an import statement consists of the following:
The import keyword
The name of the module
Optionally, more module names, as long as they are separated by commas.
When you save your Python scripts, take care not to give them a name that is used by one of Python’s modules, such as random.py, sys.py, os.py, or math.py. If you accidentally name one of your programs, say, random.py, and use an import random statement in another program, your program would import your random.py file instead of Python’s random module. This can lead to errors such as AttributeError: module random has no attribute ‘randint’, since your random.py doesn’t have the functions that the real random module has. Don’t use the names of any built-in Python functions either, such as print() or input().
Problems like these are uncommon, but can be tricky to solve. As you gain more programming experience, you’ll become more aware of the standard names used by Python’s modules and functions, and will run into these issues less frequently.
Since randint() is in the random module, you must first type random. in front of the function name to tell Python to look for this function inside the random module.
from import Statements
An alternative form of the import statement is composed of the from keyword, followed by the module name, the import keyword, and a star; for example, from random import *.
With this form of import statement, calls to functions in random will not need the random. prefix. However, using the full name makes for more readable code, so it is better to use the import random form of the statement.
Ending a Program Early with the sys.exit() function
Programs always terminate if the program execution reaches the bottom of the instructions. However, you can cause the program to terminate, or exit, before the last instruction by calling the sys.exit() function.
Since this function is in the sys module, you have to import sys before you can use it.
importsyswhileTrue:print('Type exit to quit.')response=input()ifresponse=='exit':sys.exit()print('You typed '+"'"+response+"'"+'.')
Run this program in IDLE. This program has an infinite loop with no break statement inside. The only way this program will end is if the execution reaches the sys.exit() call. When response is equal to exit, the line containing the sys.exit() call is executed. Since the response variable is set by the input() function, the user must enter exit in order to stop the program.
A Short Program: Guess the Number
We have a pseudocode like this:
I am thinking of a number between 1 and 20.
Take a guess.
10
Your guess is too low.
Take a guess.
15
Your guess is too low.
Take a guess.
17
Your guess is too high.
Take a guess.
16
Good job! You guessed my number in 4 guesses!
I have implemented this code as:
fromrandomimportrandintsecretNumber=randint(1,20)# print(secretNumber) # Debuging purposes onlyprint("I am thinking of a number between 1 and 20.")guess=''numberOfGuesses=0whileguess!=secretNumber:guess=int(input("Take a Guess: "))numberOfGuesses=numberOfGuesses+1ifguess<secretNumber:print("Your Guess is too low.")elifguess>secretNumber:print("Your Guess is too high")print("Good job! You guessed my number in "+str(numberOfGuesses)+" guesses!")
This how Al implemented it…
# This is a guess the number game. importrandomsecretNumber=random.randint(1,20)print('I am thinking of a number between 1 and 20.')# Ask the player to guess 6 times. forguessesTakeninrange(1,7):print('Take a guess.')guess=int(input())ifguess<secretNumber:print('Your guess is too low.')elifguess>secretNumber:print('Your guess is too high.')else:break# This condition is the correct guess! ifguess==secretNumber:print('Good job! You guessed my number in '+str(guessesTaken)+' guesses!') else:print('Nope. The number I was thinking of was '+str(secretNumber))
Version 2.0 of my implementation of guessTheNumber2.py game…
fromrandomimportrandintsecretNumber=randint(1,20)# print(secretNumber) # Debuging purposes onlyprint("I am thinking of a number between 1 and 20.")# guess = ''numberOfGuesses=0whileTrue:guess=int(input("Take a Guess: "))numberOfGuesses=numberOfGuesses+1ifguess<secretNumber:print("Your Guess is too low.")elifguess>secretNumber:print("Your Guess is too high")else:breakprint("Good job! You guessed my number in "+str(numberOfGuesses)+" guesses!")
I’m still going with the unlimited number of guesses method, but improved the logic.
A Short Program: Rock, Paper, Scissors
We have the Pseudocode for the program:
ROCK, PAPER, SCISSORS
0 Wins, 0 Losses, 0 Ties
Enter your move: (r)ock (p)aper (s)cissors or (q)uit
p
PAPER versus...
PAPER
It is a tie!
0 Wins, 1 Losses, 1 Ties
Enter your move: (r)ock (p)aper (s)cissors or (q)uit
s
SCISSORS versus...
PAPER
You win!
1 Wins, 1 Losses, 1 Ties
Enter your move: (r)ock (p)aper (s)cissors or (q)uit
q
That’s how I implemented it:
################################################## RPS GAME VERSION 5.0 ####################################################importrandomimportsys# Print to the Screen Onceprint("ROCK, PAPER, SCISSORS")# Counting Streakswins=0losses=0ties=0whileTrue:# Print to the Screenprint("Enter your move: (r)ock (p)aper (s)cissors or (q)uit")# User InputuserMove=input()ifuserMove=="q":print(f"Thank you for playing our Game!\n{wins} Wins, {losses} losses, {ties} Ties")sys.exit()elifuserMove!="r"anduserMove!="p"anduserMove!="s":print("Illegal Guess, Try again.")continueelifuserMove=="r":userMove="ROCK"elifuserMove=="p":userMove="PAPER"elifuserMove=="s":userMove="SCISSORS"# System inputsystemMove=random.randint(1,3)ifsystemMove==1:systemMove="ROCK"elifsystemMove==2:systemMove="PAPER"elifsystemMove==3:systemMove="SCISSORS"# Showing the Played Movesprint(f"{systemMove} vs. {userMove}")# Game LogicifsystemMove==userMove:print("It is a tie")ties=ties+1elif((systemMove=="ROCK"anduserMove=="PAPER")or(systemMove=="SCISSORS"anduserMove=="ROCK")or(systemMove=="PAPER"anduserMove=="SCISSORS")):print("You win!")wins=wins+1elif((systemMove=="ROCK"anduserMove=="SCISSORS")or(systemMove=="PAPER"anduserMove=="ROCK")or(systemMove=="SCISSORS"anduserMove=="PAPER")):print("Loser!")losses=losses+1
Tip
Go to my GitHub to see other versions of the game, and how I went step by step, implementing the logic and cleaning the code. It still isn’t efficient or clean looking code, as we haven’t gotten to some advanced lessons, which can help us clean it up further.
This how Al implemented it…
importrandom,sysprint('ROCK, PAPER, SCISSORS')# These variables keep track of the number of wins, losses, and ties. wins=0losses=0ties=0whileTrue:# The main game loop. print('%s Wins, %s Losses, %s Ties'%(wins,losses,ties))whileTrue:# The player input loop. print('Enter your move: (r)ock (p)aper (s)cissors or (q)uit')playerMove=input()ifplayerMove=='q':sys.exit()# Quit the program. ifplayerMove=='r'orplayerMove=='p'orplayerMove=='s':break# Break out of the player input loop. print('Type one of r, p, s, or q.')# Display what the player chose: ifplayerMove=='r':print('ROCK versus...')elifplayerMove=='p':print('PAPER versus...')elifplayerMove=='s':print('SCISSORS versus...')# Display what the computer chose: randomNumber=random.randint(1,3)ifrandomNumber==1:computerMove='r'print('ROCK')elifrandomNumber==2:computerMove='p'print('PAPER')elifrandomNumber==3:computerMove='s'print('SCISSORS')# Display and record the win/loss/tie: ifplayerMove==computerMove:print('It is a tie!')ties=ties+1elifplayerMove=='r'andcomputerMove=='s':print('You win!')wins=wins+1elifplayerMove=='p'andcomputerMove=='r':print('You win!')wins=wins+1elifplayerMove=='s'andcomputerMove=='p':print('You win!')wins=wins+1elifplayerMove=='r'andcomputerMove=='p':print('You lose!')losses=losses+1elifplayerMove=='p'andcomputerMove=='s':print('You lose!')losses=losses+1elifplayerMove=='s'andcomputerMove=='r':print('You lose!')losses=losses+1
abs() Function (Extras)
The Python abs() function return the absolute value. The absolute value of any number is always positive it removes the negative sign of a number in Python.
>>>abs(-10)10>>>abs(-0.50)0.5>>>abs(-32.40)32.4
Section 3: Functions
Python provides several built-in functions like print(), input() and len(), but you can also write your own functions.
A function is like a mini-program within a program.
The first line is a def statement ➊, which defines a function named hello(). The code in the block that follows the def statement ➋ is the body of the function. This code is executed when the function is called, not when the function is first defined.
The hello() lines after the function ➌ are function calls. In code, a function call is just the function’s name followed by parentheses, possibly with some number of arguments in between the parentheses.
A major purpose of functions is to group code that gets executed multiple times. Without a function defined, you would have to copy and paste this code each time, and the program would look like this:
The definition of the hello() function in this program has a parameter called name ➊. Parameters are variables that contain arguments. When a function is called with arguments, the arguments are stored in the parameters. The first time the hello() function is called, it is passed the argument 'Alice' ➌. The program execution enters the function, and the parameter name is automatically set to 'Alice', which is what gets printed by the print() statement ➋.
The value stored in a parameter is forgotten when the function returns. For example, if you added print(name) after hello('Bob') in the previous program, the program would give a NameError because there is no variable named name.
Define, Call, Pass, Argument, Parameter
The terms define, call, pass, argument, and parameter can be confusing. Let’s look at a code example to review these terms:
To define a function is to create it, just like an assignment statement like spam = 42 creates the spam variable. The def statement defines the sayHello() function ➊.
The sayHello('Al') line ➋ calls the now-created function, sending the execution to the top of the function’s code. This function call is also known as passing the string value 'Al' to the function.
A value being passed to a function in a function call is an argument. The argument 'Al' is assigned to a local variable named name. Variables that have arguments assigned to them are parameters.
It’s easy to mix up these terms, but keeping them straight will ensure that you know precisely what the text in this chapter means.
Return Values and return Statements
Calling a len() function with an argument such as 'hello, will evaluate to the integer value 5, which is the length of the string passed.
The value that a function call evaluates to is called return value of the function.
While writing a function, return value should be used with return statement.
A return statement has:
The return keyword
The value or expression that the function should return.
When an expression is used with a return statement, the return value is what this expression evaluates to.
The None Value
In Python, there is a value called None, which represents the absence of a value(a placeholder). The None value is the only value of the NoneType data type.
Other programming languages might call this value null, nil, or undefined.
Just like the Boolean True and False values, None must be typed with a capital N.
This value-without-a-value can be helpful when you need to store something that won’t be confused for a real value in a variable.
One place where None is used is as the return value of print().
The print() function displays text on the screen, but it doesn’t need to return anything in the same way len() or input() does. But since all function calls need to evaluate to a return value, print() returns None. To see this in action, enter the following into the interactive shell:
>>>spam=print('Hello!')Hello!>>>None==spamTrue
Behind the scenes, Python adds return None to the end of any function definition with no return statement. This is similar to how a while or for loop implicitly ends with a continue statement. Also, if you use a return statement without a value (that is, just the return keyword by itself), then None is returned.
Keyword Arguments and the print() Function
Keyword arguments are often used for optional parameters. For example, the print() function has the optional parameters end and sep to specify what should be printed at the end of its arguments and between its arguments (separating them), respectively.
By default, two successive print statements would print their arguments on a separate line, but we can change this behavior with keyword arguments:
print('Hello',end=' ')print('World')
When different strings are concatenated, we can use:
print('Hello!'+'World',sep=':')
The Call Stack
Imagine that you have a meandering conversation with someone. You talk about your friend Alice, which then reminds you of a story about your coworker Bob, but first you have to explain something about your cousin Carol. You finish you story about Carol and go back to talking about Bob, and when you finish your story about Bob, you go back to talking about Alice. But then you are reminded about your brother David, so you tell a story about him, and then get back to finishing your original story about Alice. Your conversation followed a stack-like structure, like in Figure 3-1. The conversation is stack-like because the current topic is always at the top of the stack.
Similar to our meandering conversation, calling a function doesn’t send the execution on a one-way trip to the top of a function. Python will remember which line of code called the function so that the execution can return there when it encounters a return statement. If that original function called other functions, the execution would return to those function calls first, before returning from the original function call.
The call stack is how Python remembers where to return the execution after each function call.
The call stack isn’t stored in a variable in your program; rather, Python handles it behind the scenes.
When your program calls a function, Python creates a frame object on the top of the call stack. Frame objects store the line number of the original function call so that Python can remember where to return. If another function call is made, Python puts another frame object on the call stack above the other one.
When a function call returns, Python removes a frame object from the top of the stack and moves the execution to the line number stored in it. Note that frame objects are always added and removed from the top of the stack and not from any other place.
The top of the call stack is which function the execution is currently in. When the call stack is empty, the execution is on a line outside of all functions.
Local and Global Scope
Parameters and variables that are assigned in a called function are said to exit in that function’s local scope.
Variables that are assigned outside all functions are said to exist in the global scope.
A variable must be one or the other; it cannot be both local and global.
Think of a scope as a container for variables. When scope is destroyed, all variables stored inside it are forgotten.
There is only one global scope, and it is created when your program begins. When your program terminates, the global scope is destroyed, and all its variables are forgotten.
A local scope is created whenever a function is called. Any variables assigned in the function exist within the function’s local scope. When the function returns, the local scope is destroyed, and these variables are forgotten.
Scope matter because:
Code in the global scope, outside all functions, cannot use any local variables.
However, code in a local scope can access global variables.
defspam():print(eggs)eggs=42spam()print(eggs)
Code in a function’s local scope cannot use variables in any other local scope.
We can use the same name for different variables, if they are in different scopes.
It’s easy to track down a bug caused by a local variable. When there are thousands of lines of code, global variables are hard to work with.
Using global variables in small programs is fine, it’s a bad habit to rely on global variables as your programs get larger and larger.
The Global Statement
To modify a global variable from within a function, we can use a global statement.
If you have a line such as global eggs at the top of a function, it tells Python, “In this function, eggs refers to the global variable, so don’t create a local variable with this name.”
Because eggs is declared global at the top of spam() ➊, when eggs is set to 'spam' ➋, this assignment is done to the globally scoped eggs. No local eggs variable is created.
There are four rules to tell whether a variable is in a local scope or global scope:
If a variable is being used in the global scope (that is, outside all functions), then it is always a global variable.
If there is a global statement for that variable in a function, it is a global variable.
Otherwise, if the variable is used in an assignment statement in the function, it is a local variable.
But if the variable is not used in an assignment statement, it is a global variable.
Functions as Black Boxes…
Often, all you need to know about a function are its inputs (the parameters) and output value; you don’t always have to burden yourself with how the function’s code actually works. When you think about functions in this high-level way, it’s common to say that you’re treating a function as a “black box.”
This idea is fundamental to modern programming. Later chapters in this book will show you several modules with functions that were written by other people. While you can take a peek at the source code if you’re curious, you don’t need to know how these functions work in order to use them. And because writing functions without global variables is encouraged, you usually don’t have to worry about the function’s code interacting with the rest of your program.
Section 4: Handling Errors With Try/Except
Exception Handling
Getting an error or exception in Python program, without any exception handling means entire program will crash.
In real world, this is not the desired behavior, and we want our program to detect errors, handle them, and then continue to run.
When the program is run we will get ZeroDivisonError at line 6.
You can put the previous divide-by-zero code in a try clause and have an except clause contain code to handle what happens when this error occurs.
1
2
3
4
5
6
7
8
9
10
11
defspam(divideBy):try:return42/divideByexceptZeroDivisionError:return('Error: I cannot do that.')print(spam(2))print(spam(12))print(spam(0))print(spam(1))
When code in a try clause causes an error, the program execution immediately moves to the code in the except clause. After running that code, the execution continues as normal.
A Short Program: Zigzag
This program will create a back-and-forth, zigzag pattern until the user stops it by pressing the Mu editor’s Stop button or by pressing CTRL-C. When you run this program, the output will look something like this:
# An extra project from book's chapter 3importsysimporttimedefasterisks_pattern(startSpace,pattern):print(' '*startSpace+pattern)time.sleep(0.1)pattern='******'whileTrue:try:forstartSpaceinrange(10):asterisks_pattern(startSpace,pattern)forstartSpaceinrange(10,1,-1):asterisks_pattern(startSpace,pattern)exceptKeyboardInterrupt:print(' Quiting the animation pattern. Goodbye!')sys.exit()
Write a function named collatz() that has one parameter named number. If number is even, then collatz() should print number // 2 and return this value. If number is odd, then collatz() should print and return 3 * number + 1.
Then write a program that lets the user type in an integer and that keeps calling collatz() on that number until the function returns the value 1. (Amazingly enough, this sequence actually works for any integer—sooner or later, using this sequence, you’ll arrive at 1! Even mathematicians aren’t sure why. Your program is exploring what’s called the Collatz sequence, sometimes called “the simplest impossible math problem.”)
Remember to convert the return value from input() to an integer with the int() function; otherwise, it will be a string value.
Hint: An integer number is even if number % 2 == 0, and it’s odd if number % 2 == 1.
The output of this program could look something like this:
Enternumber:3105168421
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Extra Project from book's chapter 3defcollatz(number):ifnumber%2==0:result=int(number/2)else:result=int(3*number+1)print(result)returnresulttry:number=int(input("Enter your number:\n"))whilenumber!=1:number=collatz(number)exceptValueError:print('Please enter a valid integer')
Section 5: Writing a Complete Program, Guess the Number
A Guess Game
The output we need:
Hello, What is your name?
Al
Well, Al, I am thinking of a number between 1 and 20.
Take a guess.
10
Your guess is too low.
Take a guess
5
Your guess is too high.
Take a guess.
6
Good job, Al! You guessed my number in 5 guesses!
importrandom# Ask for Player name and greet themplayerName=input('Hello, What is your name?\n')print(f"Well, {playerName}, I am thinking of a number between 1 and 20.")secretNumber=random.randint(1,20)# print(f"Debug: Secret Number is {secretNumber}")fornumberOFGuessesinrange(1,7):# Max number of Guesses allowedplayerGuess=int(input('Take a Guess\n'))ifplayerGuess<secretNumber:print('Your Guess is too low.')elifplayerGuess>secretNumber:print('Your Guess is too high')else:breakifplayerGuess==secretNumber:print(f'Good job,{playerName}! You guessed my number in {numberOFGuesses} guesses!')else:print(f"Nope. The number I was thinking of was {secretNumber}.")
F-Strings
In this course we were taught about string concatenation using + operator. But that is cumbersome, and we need to convert non-strings values to strings values for concatenation to work.
In python 3.6, F-strings were introduced, that makes the strings concatenation a lot easier.
print(f"This is an example of {strings} concatenation.")
{} We can put our variable name, which will be automatically converted into string type. As you can see, this approach is much more cleaner.
A Guess Game — Extended Version
Let’s take everything we learned so far, write a guess game which has the following qualities:
An error checking
Asking player to choose the lower and higher end of number for guessing game.
Let player exit the game using sys.exit() module or pressing q(uit) button on their keyboard.
Using built-in function title() method, convert a string into title case, where the first letter of each word is capitalized, and the rest are in lowercase.
An extra feature which I want to implement is telling the player, how many guesses they will get. As taught in Algorithm: Binary Search course, offered by Khan Academy. We can calculate max number of guesses using this formula:
$$
\text{Maximum number of guesses} = \log_{2}(n) \
$$
For guess between (1, 20), the n = 20:
$$
\text{Maximum number of guesses} = \log_{2}(20)
$$
$$
\text{Maximum number of guessess} \approx 5
$$
Here is the extended version, I might have gone a bit over the board.
importrandomimportmathimportsysimporttimedefquitGame():# Message to print when CTRL+C keys are pressedprint('\nThanks for Playing, quiting the game...')sys.exit()# Greeting the Playertry:print('Welcome to Guess the Number Game. \nYou can Quit the game any time by pressing CTRL+C keys on your keyboard')playerName=input('Hello, What is your name?\n').title()print(f"Well, {playerName}, let's choose our start and end values for the game.")exceptKeyboardInterrupt:quitGame()# Asking Player for Guessing Range and Error CheckingwhileTrue:try:lowerEndOfGuess=int(input('Choose your start number: '))higherEndOfGuess=int(input('Choose your end number: '))iflowerEndOfGuess>higherEndOfGuess:# Otherwise our random function will failprint('Starting number should be less than ending number')continuebreakexceptValueError:print('Only Intergers are allowed as a start and end values of a Guessing Game.')exceptKeyboardInterrupt:quitGame()# Haing Fun and choosing the secret numbertry:print('Wait, a moment, I m gearing up for the battle.')time.sleep(2)print("Don't be stupid.I'm not stuck., I'm still thinking of what number to choose!")time.sleep(3)print('Dont dare to Quit on me')secretNumber=random.randint(lowerEndOfGuess,higherEndOfGuess)time.sleep(2.5)print('Shshhhhhhh! I have chosen my MAGIC NUMBER!')time.sleep(1.5)print("It's your turn")time.sleep(1.5)exceptKeyboardInterrupt:quitGame()# print(f"Debug: Secret Number is {secretNumber}")# Calculating maximum number of possible guessestotalGuesses=higherEndOfGuess-lowerEndOfGuessmaxPossibleGuesses=math.ceil(math.log2(totalGuesses))print(f"You have {maxPossibleGuesses} guesses to Win the Game.")time.sleep(1.5)# Game LogicfornumberOFGuessesinrange(1,maxPossibleGuesses+1):try:playerGuess=int(input('Take a Guess!\n'))ifplayerGuess<secretNumber:print('Your Guess is too low!')elifplayerGuess>secretNumber:print('Your Guess is too high!')else:breakexceptValueError:print('Only integers are allowed as valid game guess.')exceptKeyboardInterrupt:quitGame()# Ending the Gametry:ifplayerGuess==secretNumber:print(f'Good job,{playerName}! You guessed my number in {numberOFGuesses} guesses!')else:print(f"You lose! Number of guesses are exhausted. The number I was thinking of was {secretNumber}.")exceptNameError:print('Please, try again, something went wrong!')
Section 6: Lists
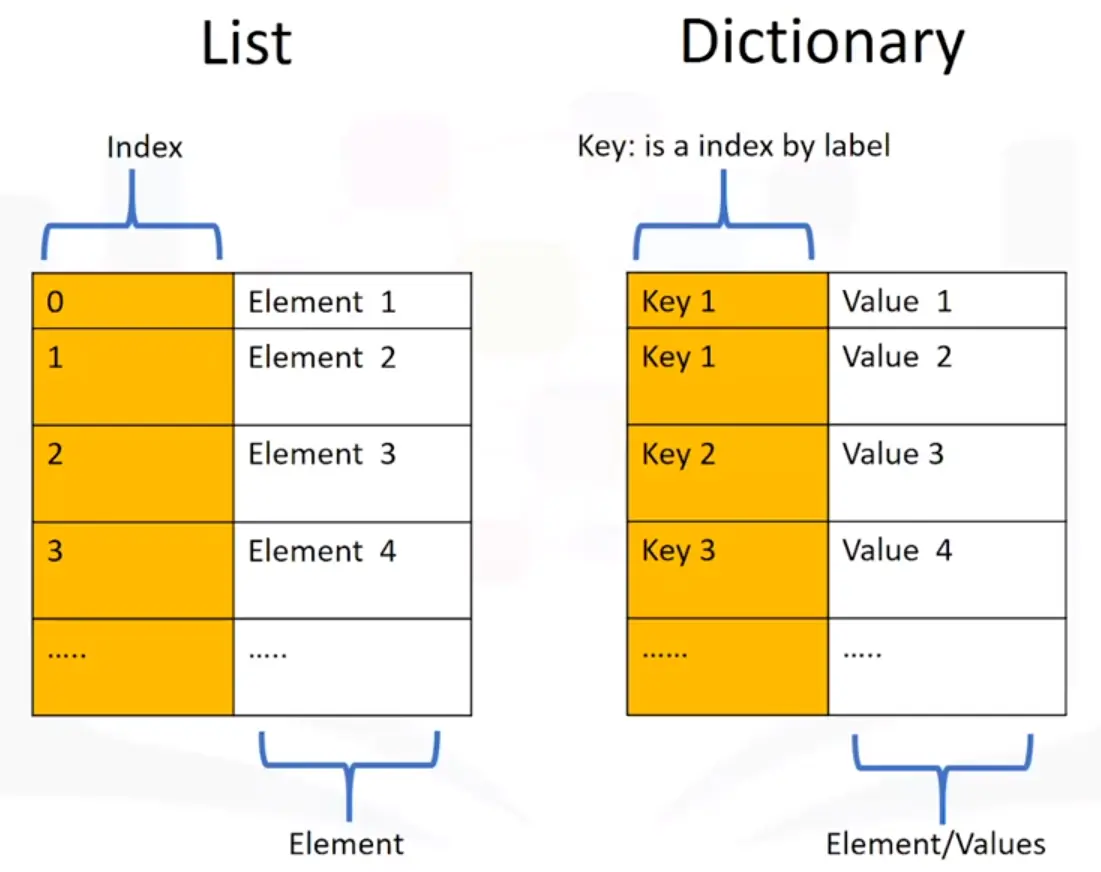
A list is a value that contains multiple values.
The values in a list are also called item.
You can access items in a list with its integer index.
The indexes start at 0, not 1.
You can also use negative indexes. -1 refers to the last item, -2 refers to the second to last item, and so on.
You can get multiple items from the list using a slice.
The slice has two indexes. The new list’s items start at the first index and go up to, but doesn’t include, the second index.
The len() function, concatenation, and replication work the same way with lists that they do with strings.
You can convert a value into a list by passing it to the first() function.
The list Data Type
A list is a value that contains multiple values in an ordered sequence. The term list value refers to the list itself (which is a value that can be stored in a variable or passed to a function like any other value), not the values inside the list value.
The spam variable ➊ is still assigned only one value: the list value. But the list value itself contains other values. The value [] is an empty list that contains no values, similar to '', the empty string.
Getting Individual Values in a List with Indexes
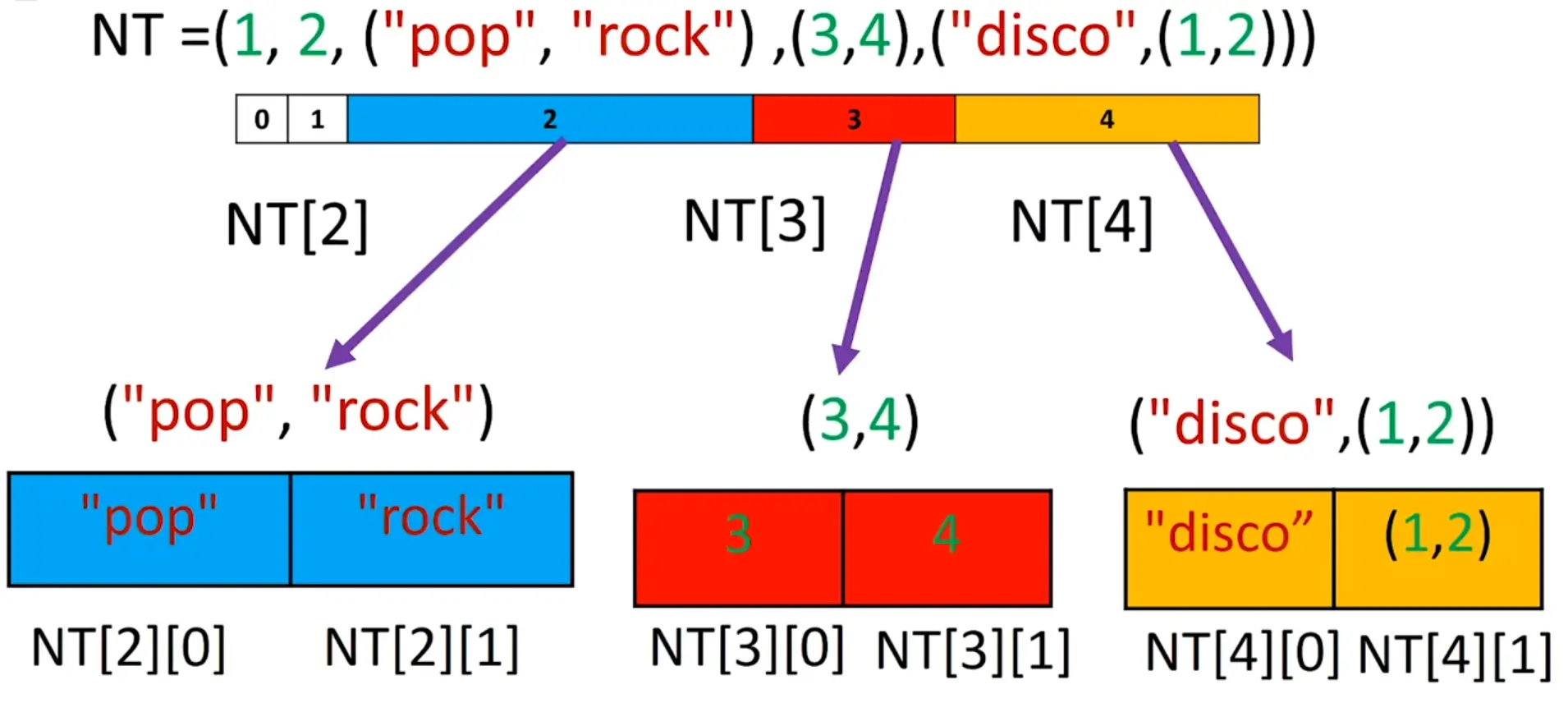
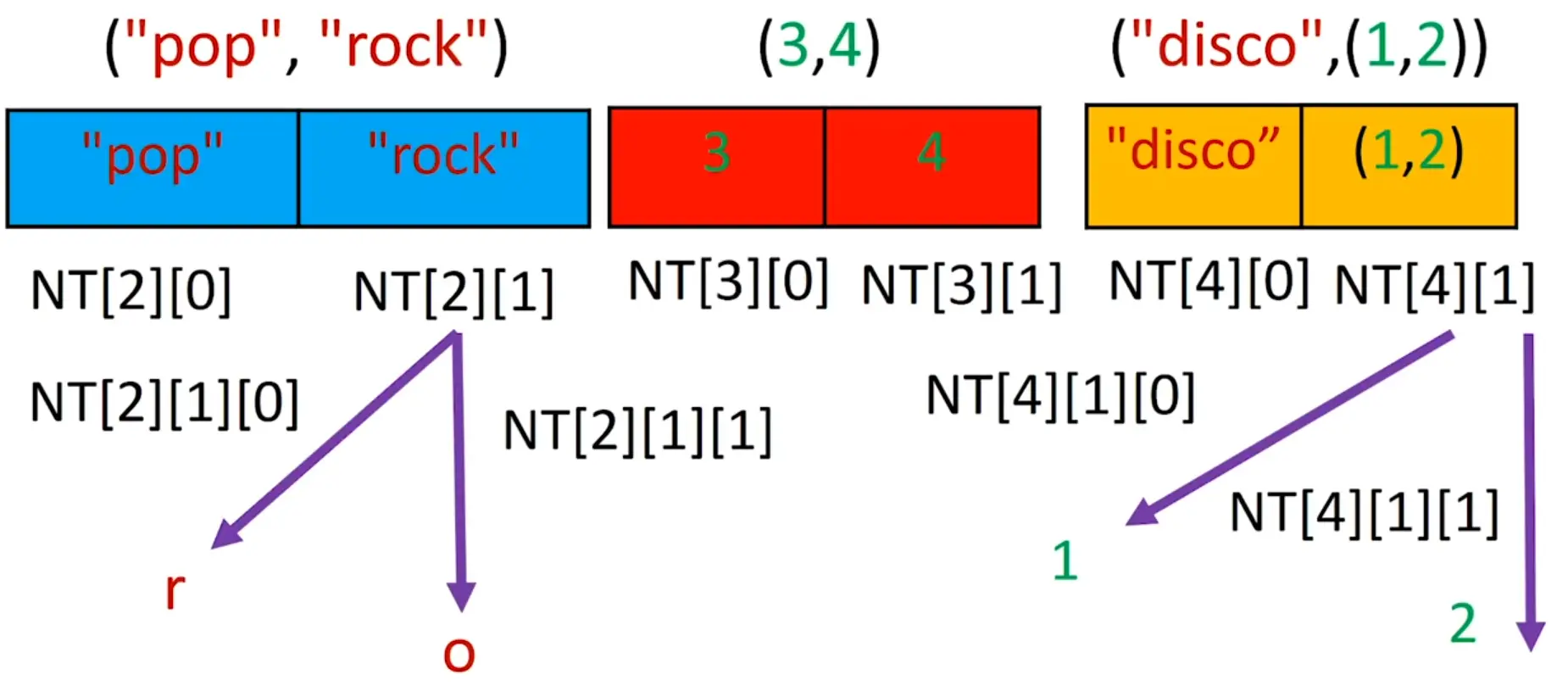
Lists can also contain other list values. The values in these lists of lists can be accessed using multiple indexes, like so:
The first index dictates which list value to use, and the second indicates the value within the list value.
Negative Indexes
The integer value -1 refers to the last index in a list, the value -2 refers to the second-to-last index in a list, and so on.
>>>spam=['cat','bat','rat','elephant']>>>spam[-1]'elephant'>>>spam[-3]'bat'>>>'The '+spam[-1]+' is afraid of the '+spam[-3]+'.''The elephant is afraid of the bat.'
Getting a List from Another List with Slices
Just as an index can get a single value from a list, a slice can get several values from a list, in the form of a new list. A slice goes up to, but will not include, the value at the second index.
As a shortcut, you can leave out one or both of the indexes on either side of the colon in the slice. Leaving out the first index is the same as using 0, or the beginning of the list. Leaving out the second index is the same as using the length of the list, which will slice to the end of the list. Enter the following into the interactive shell:
The len() function will return the number of values that are in a list value passed to it, just like it can count the number of characters in a string value.
The del statement can also be used on a simple variable to delete it, as if it were an “un-assignment” statement. If you try to use the variable after deleting it, you will get a NameError error because the variable no longer exists. In practice, you almost never need to delete simple variables. The del statement is mostly used to delete values from lists.
Working with Lists
It’s tempting to create many individual variables to store a group of similar values.
It’s a bad way to write a program.
Down the line, when you will need to store more values, you won’t be able, if you run out of variables.
Let’s look at the example of bad code using a lot of variables to store a group of similar values:
print('Enter the name of cat 1:')catName1=input()print('Enter the name of cat 2:')catName2=input()print('Enter the name of cat 3:')catName3=input()print('Enter the name of cat 4:')catName4=input()print('Enter the name of cat 5:')catName5=input()print('Enter the name of cat 6:')catName6=input()print('The cat names are:')print(catName1+' '+catName2+' '+catName3+' '+catName4+' '+catName5+' '+catName6)
Improved version:
catName=[]whileTrue:print(f"Enter your cat name: {len(catName)+1} (Or Enter nothing to stop.)")name=input()ifname=='':breakcatName=catName+[name]print("The cat names are: ")fornameincatName:print(f" {name}")
for Loops with Lists, Multiple Assignment, and Augmented Operators
For loops technically iterate over the values in a list.
The range() function returns a list-like value, which can be passed to the list() function if you need an actual list value.
Variables can swap their values using multiple assignment.
Augmented assignment operators like += are used as shortcuts.
Using for Loops with Lists
for Loops execute a block of code a certain number of times. Technically, a for loop repeats the code block once for each item in a list value.
#inputforiinrange(4):print(i)#output0123
This is because the return value from range(4) is a sequence value that Python considers similar to [0,1,2,3] (Sequence Data Types).
The following program has same output as the previous one:
foriin[0,1,2,3]:print(i)
A common Python technique is to use range(len(someList)) with a for loop to iterate over the indexes of a list.
supplies=['pens','staplers','printers','binders']foriinrange(len(supplies)):print(f"Index of {i} in supplies is: {supplies[i]}")Index0insuppliesis:pensIndex1insuppliesis:staplersIndex2insuppliesis:printersIndex3insuppliesis:binders
The in and not in Operators
The in and not in operators are used to determine whether a value is or isn’t in a list.
Program: Write a program that lets the user type in a pet name and then checks to see whether the name is in a list of pets.
The Multiple Assignment Trick
The multiple assignment trick (technically called tuple unpacking) is a shortcut that lets you assign multiple variables with the values in a list in one line of code. So instead of doing this:
The number of variables and the length of the list must be exactly equal, or Python will give you a ValueError.
Using the enumerate() Function with Lists
Instead of using range(len(someList)) technique, enumerate() returns both list item, and its index, when called upon a list.
>>>supplies=['pens','staplers','flamethrowers','binders']>>>forindex,iteminenumerate(supplies):...print('Index '+str(index)+' in supplies is: '+item)Index0insuppliesis:pensIndex1insuppliesis:staplersIndex2insuppliesis:flamethrowersIndex3insuppliesis:binders
The enumerate() function is useful if you need both the item and the item’s index in the loop’s block.
Using the random.choice() and random.shuffle() Functions with Lists
The random module has a couple of functions that accept lists for arguments. The random.choice() function will return a randomly selected item from the list.
Methods are functions that are “called on” values.
The index() list method returns the index of an item in the list.
The append() list method adds a value to the end of the list.
The insert() list method adds a value anywhere inside a list.
The remove() list method removes an item, specified by the value, from a list.
The sort() list method sorts the items in a list.
The sort() method’s reverse=True keyword argument can sort in reverse order.
Sorting happens in “ASCII-betical” order. To sort normally, pass key=str.lower.
These list methods operate on the list “in place”, rather than returning a new list value.
Methods belong to a single data type. The append() and insert() methods are list methods and can be only called on list values, not on other values such as strings or integers.
Calling list methods on str or inte will give the error AttributeError.
Each data type has its own set of methods. This list data type, for example, has several useful methods for finding, adding, removing, and other manipulating values in a list.
Notice that the code is spam.append('moose') and spam.insert(1, 'chicken'), not spam = spam.append('moose') and spam = spam.insert(1, 'chicken'). Neither append() nor insert() gives the new value of spam as its return value. (In fact, the return value of append() and insert() is None, so you definitely wouldn’t want to store this as the new variable value.) Rather, the list is modified in place. Modifying a list in place is covered in more detail later in Mutable and Immutable Data Types.
The sort() method sorts the list in place, don’t try to capture the return value writing code like spam = spam.sort().
You cannot sort lists that have both number values and string values. Since Python doesn’t know what to do with them.
The sort() uses ASCII-betical order rather than actual alphabetical order for sorting strings. This means uppercase letters come before lowercase letters.
In most cases, the amount of indentation for a line of code tells Python what block it is in. There are some exceptions to this rule, however. For example, lists can actually span several lines in the source code file. The indentation of these lines does not matter; Python knows that the list is not finished until it sees the ending square bracket. For example, you can have code that looks like this:
Of course, practically speaking, most people use Python’s behavior to make their lists look pretty and readable.
Similarities Between Lists and Strings
Strings can do a lot of the same things lists can do, but strings are immutable.
Mutable values like lists can be modified in place.
Variables don’t contain lists, they contain references to lists.
When passing a list argument to a function, you are actually passing a list reference.
Changes made to a list in a function will affect the list outside the function.
The \ line continuation character can be used to stretch Python instructions across multiple lines.
Sequence Data Types
Lists aren’t the only data types that represent ordered sequences of values.
Strings and lists are actually similar if you consider a string to be a “list” of single text characters.
The Python sequence data types include lists, strings, range object returned by range(), and tuples.
Many things you can do with lists can also be done with strings and other values of sequence types: indexing; slicing; and using them with for loops, with len(), and with in and not in operators.
Trying to reassign a single character in a string results in a TypeError error:
>>>name='Zophie a cat'>>>name[7]='the'Traceback(mostrecentcalllast):File"<pyshell#50>",line1,in<module>name[7]='the'TypeError:'str'objectdoesnotsupportitemassignment
The proper way to “mutate” a string is to use slicing and concatenation to build a new string by copying from parts of the old string.
>>>name='Zophie a cat'>>>newName=name[0:7]+'the'+name[8:12]>>>name'Zophie a cat'>>>newName'Zophie the cat'
Although a list value is mutable:
>>>eggs=[1,2,3]>>>eggs=[4,5,6]>>>eggs[4,5,6]
The list value in eggs isn’t being changed here; rather, an entirely new and different list value [4, 5, 6] is overwriting the old list.
If you have only one value in your tuple, you cna indicate this by placing a trailing comma after the value inside the parentheses. Otherwise, Python will think you’ve just typed a value inside regular parentheses.
You can use tuples to convey to anyone reading your code that you don’t intend for that sequence of values to change. If you need an ordered sequence of values that never changes, use a tuple. A second benefit of using tuples instead of lists is that, because they are immutable, and their contents don’t change, Python can implement some optimizations.
Converting Types with the list() and tuple() Functions
Just like how str(42) will return '42', the string representation of the integer 42, the functions list() and tuple() will return list and tuple versions of the values passed to them:
Converting a tuple to a list is handy if you need a mutable version of a tuple value.
Reference Types
As you’ve seen, variables “store” strings and integer values. However, this explanation is a simplification of what Python is actually doing. Technically, variables are storing references to the computer memory locations where the values are stored.
When you assign 42 to the spam variable, you are actually creating the 42 value in the computer’s memory and storing a reference to it in the spam variable. When you copy the value in spam and assign it to the variable cheese, you are actually copying the reference. Both the spam and cheese variables refer to the 42 value in the computer’s memory. When you later change the value in spam to 100, you’re creating a new 100 value and storing a reference to it in spam. This doesn’t affect the value in cheese. Integers are immutable values that don’t change; changing the spam variable is actually making it refer to a completely different value in memory.
But lists don’t work this way, because list values can change; that is, lists are mutable. Here is some code that will make this distinction easier to understand.
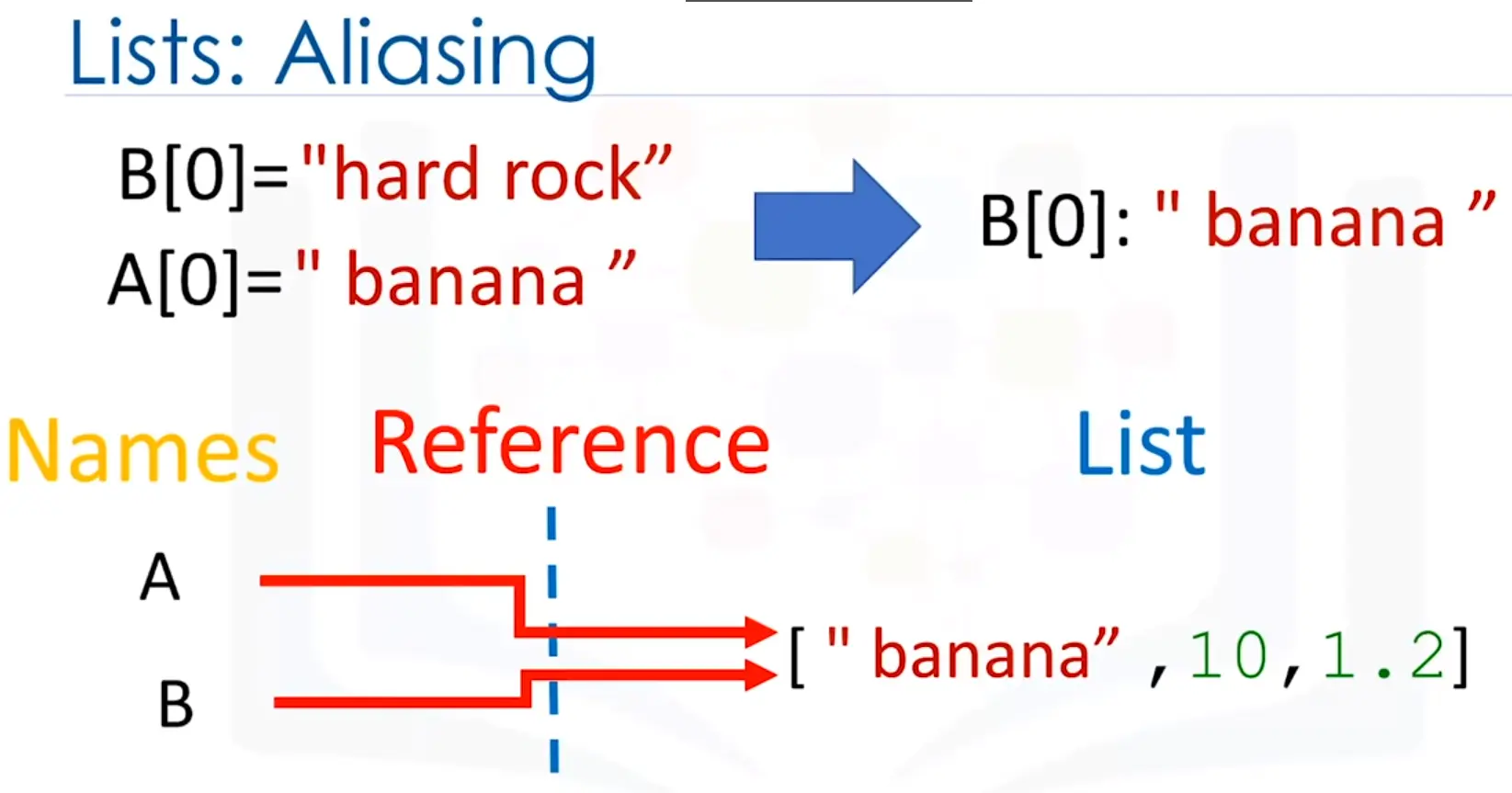
➊>>>spam=[0,1,2,3,4,5]➋>>>cheese=spam# The reference is being copied, not the list. ➌>>>cheese[1]='Hello!'# This changes the list value. >>>spam[0,'Hello!',2,3,4,5]>>>cheese# The cheese variable refers to the same list. [0,'Hello!',2,3,4,5]
This might look odd to you. The code touched only the cheese list, but it seems that both the cheese and spam lists have changed.
When you create the list ➊, you assign a reference to it in the spam variable. But the next line ➋ copies only the list reference in spam to cheese, not the list value itself. This means the values stored in spam and cheese now both refer to the same list. There is only one underlying list because the list itself was never actually copied. So when you modify the first element of cheese ➌, you are modifying the same list that spam refers to.
What happens when a list is assigned to the spam variable.
Then, the reference in spam is copied to cheese. Only a new reference was created and stored in cheese, not a new list. Note how both references refer to the same list.
When you alter the list that cheese refers to, the list that spam refers to is also changed, because both cheese and spam refer to the same list.
Identity and the id() Function
Why the weird behavior with mutable lists in the previous section doesn’t happen with immutable values like integers or strings.
We can use Python’s id() function to understand this. All values in Python have a unique identity that can be obtained with the id() function.
>id('Howdy')# The returned number will be different on your machine. 139789342729024
When Python runs id('Howdy'), it creates the 'Howdy' string in the computer’s memory. The numeric memory address where the string is stored is returned by the id() function. Python picks this address based on which memory bytes happen to be free on your computer at the time, so it’ll be different each time you run this code.
Like all strings, 'Howdy' is immutable and cannot be changed. If you “change” the string in a variable, a new string object is being made at a different place in memory, and the variable refers to this new string. For example, enter the following into the interactive shell and see how the identity of the string referred to by bacon changes:
>>>bacon='Hello'>>>id(bacon)139789339474704>>>bacon+=' world!'# A new string is made from 'Hello' and ' world!'. >>>id(bacon)# bacon now refers to a completely different string. 139789337326704
However, lists can be modified because they are mutable objects. The append() method doesn’t create a new list object; it changes the existing list object. We call this modifying the object in-place.
>>>eggs=['cat','dog']# This creates a new list. >>>id(eggs)139789337916608>>>eggs.append('moose')# append() modifies the list "in place". >>>id(eggs)# eggs still refers to the same list as before. 139789337916608>>>eggs=['bat','rat','cow']# This creates a new list, which has a new identity. >>>id(eggs)# eggs now refers to a completely different list. 139789337915136
Passing References
References are particularly important for understanding how arguments get passed to functions. When a function is called, the values of the arguments are copied to the parameter variables. For lists (and dictionaries, which I’ll describe in the next chapter), this means a copy of the reference is used for the parameter.
Notice that when eggs() is called, a return value is not used to assign a new value to spam. Instead, it modifies the list in place, directly. When run, this program produces the following output:
[1, 2, 3, 'Hello']
Even though spam and someParameter contain separate references, they both refer to the same list. This is why the append('Hello') method call inside the function affects the list even after the function call has returned.
Keep this behavior in mind: forgetting that Python handles list and dictionary variables this way can lead to confusing bugs.
The copy Module’s copy() and deepcopy() Functions
Although passing around references is often the handiest way to deal with lists and dictionaries, if the function modifies the list or dictionary that is passed, you may not want these changes in the original list or dictionary value. For this, Python provides a module named copy that provides both the copy() and deepcopy() functions. The first of these, copy.copy(), can be used to make a duplicate copy of a mutable value like a list or dictionary, not just a copy of a reference.
>>>importcopy>>>spam=['A','B','C','D']>>>id(spam)139789337916608>>>cheese=copy.copy(spam)>>>id(cheese)# cheese is a different list with different identity. 139789337915776>>>cheese[1]=42>>>spam['A','B','C','D']>>>cheese['A',42,'C','D']
Now the spam and cheese variables refer to separate lists, which is why only the list in cheese is modified when you assign 42 at index 1.
If the list you need to copy contains lists, then use the copy.deepcopy() function instead of copy.copy() The deepcopy() function will these inner lists as well.
Projects
There are following project given in the book. Check their code at my GitHub.
A Short Program: Conway’s Game of Life
Conway’s Game of Life is an example of cellular automata: a set of rules governing the behavior of a field made up of discrete cells. In practice, it creates a pretty animation to look at. You can draw out each step on graph paper, using the squares as cells. A filled-in square will be “alive” and an empty square will be “dead.” If a living square has two or three living neighbors, it continues to live on the next step. If a dead square has exactly three living neighbors, it comes alive on the next step. Every other square dies or remains dead on the next step.
Four steps in a Conway’s Game of Life Simulation
Even though the rules are simple, there are many surprising behaviors that emerge. Patterns in Conway’s Game of Life can move, self-replicate, or even mimic CPUs. But at the foundation of all of this complex, advanced behavior is a rather simple program.
We can use a list of lists to represent the two-dimensional field. The inner list represents each column of squares and stores a '#' hash string for living squares and a ' ' space string for dead squares.
Comma Code
Say you have a list value like this:
spam=['apples','bananas','tofu','cats']
Write a function that takes a list value as an argument and returns a string with all the items separated by a comma and a space, with and inserted before the last item. For example, passing the previous spam list to the function would return 'apples, bananas, tofu, and cats'. But your function should be able to work with any list value passed to it. Be sure to test the case where an empty list [] is passed to your function.
Coin Flip Streaks
For this exercise, we’ll try doing an experiment. If you flip a coin 100 times and write down an “H” for each heads and “T” for each tails, you’ll create a list that looks like “T T T T H H H H T T.” If you ask a human to make up 100 random coin flips, you’ll probably end up with alternating head-tail results like “H T H T H H T H T T,” which looks random (to humans), but isn’t mathematically random. A human will almost never write down a streak of six heads or six tails in a row, even though it is highly likely to happen in truly random coin flips. Humans are predictably bad at being random.
Write a program to find out how often a streak of six heads or a streak of six tails comes up in a randomly generated list of heads and tails. Your program breaks up the experiment into two parts: the first part generates a list of randomly selected ‘heads’ and ’tails’ values, and the second part checks if there is a streak in it. Put all of this code in a loop that repeats the experiment 10,000 times so we can find out what percentage of the coin flips contains a streak of six heads or tails in a row. As a hint, the function call random.randint(0, 1) will return a 0 value 50% of the time and a 1 value the other 50% of the time.
You can start with the following template:
importrandomnumberOfStreaks=0forexperimentNumberinrange(10000):# Code that creates a list of 100 'heads' or 'tails' values. # Code that checks if there is a streak of 6 heads or tails in a row. print('Chance of streak: %s%%'%(numberOfStreaks/100))
Of course, this is only an estimate, but 10,000 is a decent sample size. Some knowledge of mathematics could give you the exact answer and save you the trouble of writing a program, but programmers are notoriously bad at math.
Character Picture Grid
Say you have a list of lists where each value in the inner lists is a one-character string, like this:
Think of grid[x][y] as being the character at the x- and y-coordinates of a “picture” drawn with text characters. The (0, 0) origin is in the upper-left corner, the x-coordinates increase going right, and the y-coordinates increase going down.
Copy the previous grid value, and write code that uses it to print the image.
Hint: You will need to use a loop in a loop in order to print grid[0][0], then grid[1][0], then grid[2][0], and so on, up to grid[8][0]. This will finish the first row, so then print a newline. Then your program should print grid[0][1], then grid[1][1], then grid[2][1], and so on. The last thing your program will print is grid[8][5].
Also, remember to pass the end keyword argument to print() if you don’t want a newline printed automatically after each print() call.
IT & SysAdmin
Google IT Support Professional Certificate
Google IT Support Professional Certificate, course consists of 5 individual courses, and each of those courses are further subdivided into different modules.
1. Technical Support Fundamentals
Technical Support Fundamentals is a first course of Google IT Support Professional Certificate.
It has been sub-divided into the following modules…
4. System Administration and IT Infrastructure Services
This is all about managing different IT services, including public and private cloud, platform services (PAAS, SAAS, IAAS). Also it teaches about data different backup solution and data recovery techniques.
This courses is sub-divided into 6 weeks of study program, which has 5 sub-topics and a final project…
This is the IBM version of introduction to IT Support. But it also gives information about different ticketing systems and service level agreements. It provides details about job opportunities and different skill levels in the field.
This course is all about building computers and installing different operating systems on them. It also explains about computer connectors and their types, and peripheral devices. In the end, it gives details about how to troubleshoot a system step by step.
3. Introduction to Software, Programming, and Databases
It goes into details about different computing platforms and types of software applications. It also lists down the available web-browsers, types of cloud computing, basics of programming and types of database queries.
It teaches about the types of networks, like LAN, WAN etc. It lists down the storage types and also goes into the details of troubleshooting common networking problems like DNS issues etc.
Google IT Support Professional Certificate, course consists of 5 individual courses, and each of those courses are further subdivided into different modules.
1. Technical Support Fundamentals
Technical Support Fundamentals is a first course of Google IT Support Professional Certificate.
It has been sub-divided into the following modules…
4. System Administration and IT Infrastructure Services
This is all about managing different IT services, including public and private cloud, platform services (PAAS, SAAS, IAAS). Also it teaches about data different backup solution and data recovery techniques.
This courses is sub-divided into 6 weeks of study program, which has 5 sub-topics and a final project…
It is the first module, of the Technical Support Fundamentals.
What is IT?
The use of digital technology, like computers and the internet, to store and process data into useful information.
Digital Divide: The lack of digital literacy among the masses.
Role of IT Support Specialist
Managing
Installing
Maintaining
Troubleshooting
Configuring
History of Computing
From Abacus to Analytical Engine
Computer
A device that stores and process data performing calculations.
Abacus
The oldest known computer, invented in 500 BC to count large numbers.
Mechanical Engine of 17th Century
It was able to perform summation, subtraction, multiplication, and division but still need human intervention to operate its knob and levers.
Invention of Punch Cards in 18th century shaped the world of computing
Charles Babbage invented the Difference Engine
It was a combination of sophisticated mechanical calculators and was able to perform pretty complex mathematical operations but not much else.
Analytical Engine
Babbage followed his Difference Engine with an Analytical Engine, he was inspired by Punch Cards, and it was able to perform automatic calculations without human interaction.
But it was still a giant Mechanical Computer, though being impressive.
Invention of Algorithms
A Mathematician, Ada Lovelace, realize the true potential of the Analytical Engine. She was the first person to recognize that a machine can be used more than just for pure calculations. She developed the first algorithm for the Engine.
Because of this discovery of Lovelace, the Analytical Engine became the first general purpose computing device in the history.
Algorithm
A series of steps that solve specific problems.
Digital Logic
Computer Language
Binary System
The communication that a computer uses, also known as a base-2 numeral system.
Bit: A number in binary.
Byte: A group of 8-bits.
Each bit can store one character, and we can have 256 possible values thanks to the base-2 system (2**8)
Examples:
10100011, 11110011, 00001111
Character Encoding
Assigns our binary values to characters, so that we as human can read them.
ASCII
The oldest used character encoding system for English alphabet, digits, punctuation marks.
UTF-8
The most prevalent encoding standard used today. Along with the same ASCII table, it lets us use the variable number of bytes.
Binary
As in Punch Card systems, a hole represents the number 1, and no-hole represents the number 0.
In binary, electrical circuits are used to represent zeros and ones (0s,1s), when current passes through the circuit, the circuit is on, and it represents 1, when no electricity passes, the circuit is closed and represents 0.
Logic gates
Allow our transistors to do more complex tasks, like decide where to send electrical signals depending on logical conditions.
AND logic gate
OR logic gate
NOT logic gate
XOR logic gate
NAND logic gate
XNOR logic gate
How to Count in Binary?
256
128
64
28
16
8
4
2
unit(0,1)
Decimal System
0
0
1
1
1
0
2
1
1
3
1
0
0
4
1
0
1
5
1
1
0
6
1
1
1
7
1
0
0
0
8
1
0
0
1
9
1
0
1
0
10
Computer Architecture layer
Abstraction
“To take a relatively complex system and simplify it for our use.”
We don’t interact with the computers in the form of 0s and 1s (we actually do), instead an abstraction layer like, keyboard, mouse, error messages instead of showing a bunch of machine code etc.
Software layer
How we as human interact with our computer.
User
User interacts with a computer. One can operate, maintain, and even program the computer.
Introduction to Computer Hardware
Desktops Computers
They are just computers that can fit on or under our desks.
The following are components of a desktop:
Monitor
Keyboard
Mouse
Desktop
Laptops
They have all the components baked-in inside a single chassis.
Ports
To extend the functionality of a computer, we can plug devices into connection points on it.
CPU (Central Processing Unit)
The brain of our computer, it does all the calculations and data processing.
RAM (Random Access Memory)
Our computer’s short-term memory.
Hard Drive
Holds all of our data, which includes all of our music, pictures, applications.
Motherboard
The body or circulatory system of the computer that connects all the pieces together.
It holds everything in place, and lets our components communicate with each other. It’s the foundation of our computer.
Power Supply
It converts the wall power supply to the format which our computer can use.
Programs and Hardware
Programs
Instructions that tell the computer what to do.
Hardware
External Data Bus (EDB)/Address Bus
-The instruction travel between CPU and RAM through EDB.
Registers
They let us store the data that our CPU works with.
Memory Controller Chip
The MCC is a bridge between the CPU and the RAM.
The MCC grabs the Data from the RAM and sends it through the EDB
Cache
CPU also uses cache. Cache is smaller than RAM, but it let us store data that we use often.
Cache levels: There are three different level of cache in a CPU
L1 L1 is the smallest and the fastest cache.
L2
L3
Wire Clock:
How does our CPU know when the set of instruction ends, and a new one begins. Here comes the Wire Clock in play.
“When you send or receive data, it sends a voltage to that clock wire to let the CPU know it can start doing calculations.”
Clock Cycle:
When you send a voltage to the clock wire, it is referred to as a clock cycle.
Clock Speed:
The maximum number of clock cycles that it can handle in a certain time period.
Over-clocking:
There are ways to increase the clock speed of the CPU, called over-clocking. It increases the rate of your CPU clock cycles in order to perform more tasks.
Overclocking can increase the performance of low-end CPUs, but it has certain cons attached to it, like overheating, more power usage etc
It can lower CPU lifespan as you’re pushing it limits
Increased power and heat will degrade most PC components faster
Components
CPU
Instruction Set
Literally, a list of instructions that our CPU is able to run.
Adding
subtracting
copying data
When you select your CPU, you’ll need to make sure it’s compatible with your motherboard & the circuit board that connects all your components together.
CPU Socket Types
Land grid array (LGA)
pins stick out of the motherboard
pin grid array (PGA)
pins are located on the processor itself
Heat Sink
To cool down CPU, attached with a cooler fan.
RAM
There are lost of types of RAM, and the one that’s commonly found in computers is DRAM, or dynamic random-access memory.
There are also different types of memory sticks that DRAM chips can be put on. The more modern DIMM stick, which usually stand for Dual Inline Memory Module, have different sizes of pins on them.
SDRAM:
Stands for synchronous DRAM. This type of RAM is synchronized with our systems’; clock speed, allowing quicker processing of data.
DDR SDRAM:
In today’s system, we use another type of RAM, called the double data rate SDRAM or DDR SDRAM for short.
DDR1
DDR2
DDR3
DDR4
Just like the CPU, make sure your RAM module is compatible with your motherboard.
Motherboards
Every motherboard has few characteristics:
Chipset
A chipset is a key component of our motherboard that allows us to manage data between our CPU, RAM, and peripherals.
It decides how components talk to each other on our machine:
Northbridge:
It interconnects stuff like RAM and video cards. In some CPUs, northbridge directly baked into the CPU itself.
Southbridge:
It maintains our IO or input/output controllers, like hard drives and USB devices that input and output data.
Peripherals
External devices we connect to our computer, like a mouse, keyboard, and monitor.
Expansion Slots
Give us the ability to increase the functionality of our computer.
The standard for peripheral slot today is PCI Express or Peripheral Component Interconnect Express.
Form Factor
There are different sizes of motherboards available in market toady.
Form factor plays an important role in the choice of PCIes
You don’t want to respond to a ticked without knowing that a customer bought a GPU which doesn’t fit in the PCIe slot.
ATX (Advanced Technology eXtended)
In desktops, you’ll commonly see full sized ATX’s
ITX (Information Technology eXtended)
These are much smaller than ATX board, for example Intel NUC uses a variation of ITX, which comes in three form factors: 1) mini-ITX 2) nano-ITX 3) pico-ITX
Storage
HDD (Hard disk drive)
SDD (solid state drive)
There are few interfaces that hard drive use to connect our system:
ATA ; the most common ATA is serial ATA or SATA
SATA drive are hot swappable, meaning you don’t need to turn off your computer to swap them
The interface couldn’t keep with speeds of newer SSDs
NVM Express or NVMe are used for more modern SSDs and reduces the pitfalls of SATA
kilobyte
The kilobyte is a multiple of the unit byte for digital information.
In base 10, one kilobyte is 1000 bytes
In base 2, one kilobyte is 1024 bytes
Power Supplies
It converts the AC we get from the wall into low voltage DC that we can use and transmit throughout our computer.
Power supplies have the following components:
chassis
fan
I/O cables
power cable
Voltage
Be sure to use proper voltage for your electronics
Ampere
An ampere, often abbreviated as “A,” is the unit of electric current in the International System of Units (SI). Electric current is the flow of electric charge through a conductor, such as a wire. One ampere is defined as the amount of current that flows when one coulomb of electric charge passes through a given point in a circuit per second.
In equation form, it can be expressed as:
$$ 1A = 1C/s $$
This means that if a current of 1 ampere is flowing in a circuit, it indicates that 1 coulomb of charge is passing through a particular point in the circuit every second.
Wattage
The amount of volts and amps that a device needs.
All kinds of issues are caused by bad power supply, sometimes the computer doesn’t even turn on.
Power supplies can fail for lots of reasons like burnouts, power surge, or even lightning strikes.
Mobile Devices
Mobile devices are a computer too. They have:
CPUs
RAM
Storage
Power systems
Peripherals
Mobiles devices can use peripherals too, like headset, micro-USB, USB-C, and lightening USB etc.
Mobiles devices can themselves be the peripherals, like Smart-watch, fitness band etc.
Very small mobile devices uses system-on-chip or SoC
System on a Chip (SoC)
Packs the CPU, RAM, and sometimes even the storage onto a single chip
Batteries and Charging Systems
Battery can be charged via wireless pads or cradle
Rechargeable batteries have limited life span measured in charge cycle
Components require to charge batteries:
Charger
PSU or power supply unit to control power flow
Wall outlet
or Solar panel etc
Charge Cycle
One full charge and discharge of a battery.
Peripherals
Anything that you connect to your computer externally that add functionality
Examples:
Universal serial bus USB
USB 2.0 – transfer speeds of 480 Mb/s
USB 3.0 – transfer speeds of 5 Gb/s
USB 3.1 – transfer speeds of 10 Gb/s
USB 4 – transfer speed of 40 Gb/s
Difference of MB and Mb/s:
MB is a megabyte, unit of data storage, while Mb/s is a megabit per second, which is a unit of data transfer rate.
DVI:
It is generally used for video output, like slide presentation, but for audio you’re out of luck
HDMI:
Have audio and video output
Display Port:
Also outputs audio and video
Type C connector:
It can do power and data transfer
Projector
Projectors are display devices for when you need to share information with people in the same location! Most projectors can be used just like any other display on a computer, and with a few differences, can be troubleshot just like any other display device. For example, projectors can have dead or stuck pixels, and can acquire image burn-in, just like other types of displays.
Starting it Up
BIOS
Our CPU doesn’t know that there is a device that it can talk to, so it has to connect to something called the BIOS
The BIOS is software that helps initialize the hardware in our computer and gets our operating system up and running.
It performs the following functions:
Initialize hardware
POST or power on self test
Checks what devices are connected to the computer
The BIOS can be stored on the motherboard in the following components:
ROM or read only memory
More modern systems use UEFI stands for Unified Extensible Firmware Interface
Eventually, UEFI will become the predominant BIOS
Drivers
They contain the instructions our CPU needs to understand external devices like keyboards, webcams, printers.
Power ON Self Test or POST
When the computer starts it runs systems checks from time to time, refer to as POST.
CMOS Battery
It stores basic data about booting your computer like the date, time and how you wanted to start up.
Reimaging
A frequently performed IT task is the reimaging of a computer.
It refers to a disk image which a copy of an operating system, the process involves wiping and reinstalling an operating system.
The following devices can be used for reimaging:
USB stick
CD/DVD
Server accessible through the network
Putting all together
To build a PC, we need to take care of certain things:
prevent static charge
To avoid, static discharge, you can touch two devices you plugged in but not powered on from time to time
or wear an anti-static wristband
Building Steps
Motherboard: match up holes on motherboard with holes on the desktop
CPU: match CPU pointers alignment on the motherboard, don’t forget to buy compatible motherboard and CPU
Heat-sink: Before attaching on, we need to put even amount of thermal paste on your CPU
Plug molex connector (on Heat sink) to the motherboard to control fan speed
Install RAM sticks on motherboard, line up the pins correctly
Hard Drive: One SATA cable to connect SSD to mother board
Make sure you connect the SATA power to the SSD
Case Fans: Check for label on motherboard which says rear fans
Power Supply: secure it in the case, big pin power the mother board, other for SATA I/O, 8 pin will power the CPU
Plug the cable lying in the case to the mother board, used for buttons, lights etc
Fastens the cables
GPU: plug in PCIe slot
Closed the case
Turn it on plugging it to the monitor, keyboard, mouse, and power outlet.
Mobile Device Repair
Know and understand RMA or return merchandise authorization
Do a factory reset before sending it off-site repair
Before the doing reset inform the end user for possible outcomes of losing all the data
Factory Reset
Removes all data, apps, and customization from the device.
Operating Systems
What is an OS?
An operating system (OS) is software that manages computer hardware and facilitates communication between applications and the underlying hardware. It oversees processes, allocating resources like CPU and memory, and provides a file system for data organization. The OS interacts with input/output devices and often includes a user interface for human-computer interaction. It ensures security through features like user authentication and access control. Examples include Windows, macOS, Linux, and mobile OS like Android and iOS. The OS is a fundamental component that enables the proper functioning of computers and devices.
Remote Connection and SSH
Remote Connection
Allows us to manage multiple machines from anywhere in the world.
Secure Shell (SSH)
A protocol implemented by other programs to securely access one computer from another.
Popular software to work with SSH, on Linux, OpenSSH program, while on Windows, PuTTY is used.
In SSH, a pair of public and private keys is used to authenticate the process.
To securely connect to a remote machine, a VPN is used.
VPN
Allows you to connect to a private network, like your work network, over the Internet.
Remote Connections on Windows
PuTTY
A free, open source software that you can use to make remote connections through several network protocols, including SSH.
DOING PuTTY can be used from CL, as putty.exe & ssh user@ip\<address>
PuTTY comes with a Plink or PuTTYlink program, which can also be used for SSH-ing to other computers.
Microsoft provides another way to remotely connect with Windows computer via GUI, called Remote Desktop Protocol (RDP).
Components of an Operating System
Operating System
The whole package that manages our computer’s resources and lets us interact with it.
Two main parts
Kernel: Storage and file management, processes, memory control, I/O management
User Space: Everything out of the scope of the Kernel, like application, CLI tools etc
Files and File Systems
File storage include three things:
Data
File handling
Metadata
Block Storage
Improves faster handling of data because the data is not stored as one long piece and can be accessed quicker.
Process Management
Process
A program that is executing, like our internet browser or text editor.
Program
An application that we can run, like Chrome.
Time slice
A very short interval of time, that gets allocated to a process for CPU execution.
Role of Kernel
Create processes
efficiently schedules them
Manages how processes are terminated
Memory Management
Virtual Memory
The combination of hard drive space and RAM that acts like memory that our processes can use.
Swap Space
Allocated Space for virtual memory.
I/O Management
Kernel does Input/Output devices by managing their intercommunicating and resource management etc.
Interacting with the OS: User Space
Two ways to interact with the OS
Shell
A program that interprets text commands and sends them to the OS to execute.
GUI
Logs
Files that record system events on our computer, just like a system’s diary.
The Boot Process
The computer boots in the following order.
BIOS/UEFI
A low-level software that initializes our computer’s hardware to make sure everything is good to go.
POST
Power on Self Test (POST) is performed to make sure the computer is in proper working order.
Bootloader
A small program that loads the OS.
Kernel
System Processes
User Space
Networking
Physical Layer
This layer describes that how devices connect to each other at the physical level. On this level, twisted-pair cables and duplexing is used.
Duplex communication has two types;
Half-duplex: Communication is possible only in one direction at a time.
Full-Duplex/Duplex: The information can flow in the both direction at the same time.
The information travels in the form of bits in the Physical layer.
Data link Layer
Responsible for defining a common way of interpreting signals coming from the physical layer, so network devices can communicate with each other.
It consists of following protocols;
Wi-Fi
Ethernet
The data sent in this layer in the form of frames. We can identify devices working at the Physical layer by their MAC addresses.
Network Layer
This layer corresponds to the combination of Data Link Layer and Physical Layer of OSI Model. It looks out for hardware addressing and the protocols present in this layer allows for the physical transmission of data.
This layer includes
IP addressing
Encapsulation
The unit of data in the network layer is datagram.
Transport Layer
Transport layer is the second layer in TCP/IP model. It is an end-to-end layer used to deliver messages to a host. It is termed an end-to-end layer because it provides a point-to-point connection rather of hop-to-hop, between the source host and destination host to deliver the services reliably. The unit of data in the transport layer is a segment.
Multiplexing and Demultiplexing
Multiplexing allows simultaneous use of different applications over a network that is running on a host. The transport layer provides this mechanism, which enables us to send packet streams from various applications simultaneously over a network. The transport layer accepts these packets from different processes, differentiated by their port numbers, and passes them to the network layer after adding proper headers. Similarly, Demultiplexing is required at the receiver side to obtain the data coming from various processes. Transport receives the segments of the data from the network layer and delivers it to the appropriate process running of the receivers’ machine.
MAC Address
A globally unique identifier attached to the individual network interfaces. It is a 48-bits number, normally represented by 6 groups of 2 hexadecimal numbers.
MAC addresses split up into two categories;
1) Organizationally Unique Identifier (UIO):
The first three groups represent the UIO of the device, which is unique to every organization issuing it. I.e., for Cisco, UIO is 00 60 2F.
2) Vendor Assigned(NIC Cards, interfaces):
The last three octets are assigned by the vendor, depending upon their preferences. Which tells us about that particular device it’s assigned for.
IP Address
An IP address, or Internet Protocol address, is a series of numbers that identifies any device on a network. Computers use IP addresses to communicate with each other, both over the internet and on other networks.
An IP address consists of 4 octets of 8 bits, so it has 32-bits in total. There are two types of IP addresses;
1) IPv4 address
IPv4 addresses consist of 4 octets of decimal numbers, each octet range from 0-255. There are only 4 billion IPv4 addresses to use for us, so we need some other way to assign IPs to the devices to overcome the shortage of IP addresses.
IPv4 addresses are further divided into three major classes;
a) Class-A Addresses: These have only the first octet for network ID, and the rest for the host IDs.
b) Class-B Addresses: These have the first 2 octets for network IDs, and the rest for the host IDs.
c) Class-C addresses: These have first 3 octets for Network IDs, and the only last one for host IDs.
2) IPv6 Addresses
IPv6 addresses has 132-bit of hexadecimal numbers, it has 2^128 IP addresses, which solves our problem of IP address shortage.
TCP Port
A 16-bit number that’s used to direct traffic to specific services running on a networked computer.
There are almost, 65535 ports available to use which are categorized as follows;
Port 0 used for internal traffic between different programs on the same computer.
Ports 1-1024 are called system ports or well known ports. These are used for some well known services such HTTP, FTP, SMTP and require admin level privileges for the port to be accessed.
Ports 1025-49151 are called registered ports. They are used for the services not well known as used by system ports. They don’t require admin level access for the port to be accessed.
Ports 49152-65535 are called ephemeral ports. They are used for establishing outbound connections.
Checksum Check
A checksum is a value that represents the number of bits in a transmission message and is used by IT professionals to detect high-level errors within data transmission.
The common algorithm used for checksum is MD5, SHA-2 etc
Routing Table
A routing table is a set of rules, often viewed in table format, that is used to determine where data packets traveling over an Internet Protocol (IP) network will be directed. All IP-enabled devices, including routers and switches, use routing tables.
Destination
Subnet mask
Interface
128.75.43.0
255.255.255.0
Eth0
128.75.43.0
255.255.255.128
Eth1
192.12.17.5
255.255.255.255
Eth3
default
Eth2
Entries of an IP Routing Table:
A routing table contains the information necessary to forward a packet along the best path toward its destination. Each packet contains information about its origin and destination. The routing table provides the device with instructions for sending the packet to the next hop on its route across the network.
Each Entry in the routing table consists of the following route.
1) Network ID:
The network ID or destination corresponding to the route.
2) Subnet Mask:
The mask that is used to match a destination IP address to the network ID.
3) Next Hop:
The IP address to which the packet is forwarded.
4) Outgoing Interface:
Outgoing interface the packet should go out to reach the destination network.
5) Metric:
A common use of the metric is to indicate the minimum number of hops (routers crossed) to the network ID.
Routing table entries can be used to store the following types of routes:
Directly Attached Network IDs
Remote Network IDs
Host Routes
Default Routes
Destination
TTL
Time-to-live (TTL) in networking refers to the time limit imposed on the data packet to be in-networking before being discarded. It is an 8-bit binary value set in the header of Internet Protocol (IP) by sending the host. The Purpose of a TTL is to prevent data packets from being circulated forever in the network. The maximum TTL value is 255, while the commonly used one is 64.
What is Software?
Coding
Translating one language to another.
Scripting
Coding in a scripting language.
Scripts
Mainly used to perform a single or limited range task.
Programming
Coding in a programming language.
Programming Languages
Special languages that software developers use to write instructions for computers to execute.
Types of Software
Commercial Software
Open-source Software
Application Software
Any software created to fulfill a specific need, like a text editor, web browser, or graphic editor.
System Software
Software used to keep our core system running, like OS tools and utilities.
Firmware
Software that is permanently stored on a computer component.
Revisiting abstraction
The concept of taking a complex system and simplifying it for use.
Recipe for Computer
Assembly language
Allowed computer scientists to use human-readable instructions, assembled into code, that the machine could understand.
Compiled programming languages
Uses human-readable instructions, then sends them through a compiler.
Interpreted programming languages
The script is run by an interpreter, which interprets the code into CPU instructions just in time to run them.
Troubleshooting Best Practices
1) Ask Questions
Ask good questions to get more information about the problem.
IT Support is about working in the service of others. Always try to create a positive experience for the user.
2) Isolating the Problem
Shrink the scope of the Problem by asking good questions and looking at root cause.
3) Follow the Cookie Crumbs
Go back to the time when the issue started.
Look at the logs at time of crash.
Start with the Quickest Step First
4) Troubleshooting Pitfalls to Avoid
Going into autopilot mode.
Not finding the Root Cause.
Troubleshooting
The ability to diagnose and resolve an issue.
Root Cause
The main factor that is causing a range of issues.
Customer Service
Intro to Soft Skills
Build the trust between you and the User.
Know the Company Policies about handling support request.
Following are some important features for IT Support.
Exhibiting empathy
Being conscious of your tone
Acknowledge the Person
Developing the trust
Anatomy of an Interaction
Learn to say “Hello” in a friendly way.
Good grammar during text/email support.
Just be professional, acknowledge the user, and show them some respect.
Respond to User Questions nicely.
Just clarify the issue beforehand while going for troubleshooting steps.
During a remote support session, tell the user when you are running certain commands.
The last five minutes of the process set the overall impact, so end on positive terms with the user.
How to Deal with Difficult Situations
What you face a difficult situation, relax, and think about what went wrong? How are you feeling? What was your reaction? Why did you raise your voice? Discuss with your peers the situation and get their feedback.
Try to be alerted, when interaction goes sideways, and redirect the conversation.
Try to see things from others people’s point of view.
Documentation
Ticketing Systems and Documenting Your Work
Some ticketing systems help track the user issues.
Bugzilla
JIRA
Redmine
Using the ticketing system and documentation is important for two reasons.
It keeps the user in the loop.
It helps you audit your steps in case you need to go back and see what you did.
Tickets
A common way of documenting an issue.
Bugs
Issues with the system that weren’t caused by an external source.
System and processes are always changing, so should your documentation.
Always write documentation that is easy to read and follow for your user.
Getting Through a Technical Interview
Standing Out from the Crowd
Make sure you have a good and updated online presence and fine-grained resume to stand out from the crowd.
Research about the company you are applying for.
Resume
Your resume is your first introduction to a new company.
If you are a new graduate, or are still studying, you’ll want to include a few additional details, like interesting projects that you did during your studying or highlight an elective subject that you took. After a few years of professional experience, though, you may simply include the degree, year, and location.
Functional or skill based resume format works fresh graduates or candidates with limited work experience: The focus of this format is more around your skill set, rather than your work experience. You can include a brief summary of qualifications, followed by a list of skills with examples for each. This format works well for candidates with less employment history, but lots of applicable skills.
For relevant skills. You want to include the general topics that you are knowledgeable about, as in customer support, networking, system administration, programming, etc. You may list the Operating Systems that you’ve worked with and the programming languages that you are skilled in, but don’t try to list every networking protocol you’ve heard about or every IT tool that you’ve ever used. The noise distracts from the relevant information.
Regardless of the format you decide to use (chronological, functional, etc.), make sure you keep the format and structure consistent throughout. For example, if you use full sentences for your bullets, be sure to use that format for all of them and include proper punctuation and grammar. Check your font sizes and styles to ensure those are consistent as well.
Tailoring the resume
Good practice to check if your resume match with the job description.
Tailor your resume to each job you are applying for.
Add your relevant experience for the job, no matter where you got if from.
Your online Presence
Keep your linked-in and other social media up-to-date
Writing a summary that tell both your current role (if applicable) and your career aspiration.
LinkedIn profiles are much more in depth than resumes. You can include specific accomplishments from as many roles as you like, but use the same format as your resume (Action Verb + specific task + quantifiable point).
Adding in personal projects can also be helpful, especially if you have something tangible to show from it. For example, if you’ve created an application, a website, or similar type of product as part of a hobby or school project, include it and provide a link to it.
Just like a resume, list your skills, your experience and what you are looking for as your next step. Make sure that you include all the relevant background information that a recruiter looking at your profile might be interested in. Make sure you are descriptive, don’t assume the reader will have context.
Getting Ready for the Interview
Mock Interview: Pretending that you are in an interview, even if it is not real, will help you perform your best.
Practice to explain ideas for non-technical audience will make you better equipped for an interview.
Actively listen to the other person, maintaining eye-contact. Ask relevant questions.
Don’t try to memorize the answers, just try to practice with different conceptual approaches to get better at explaining stuff.
You can memorize your Elevator Pitch.
Elevator Pitch
A short summary of who you are and what kind of career you are looking for.
Creating Your Elevator Pitch
An elevator pitch is a short description of yourself. The name comes from the fact that you want it to be so short that you can deliver it to someone that you are meeting in an elevator ride.
The goal of the elevator pitch is to explain who you are, what you do, and why the other person should be interested in you.
In an interviewing context, you want to be able to quickly define who you are, what your current role is and what your future goals are.
Remember that you want to keep it personal, you want to get the attention of the other person and let them know why they are interested in you.
Examples
1) If you are a student, you will want to include what and where you are studying, and what you are looking to do once you have graduated.
Hi! I’m Jamie, I’m in my senior year at Springfield University, studying Computer Science. I enjoy being able to help people and solve problems, so I’m looking forward to putting my tech skills into practice by working as an IT Support Specialist after I graduate.
2) If you already have a job, looking for a change. You will include what you do and what different you are looking for.
Hi! I’m Ellis, I’ve been working at X Company as an IT Support Specialist for the past two years. During those years, I’ve learned a lot about operating systems and networking, and I’m looking to switch to a system administrator position, where I can focus on large scale deployments.
What to Expect During the Technical Interview
A good Interviewer may push you to the limits of your knowledge.
If you don’t know the answer, don’t say just say, I don’t know; Rather explain how would you solve it by going around it.
Having a good problem-solving strategy is more important than knowing all the answers.
If the question is a bit complex, think out loud to keep the interviewer on your thought train, and before going straight into the solution, break into pieces.
When you mention concepts or technologies, you should be ready to explain them and articulate why you may choose one thing over another.
It is OK, and even expected, to ask the interviewer follow-up questions to ensure that the problem is correctly framed.
Take notes when an issue involves many steps, but don’t feel the necessity to write everything during an interview.
Showing Your Best Self During the Interview
Take a good sleep at night.
Don’t try to cram information at the last minute.
Ask for pen and paper for notes during an interview.
Be sure to fully present for the duration of the interview.
Be yourself.
Ask questions about the things that you care about.
Remember to slow down.
The Bits and Bytes of Computer Networking
This course delves deep into computer networking and transport layers.
The physical connection of computers and wires around the world.
The Web
The information present on the Internet.
Networking
In an IT field, managing, building, and designing networks.
Networking Hardware
Ethernet Cables
Wi-Fi
Fiber Optics
Router
ISP Network
Switches and Hubs
Network Stack
A set of hardware or software that provides the infrastructure for a computer.
Language of the Internet
IP
Delivers packets to right computers.
TCP
Delivers information from one network to another.
The Web
URL
Domain Name (registered with ICANN: internet corporation for assigned names and numbers)
DNS
Limitations of the Internet
History of the Internet
1960s DARPA project introduced with the earliest form of Internet called ARPANET.
1970s invention of TCP/IP made possible the interconnection of computers and different networks.
1990s was the start of World Wide Web (WWW).
Limitations of the Internet
IPV4 addresses are limited, only >4 billion.
IPV6 addresses solve this problem with 2128 addresses, but adaptation is slow and expensive.
Network Address Translation (NAT)
Lets an organization use one public IP address and many private IP addresses within the network.
Impact of the Internet
Globalization
The movement that lets governments, businesses, and organizations communicate and integrate together on an international scale.
Internet of Things (IOT)
Smart devices like thermostat, refrigerators, and other home appliances as well as every day smart devices which are being connected to the internet thanks to the IOT.
Privacy and Security
GDPR (General Data Protection Regulation)
COPPA (Children Online Privacy Protection Act)
Copyright Laws
Introduction to Computer Networking
Protocol
A defined set of standards that computers must follow in order to communicate properly.
Computer Networking
The name we’ve given to the full scope of how computer communicate with each other.
TCP/IP five layered network model
The Basics of Networking Devices
Cables
“Connect different devices to each other, allowing data to be transmitted over them.”
Copper Cables
Change voltage to get binary data
The most common forms of copper twisted-pair cables used in networking are Cat5, Cat5e, and Cat6 cables
Crosstalk: “When an electrical pulse on one wire is accidentally detected on another wire.”
Fiber Optic Cables
Contain individual optical fibers, which are tiny tubes made out of glass about the width of a human hair.
Unlike copper cables, fibers use light pulses to send 1s and 0s
Hubs and Switches
Hub
A physical layer device that allows for connections from many computers at once.
Layer 1 device
Collision domain: A network segment where only one device can communicate at a time.
If multiple systems try sending data at the same time, the electrical pulses sent across the cable can interfere with each other.
Network Switch
Layer 2 device
Can direct traffic to a particular node on network, so reduces Collision Domain
Routers
The primary devices used to connect computers on a single network, usually referred to as a LAN or local area network
A device that knows how to forward data between independent networks
Layer 3 (network) device
Core ISP routers (More complex than home routers) form the backbone of the internet.
Servers and Clients
Server Provide data to some client, requesting it
Vague definition, as individual programs running on the computer can also act a server
The TCP/IP Five-Layer Network Model
1) Physical Layer
Represents the physical devices that interconnect computers.
10 Base T, 802.11
Bits
The smallest representation of data that a computer can understand; it’s a one or zero
1s and 0s are sent across the network using modulation
Modulation: A way of varying the voltage of charge moving across the cables
When using modulation in computer networks, it’s called Line coding
Twisted-Pair Cabling and Duplexing
Most common
Twisted-Pair to avoid interference & crosstalk
Duplex Communication: The concept that information can flow in both directions across the globe
Simplex Communication: This is unidirectional
Network Ports and Patch Panels
Twisted-Pair Cables end with the plug which takes the wires and act as a connector
The most common plug RJ45
Network Ports: They are generally directly attached to the devices that make up a computer network
Most network ports have two small LEDs
Activity LED: Would flash when data actively transmitted across the cable
Link LED: Lit when cable properly connected to two devices that are both powered on
Sometimes a network port isn’t connected directly to a device.
Instead, there might be network ports mounted on a wall or underneath your desk.
These ports are generally connected to the network via cables,
run through the walls, that eventually end at a patch panel.
Patch Panel: A device containing many network ports. But it does no other work.
2) Data Link Layer
Responsible for defining a common way of interpreting these signals so network devices can communicate.
Ethernet: The Ethernet standards also define a protocol responsible for getting data to nodes on the same network.
WI-FI
Frames
Mac-Address
Ethernet and MAC Addresses
Ethernet is the most common means of sending data
Ethernet solves Collision domain by using a technique known as carrier sense multiple access with collision detection (CSMA/CD).
CSMA/CD: Used to determine when the communications channels are clear, and when device is free to transmit data
MAC Address: A globally unique identifier attached to an individual network interface
It’s a 48- bit number normally represented by six groupings of two hexadecimal numbers
Hexadecimal: A way to represent numbers using 16 digits
Another way to represent MAC Address is Octet
Octet: In computer networking, any number can be represented by 8 bits
MAC-Address is split in two categories
1) Organizationally Unique Identifier(OUI): The first three octets of a MAC address
2) Vendor Assigned(NIC Cards, Interfaces): Last three octets are assigned by the vendor, depending upon their preferences.
Ethernet uses MAC addresses to ensure that the data it sends has both an address for the machine that sent the transmission, and the one the transmission was intended for.
Uni-cast, Multicast and Broadcast
Uni-cast
A uni-cast transmission is always meant for just one receiving address
It’s done by looking at a specific bit in the destination MAC address
If the least significant bit in the first octet of a destination address is set to zero, it means that an Ethernet frame is intended for only the destination address.
If the least significant bit in the first octet of a destination address is set to one, it means you’re dealing with a Multicast frame.
Broadcast
An Ethernet Broadcast is sent to every single device on a LAN
This is accomplished by a special address known as Broadcast address
Ethernet broadcast are used, so devices can learn more about each other
Ethernet broadcast address used is FF:FF:FF:FF:FF:FF:FF
Dissecting an Ethernet Frame
Data Packet
An all-encompassing term that represents any single set of binary data being sent across a network link
Ethernet Frame
A highly structured collection of information presented in a specific order
The first part of an Ethernet frame is called a preamble.
Preamble: 8 bytes (or 64 bits) long, and can itself split into two sections
Preamble can split into two part of 1 byte of series of 1s and 0s
Last frame in preamble is called Start frame delimiter (SFD)
Signals to a receiving device that the preamble is over and that the actual frame contents will now follow
Next is Destination MAC address
The hardware address of the intended recipient
Followed by Source Address
The next part of Ethernet Frame is EtherType field
16 bits long and used to describe the protocol of the contents of the frame
WE can use VLAN header in place of EtherType field
Indicates that the frame itself is what’s called a VLAN frame
If a VLAN header is present, the EtherType field follows it.
Virtual LAN (VLAN): A technique that lets you have multiple logical LANs operating on the same physical equipment
VLANs, use to segregate different type of network traffic
The next part of Ether frame is payload
In networking terms, is the actual data being transported, which is everything that isn’t a header.
Following payload is, Frame Check Sequence (FCS)
A 4-byte (or 32-bit) number that represents a checksum value for the entire frame
This checksum value is calculated by performing what’s known as a cyclical redundancy check against the frame.
Cyclic Redundancy Check (CRC): An important concept for data integrity, and is used all over computing, not just network transmissions
3) Network Layer
Allows different networks to communicate with each other through devices known as routers.
IP: IP is the heart of the Internet and smaller networks around the world.
Datagram
IP Address
Inter-network
A collection of networks connected together through routers, the most famous of these being the Internet.
4) Transport Layer
Sorts out which client and server programs are supposed to get that data.
TCP/UDP
Segment
Ports
5) Application Layer
There are lots of different protocols at this layer, and as you might have guessed from the name, they are application-specific. Protocols used to allow you to browse the web or send, receive email are some common ones.
HTTP, SMTP etc.
Messages
The Network Layer
IP Addresses
32 bit long
4 octets describe in decimal number
Each octet range from 0 to 255
IP Addresses belong to Networks, not to the devices attached to those networks
When connecting to a network, an IP address is assigned automatically by Dynamic Host Configuration Protocol (DHCP)
IP address assigned by DHCP is called Dynamic IP address
Other type is static IP addresses
In most cases, static IP addresses are reserved for servers and networks devices, while Dynamic IP addresses are reserved for clients
IP Datagrams and Encapsulation
IP Datagram
A highly structured series of fields that are strictly defined.
IP Datagram Header
Version
IPv4 is more common than IPv6
Header Length field
Almost always 20 bytes in length when dealing with IPv4
Service Type field
These 8 bits can be used to specify details about quality of service, or QoS, technologies
Total Length field
Indicates the total length of the IP datagram it’s attached to
Identification field
A 16-bit number that’s used to group messages together
The maximum size of a single datagram is the largest number you can represent with 16 bits which is 65535
If the total amount of data that needs to be sent is larger than what can fit in a single datagram, the IP layer needs to split this data up into many individual packets
Next are closely related Flags and Fragment Offset fields
Flags field
Used to indicate if a datagram is allowed to be fragmented, or to indicate that the datagram has already been fragmented
Fragmentation
The process of taking a single IP datagram and splitting it up into several smaller datagrams
Time to Live (TTL) field
An 8-bit field that indicates how many router hops a datagram can transverse before it’s thrown away
Protocol field
Another 8-bit field that contains data about what transport layer protocol is being used, the most common ones are TCP and UDP
Header checksum field
A checksum of the contents of the entire IP datagram header
Source IP address (32-bits)
Destination IP address (32-bits)
IP Options field
An optional field and is used to set special characteristics for datagrams primarily used for testing purposes
Padding field
A series of zeros used to ensure the header is of correct total size, due to variable size to option field
Encapsulation
IP datagram is basically the payload section of network layer, the process involved is called Encapsulation.
Entire content IP datagram are encapsulated in the form of IP payload of 3rd layer
IP Address Classes
IP addresses can be split into two sections: the network ID and host ID
Address class system
A way defining how the global IP address space is split up.
Three Types of IP addresses, ClassA, ClassB, ClassC
ClassA
Only first octet is used for network ID, rest is used for host ID.
ClassB
Only the first two octets are used for network ID, the rest are used for host ID.
ClassC
First three octets used for network ID, the last one used for host ID.
Address Resolution Protocol (ARP)
A protocol used to discover the hardware address of a node with a certain IP address.
ARP table
A list of IP addresses and the MAC addresses associated with them.
ARP table entries generally expire after a short amount of time to ensure changes in the network are accounted for.
Subnetting
The process of taking a large network and splitting it up into many individual and smaller subnetworks, or subnets.
Class-C subnetting table.
Subnet Masks
32-bits numbers that are normally written out as four octets in decimal.
OR
A way for a computer to use AND operators to determine if an IP address exists on the same network.
A single 8-bit number can represent 256 different numbers, or more specifically, the numbers 0-255.
Subnet ID
Generally, an IP address consists of Network ID and Host ID
In Subnetting world, Host ID is further divided into Subnet ID to identify the subnet mask.
Basic Binary Math
Two of the most important operators are OR and AND.
In computer logic, a 1 represents true and a 0 represents false.
CIDR (Classless Inter-Domain Routing)
Addresses should be continuous
Number of addresses in a block must be in power of 2
First address of every block must be evenly divisible with the size of the block
Demarcation point
To describe where one network or system ends and another one begins.
Routing
Basic Routing Concepts
Router
A network device that forwards traffic depending on the destination address of that traffic.
Routing Tables
Destination Network
Next Hop
Total Hops
Interface
Routing Protocols
Routing protocols fall into two main categories: interior gateway protocols and exterior gateway protocols.
Interior Gateway Protocols
Link state routing protocols
distance-vector protocols
Interior Gateway Protocols
Used by routers to share information within a single autonomous system.
Autonomous system
“A collection of networks that all fall under the control of a single network operator.”
In computer science, a list is known as a vector.
Exterior Gateway Protocol
Internet Assigned Numbers Authority (IANA)
“A non-profit organization that helps manage things like IP address allocation.”
Also, responsible for ASN allocation
Autonomous System Number (ASN)
Numbers assigned to individual autonomous systems.
32-bits long as IP addresses
But has only single decimal block instead of 4 octets
Non-Routable Address Space
IPv4 standard doesn’t have enough IP addresses
There are non-routable address spaces, set aside for internal use only and couldn’t free communicate on the free internet
Transport Layer and Application Layer
The Transport Layer
“Allows traffic to be directed to specific network applications”
It handles multiplexing and demultiplexing through ports
Port
A 16-bit number that’s used to direct traffic to specific services running on a networked computer
Dissection of a TCP Segment
IP datagram encapsulate TCP segment
TCP segment
“Made up of a TCP header and a data section.”
TCP Header
Destination port
The port of the service the traffic is intended for.
Source port
A high-numbered port chosen from a special section of ports known as ephemeral ports.
Sequence number
A 32-bit number that’s used to keep track of where in a sequence of TCP segments this one is expected to be.
Acknowledgement number
The number of the next expected segment.
Data offset field
A 4-bit number that communicates how long the TCP header for this segment is.
Control Flag (See next part)
TCP window
Specifies the range of sequence numbers that might be sent before an acknowledgement is required.
TCP checksum
Operates just like the checksum fields at the IP and Ethernet level.
Urgent pointer field
Used in conjunction with one of the TCP control flags to point out particular segments that might be more important than others. (No real world adoption of this TCP feature)
Options field
It is sometimes used for more complicated flow control protocols. (rarely used in real world)
Padding
Just a sequence of zeros to make sure the data payload section starts at the expected location.
TCP Control Flags and the Three-way Handshake
TCP Control Flags
Not in strict order;
URG (urgent)
A value of one here indicates that the segment is considered urgent and that the urgent pointer field has more data about this. (No particular real world use for this flag)
ACK (acknowledged)
A value of one in this field means that the acknowledgement number field should be examined.
PSH (push)
The transmitting device wants the receiving device to push currently-buffered data to the application on the receiving end asap.
RST (reset)
On the sides in a TCP connection hasn’t been able to properly recover from a series of missing or malformed segments.
SYN (synchronize)
It’s used when first establishing a TCP connection and makes sure the receiving end knows to examine the sequence number field.
FIN (finish)
When this flag is set to one, it means the transmitting computer doesn’t have any more data to send and the connection can be closed.
The Three-way Handshake
Handshake
“A way for two devices to ensure that they’re speaking the same protocol and will be able to understand each other.”
The Four-way Handshake
Not very common
TCP connection when finishes sending data, it sends FIN to request the port closure.
Then receiving end responds with ACK flag and connection closes
Even though the port, on one end, can simply remain open, and the connection ends without closing it
TCP Socket States
Socket
“The instantiation of an end-point in a potential TCP connection.”
Instantiation
“The actual implementation of something defined elsewhere.”
Socket States
LISTEN
A TCP socket is ready and listening for incoming connection.
SYN-SENT
A synchronization request has been sent, but the connection has not been established yet.
SYN-RECEIVED
A socket previously in a LISTEN state has received a synchronization request and sent a SYN/ACK back.
ESTABLISHED
The TCP connection is in working order and both sides are free to send each other data.
FIN-WAIT
A FIN has been sent, but the corresponding ACK from the other end hasn’t been received yet.
CLOSE-WAIT
The connection has been closed at the TCP layer, but the application that opened the socket hasn’t yet released its hold on the socket yet.
CLOSED
The connection has been fully terminated and that no further communication is possible.
Connection-oriented and Connectionless Protocols
Connection-oriented Protocol
“Established a connection, and uses this to ensure that all data has been properly transmitted.”
Connectionless Protocol
The most common one is UDP
Used where data integrity is not super important, i.e., video streaming
System Ports vs. Ephemeral Ports
Port 0 isn’t in use for network traffic, but sometimes used in communications taking place between different programs on the same computer
Ports 1-1024 are referred as system ports or sometimes as well-known ports. These ports represent the official ports for the most well-known network services.
i.e., HTTP uses port-80, FTP uses port-21
Admin level access is needed to listen on these port in mos OSs
Ports 1024-49151 are known as registered ports. These ports are used for lots of other network services that might not be quite as common as the ones that are on system ports.
i.e., Port-3306 is used for many Databases listen on
Some of these ports are registered with IANA but not always
Ports 49152-65535 are known as Private or ephemeral ports. Ephemeral ports can’t be registered with the IANA and are generally used for establishing outbound connections.
When a client wants to communicate with a server, the client will be assigned an ephemeral port to be used for just that one connection, while the server listen on a static system or registered port
Not all OSs follow the ephemeral port recommendation of the IANA
Firewalls
“A device that blocks traffic that meets certain criteria.”
The Application Layer
“Allows network applications to communicate in a way they understand.”
Too many protocols in use at application layer, a hassle to list them all.
i.e., HTTP, SMTP, etc.
The Application Layer and the OSI Model
Session Layer
“Facilitating the communication between actual applications and the transport layer.”
Takes application layer data and hands it off to the presentation layer
Presentation Layer
“Responsible for making sure that the un-encapsulated application layer data is able to understand by the application in question.”
Networking Services
Name Resolution
Why do we need DNS?
Human brain is not good at remembering numbers
So a system called DNS is developed to assign those IP addresses to memorable domain names
Domain Name System (DNS)
“A global and highly distributed network service that resolves strings of letters into IP addresses for you.”
Domain Name
“The term we use for something that can be resolved by DNS.”
The Many Steps of Name Resolution
There are five primary types of DNS servers;
Caching name servers
Recursive name servers
Root name servers (13 root servers all over world)
TLD name servers
Authoritative name servers
Caching and Recursive name servers
The purpose is to store known domain name lookups for a certain amount of time.
Recursive name servers
Perform full DNS resolution requests
Time to live (TTL)
A value, in seconds, that can be configured by the owner of a domain name for how long a name server is allowed to cache an entry before it should discard it and perform a full resolution again
A Typical DNS Query
Anycast
“A technique that’s used to route traffic to different destinations depending on factors like location, congestion, or link health.”
DNS and UDP
DNS, an application layer service, uses UDP
A full DNS lookup with TCP in use, will use 44 total packets
A full DNS lookup with UDP on the other hand require only 8 packets
Error recovery is done by asking again in the UDP, as no error check is present
Name Resolution is Practice
Resource Record Types
A record
“An A record is used to point a certain domain name at a certain IPv4 IP address.”
A single A record is configured for a single domain
But a single domain name can have multiple A records, this allows for a technique known as DNS round-robin to be used to balance traffic across multiple IPs
Round-robin is a concept that involves iterating over a list of items one by one in hastily fashion. The hope is that this ensures a fairly equal balance of each entry on the list that’s selected.
AAAA – Quad A
“Quad A record is used to point a certain domain name at a certain IPv6 IP address.”
CNAME
“A CNAME record is used to redirect traffic from one domain name to another.”
MX record – mail exchange
“This resource record is used in order to deliver e-mail to the correct server.”
SRV record – service record
“It’s used to define the location of various specific services.”
MX record is only used for e-mails, SRC is used for every other service
I.e., caldav (calendar and scheduling service)
TXT record – text
Used to communicate configuration preferences of a domain
Anatomy of a Domain Name
Top level domain (TLD)
The last part of a domain name. E.g. .com, .net etc.
TLDs are handled by non-profit The Internet Corporation for Assigned Names and Number (ICANN)
ICANN is a sister organization to IANA, together both help define and control the global IP spaces and DNS system
Domains
“Used to demarcate where control moves from a TLD name server to an authoritative name server.”
Subdomain
“The WWW portion of a domain.”
Full qualified domain name (FQDN)
When you combine all of these parts together, you have what’s known as this.
A DNS can technically support up to 127 level of domain in total for a single fully qualified domain name
Some other restrictions are, each individual section can only be 63 characters and a complete FQDN is limited to 255 characters
DNS Zones
“An authoritative name server is actually responsible for a specific DNS zone.”
Allow for easier control over multiple level of a domain.
DNS zones are a hierarchical concept. The root name servers are responsible for some even finer-grained zones underneath that.
The root and TLD name servers are actually just authoritative name servers, too. It’s just that the zones that they’re authoritative for are special zones.
E.g., a large company has three servers, one in LA, other in Paris and 3rd one in Shanghai. It will have three zones that and fourth for large company server, so in total 4 DNS server zones.
Zone files
“Simple configuration files that declare all resource record for a particular zone.”
Start of authority (SOA)
“Declares the zone and the name of the name server that is authoritative for it.”
NS records
“Indicate other name servers that might also be responsible for this zone.”
Reverse lookup zone files
These let DNS resolvers ask for an IP and get the FQDN associated with it returned.
Pointer resource record (PTR)
Resolves an IP to a name.
Dynamic Host Configuration Protocol
Overview of DHCP
Every single computer on a modern TCP/IP based network needs to have at least four things specifically configured;
IP address
Subnet mask
Gateway
Name server
DHCP
“An application layer protocol that automates the configuration process of hosts on a network.”
Resolves problem having to manually give an IP address to a device each time, it connects to the internet.
DHCP works on some standards, like Dynamic allocation.
Dynamic Allocation
“A range of IP addresses is set aside for client devices, and one of these IPs is issued to these devices when they request one.”
Under Dynamic allocation, IP of the computer is different every time, it connects to the Internet. Automatic allocation does it**.
Automatic Allocation
“A range of IP addresses is set aside for assignment purposes.”
The main difference is that, the DHCP server is asked to keep track of which IPs it’s assigned to certain devices in the past.
Using this information, the DHCP server will assign the same IP to the same machine each time if possible.
Fixed Allocation
Requires a manually specified list of MAC address and their corresponding IPs.
Network time protocol (NTP) servers
“Used to keep all computers on a network synchronized in time.”
DHCP keeps track of NTP
DHCP in Action
It is an application layer protocol, so it relies on:
Transport layer
Network layer
Data link layer
Physical layer
So, how DHCP works in practice:
DHCP discovery
“The process by which a client configured to use DHCP attempts to get network configuration information.”
It has four steps
The DHCP clients sends what’s known as a DHCP discover message out onto the network.
The response is sent via DHCP offer message.
A DHCP client will respond to a DHCP offer message with a DHCP request message.
DHCP server will receive DHCPREQUEST and respond with DHCPACK message
All of this configuration is known as DHCP lease, as it includes an expiration time. DHCP lease might last for days or only a short amount of time.
Network Address Translation
Basics of NAT
It is a technique, instead of a protocol.
Different hardware vendor implement NAT differently
Network Address Translation (NAT)
“A technology that allows a gateway, usually a router or firewall, to rewrite the source IP of an outgoing IP datagram while retaining the original IP in order to rewrite it into the response.”
Hides the IP of the computer originating the request. This is known as IP masquerading.
To the outside world, the entire space of Network A is hidden and private. This is called One-to-many NAT.
NAT and the Transport Layer
When traffic is outbound, for hundreds, even thousands of computers can all have their IPs translated via NAT to a single IP.
The concept become a bit cumbersome when return traffic is involved.
In inbound traffic, we have potentially hundreds of responses all directed at the same IP, and the router at this IP needs to figure out which response go to which computer.
The simplest way to do this, is port preservation technique.
Port preservation
“A technique where the source port chosen by a client is the same port used by the router.”
Port forwarding
“A technique where specific destination ports can be configured to always be delivered to specific nodes.”
NAT, Non-Routable Address Space and the Limits of IPv4
IANA is in-charge of distributing IPs since 1988. The 4.2 billion have run out since long.
For some time now, the IANA has primarily been responsible with assigning address blocks to the five regional internet registries or RIRs.
AFRINIC servers the continent of Africa. (Mar 2017 – ran out of addresses)
ARIN serves the USA, Canada, and parts of the Caribbean. (Sep 2015 – ran out of addresses)
APNIC is responsible for most of Asia, Australia, New Zealand, and Pacific island nations. (2011 – ran out of addresses)
LACNIC covers Central and South America and any parts of the Caribbean not covered by ARIN. (June 2014 – ran out of addresses)
RIPE serves Europe, Russia, the Middle East, and portions of Central Asia. (Sep 2012 – ran out of addresses)
The IANA assigned the last unallocated /8 network blocks to the various RIRs on February 3, 2011.
Solution is NAT, and Non-Routable Address Space, defined rfc1918.
VPNs and Proxies
Virtual Private Networks
“A technology that allows for the extension of a private or local network to hosts that might not be on that local network.”
A VPN is a tunneling protocol, it’s basically a technique not a strict protocol which involves, using different methods.
VPNs require strict authentication protocols to allow only access to the required clients
VPNs were the first to implement the 2FA on a large scale
VPNs can be used to have site to site connectivity as well
Two-factor authentication
“A technique where more than just a username and password are required to authenticate.”
Proxy Services
“A server that acts on behalf of a client in order to access another service.”
They sit between client and server, providing some additional benefits like;
Anonymity
Security
Content flittering
Increased performance
The most commonly heard are Web proxies intended for web traffic.
Reverse proxy
“A service that might appear to be a single server to external clients, but actually represents many servers living behind it.”
Connecting to the Internet
POTS and Dial-up
Dial-up, Modems and Point-to-Point Protocols
In the late 1970s, two graduate students of Duke University were trying to come up with a better way to connect computers at further distances.
They realized basic infrastructure in the form of telephone lines already existed.
The Public Switched Telephone Network or PSTN also referred as the Plain Old Telephone Service or POTS.
The system they built was called USENET, which was the precursor for Dial-up.
Dial-up
A dial-up connection uses POTS for data transfer, and gets its name because the connection is established by actually dialing a phone number.
Transferring data on dial-ups is done through Modems, stands for Modulator/Demodulator.
Early modems have very low Baud rate
By the late 1950s, computers can generally send data at the rate of 110bps.
When USENET was developed, this rate was increased to 300bps
In the early 1990s, when the dial-up access to the Internet became a household commodity, this rate was increased to 14.4kbps.
Baud rate
“A measurement of how many bits can be passed across a phone line in a second.”
Broadband Connections
What is broadband?
“Any connectivity technology that isn’t dial-up Internet.”
In the late 1990s, it was to become common for most businesses to use T-carrier technologies.
T-carrier technologies require dedicated line, so are used by mainly only businesses.
Other solutions and technologies also available for businesses and normal consumers
DSL
Cable broadband
Fiber connections
T-carrier technologies
“Originally invented by AT&T in order to transmit multiple phone calls over a single link.”
Before Transmission System 1 or short T1, each phone call requires its own copper cable to transmit.
With T1, AT&T invented a way to carry 24 phone calls simultaneously over a single copper cable.
A few years later, T1 technology was repurposed for data transfers.
Over the years, the phrase T1 has come to mean any twisted pair copper connection capable of speeds of 1.544mbps, even if they don’t strictly follow the original Transferring System 1 specifications.
Initially, T1 lines were used to connect telecommunication channels only
But as the Internet grew, many businesses and companies paid to have T1 cables installed for faster connectivity.
Improvements were made by developing a way for multiple T1s to act as a single link.
T3 line was invented which has 28 T1 lines combined, and total speed of 44.736mbps.
Now for small businesses and companies, Fiber connection are more common as they cheaper.
For inner-ISP communications, different Fiber technologies have all replaced older copper-based ones.
Digital Subscriber Lines (DSL)
DSL made possible the occurrence of phone calls and data transfer on the same line, and at the same time.
DSL uses their own modems called Digital Subscriber Line Access Multiplexers (DSLAMs).
Just like dial-up modems, these devices establish data connections across phone lines, but inline dial-up connections, they’re usually long-running.
Two most common DLSs are:
ADSL (Asymmetric Digital Subscriber Line)
Feature different speed of outbound and inbound data. It means faster download speeds and slower upload.
SDSL (Symmetric Digital Subscriber Line)
Same as ADSL, but upload and download speeds are the same.
Most SDSLs have an upper cap of speed, 1.544mbps.
Further developments in SDSL technology have yielded things like:
HDSL (High Bit-rate Digital Subscriber Lines)
These provision speeds above 1.544mbps.
Cable Broadband
The history of both computer and telephone tells a story that started with all communications being wired, but the recent trend is moving towards more traffic as wireless.
But television followed the opposite path. Originally, all television broadcast was wireless, sent out by giant television towers and received by smaller antennas in people’s houses.
You had to be in range of that towers to receive signals, like today you’ve to be in range of cellular tower for cellular communications.
Late 1940s, first television technology was developed.
In 1984, Cable Communications Policy Act deregulated the television industry, started booming, rest of the world soon followed suit.
Cable connections are managed by Cable modems.
Cable modems
The device that sits at the edge of a consumer’s network and connects it to the cable modem, termination system, or CMTS.
Cable modem termination system (CMTS)
Connects lots of different cable connections to an ISPs core network.
Fiber Connections
Fiber achieve higher speed, no degradation in signal transfer.
An electrical signal can only travel a few hundred meters before degradation in copper cable.
While light signal in fiber cables can travel many, many KMs before degradation.
Producing and laying fibers a lot more expensive than copper cables.
Fiber connection to the end consumers, varies tons due to tons of implications.
That’s why the phrase FTTX or fiber to the X was developed.
FTTN: Fiber to the Neighborhood
FTTB: Fiber to the Building, FTTB is a setup where fiber technologies are used for data delivery to an individual building.
FTTH: Fiber to the Home
FTTB and FTTH, both may also refer to as FTTP or Fiber to the Premises
Instead of modem, the demarcation point for Fiber technologies is known as Optical Network Terminator or ONT.
Optical Network Terminator (ONT)
Converts data from protocols, the fiber network can understand, to those that more traditional, twisted-pair copper networks can understand.
WANs
Wide Area Network Technologies
“Acts like a single network, but spans across multiple physical locations.”
It works at Data Link Layer.
WANs are built to be superfast.
Some technologies used in WANs:
Frame Relay
Frame Relay is a standardized wide area network (WAN) technology that specifies the Physical & Data Link Layer of digital telecommunications channels using a packet switching methodology. Originally designed for transport across Integrated Services Digital Network (ISDN) infrastructure, it may be used today in the context of many other network interfaces.
High-Level Data Link Control (HDLC)
HDLC is a bit-oriented code-transparent synchronous data link layer protocol developed by the International Organization for Standardization (ISO). The standard for HDLC is ISO/IEC 13239:2002.
HDLC provides both connection-oriented and connectionless service.
Asynchronous Transfer Mode (ATM)
A standard defined by **American National Standards Institute (ANSI) and ITU-T for digital transmission of multiple types of traffic.
ATM was developed to meet the needs of the Broadband Integrated Services Digital Network (BISDN) as defined in the late 1980s.
Local Loop
“In a WAN, the area between a demarcation point and the ISP’s core network is called Local Loop.”
Point-to-Point VPNs
A popular alternative to WAN technologies
Companies are moving to cloud for services such as email, Cloud Storage. So, expensive cost of WANs is often outnumbered.
They maintain their secure connection to these cloud solutions through Point-to-Point VPNs.
Point-to-Point VPN, typically called Site-to-Site VPN.
Wireless Networking
Introduction to Wireless Networking Technologies
“A way to network without wires.”
IEEE 802.11 Standards or 802.11 family define the most common workings of Wireless networks.
Wireless devices communicate via radio waves.
Different 802.11 generally use the same basic protocol but different frequency bands.
In North America, FM radio transmissions operate between 88 and 108 MHz. This specific frequency band is called FM Frequency Band.
Wi-Fi works at 2.4GHz and 5GHz bands.
There are many 802.11 specifications, but common ones, you might run into are: (In order of when it were introduced)
802.11b
802.11a
802.11g
802.11n
802.11ac
802.11 = physical and data link layers
All specifications operate with the same basic data link protocol. But, how they operate at the 88physical layer** varies.
802.11 frame has a number of fields.
Frame control field
It is 16-bits long and contains a number of subfields that are used to describe how the frame itself should be processed.
Duration field
It specifies how long the total frame is, so the receiver knows how long it should expect to have to listen to this transmission.
The rest are 4 address fields. 6 bytes long.
Source address field
Intended destination
Receiving address
Transmitter address
Sequence control field
It is 16-bits long and mainly contains a sequence number used to keep track of the ordering of frames.
Data payload
Has all the data of the protocols further up the stack.
Frame check sequence field
Contains a checksum used for a cyclical redundancy check, just like how Ethernet does it.
The most common wireless setup includes wireless access point.
Frequency band
“A certain section of the radio spectrum that’s been agreed upon to be used for certain communications.”
Wireless access point
“A device that bridges the wireless and wired portions of a network.”
Wireless Network Configuration
There are few ways wireless networks can be configured
Ad-hoc networks: Nodes speak directly to each other.
Wireless LANS (WLANS): Where one or more access point act as a bridge between a wireless and a wired network.
Mesh Networks: Hybrid of the former two.
Ad-hoc Network
Simplest of the three
In an ad-hoc network, there isn’t really any supporting network infrastructure.
Every device on the network speaks directly to every other device on the network.
Used in smartphones, Warehouses
Important tool during disaster like earthquake, the relief workers, can communicate via ad-hoc network.
Wireless LAN (WLAN)
Most common in business settings
Mesh Network
Most mesh networks are only made up of wireless access points. And are still connected to the wired network.
Wireless Channels
“Individual, smaller sections of the overall frequency band used by a wireless network.”
Channels solve the problem of collision domain.
Collision domain
“Any one of the network segment where one computer can interrupt another.”
Wireless Security
Data packets sent in the air via radio waves need to be protected.
Wired Equivalent Privacy (WEP) was invented to encrypt data packets.
WEP uses only 40-bits for its encryption keys, which could easily be compromised with modern and fast computers.
So, WEP was quickly replaced in most places with WPA or Wi-Fi Protected Access.
WPA, by-default, uses 128-bits key.
Nowadays, the most common wireless encryption method used is WPA2, an update to the original WPA
WPA2 uses 256-bits key.
Another common way of securing wireless traffic is MAC filtering.
Wired Equivalent Privacy (WEP)
“An encryption technology that provides a very low level of privacy.”
MAC filtering
You configure your access points to only allow for connections from a specific set of MAC addresses belonging to devices you trust.
Cellular Networking
Cellular networks have a lot in common with 802.11 networks.
Just like Wi-Fi, they also operate on radio waves.
There are cellular frequency bands reserved for Cellular communications.
Phone frequency waves can travel several KMs.
Mobile Device Networks
Mobile devices use wireless networks to communicate with the Internet and with other devices.
Depending on the device, it might use:
Cellular networks
Wi-Fi
Bluetooth
Internet of Things (IoT) network protocols
IoT Wireless network protocols at the physical layer
IoT devices can use both wired and wireless connections.
Most IoT devices can use at least one of the following network protocols:
Wi-Fi
Wireless Fidelity (Wi-Fi): IEEE 802.11 Standard
Wi-Fi 6 can support up-to 500mbps
The 2.4 GHz frequency extends to 150 feet (45.72 m) indoors, and 300 feet (91.44 m) outdoors.
2.4 GHz may feel congestion due to limited number of channels and high interference from other devices.
5.0 GHz provide stronger signal and has more channels to handle more traffic. The drawback is a limited range of 50 feet (ca. 15 meters) indoors and 100 feet (30.48 m) outdoors.
IEEE 802.15.4
An inexpensive, low-power wireless access technology intended for IoT devices that operate on battery power.
IEEE 802.15.4 uses 2.4 GHz or lower frequencies
IEEE 802.15.4 is normally used for low-rate wireless personal area networks (LR-WPANs) and uses a 128-bits encryption.
ZigBee
ZigBee is an LR-WPANs intended for smart home use. Also adopted globally for commercial use. ZigBee LR-WPAN networks can be accessed through Wi-Fi or Bluetooth.
Thread
Thread: a low latency wireless mesh network protocol based on IPv6.
Don’t use proprietary gateways or translators, making them inexpensive and easier to implement and maintain than other wireless technologies.
Thread is used by Google Nest Hub Max.
Z-Wave
Z-Wave: An interoperable, wireless mesh protocol that is based on low powered radio frequency (RF) communications.
The Z-Wave protocol uses an RF signal on the *908.2MHz frequency and extends to 330 feet (0.1 km).
Z-Wave is inexpensive, reliable, and simple to use. The Z-Wave protocol supports a closed network for security purposes.
Over 3300 types and models of home and business IoT devices are certified to use Z-Wave technology, with more than 100 million devices in use worldwide.
Wireless mesh network (WMN)
Mesh networks are used by many popular wireless IoT network protocols, like Zigbee and Z-Wave, for device communication. Wireless mesh networks use less power than other wireless connectivity options. Wireless mesh is a decentralized network of connected wireless access points (WAP), also called nodes. Each WAP node forwards data to the next node in the network until the data reaches its destination. This network design is “self-healing,” meaning the network can recover on its own when a node fails. The other nodes will reroute data to exclude the failed node. Wireless mesh is a good option for high reliability and low power consumption, which is better for battery powered IoT devices. Wireless mesh networks can be configured to be full or partial mesh:
Full mesh network: Every node can communicate with all the other nodes in the network.
Partial mesh network: Nodes can only communicate with nearby nodes.
Bluetooth
Bluetooth is a widely used wireless network that operates at a 2.45 GHz frequency band and facilitates up to 3 Mbps connections among computing and IoT devices. Bluetooth has a range of up to 100 feet (ca. 30 m) and can accommodate multiple paired connections. It is a good choice for creating a short distance wireless connection between Bluetooth enabled devices. Bluetooth is often used by computing devices to manage, configure, control, and/or collect small amounts of data from one or more close range IoT devices. For example, Bluetooth may be used to control smart home lighting or thermostat IoT devices from a smartphone.
Near-Field Communication (NFC)
NFC is a short-range, low data, wireless communication protocol that operates on the 13.56 MHz radio frequency. NFC technology requires a physical chip (or tag) to be embedded in the IoT device. NFC chips can be found in credit and debit cards, ID badges, passports, wallet apps on smartphones (like Google Pay), and more. A contactless NFC scanner, like a Point-of-Sale (POS) device, is used to read the chip. This scanner communication connection typically requires the IoT device to be within 2 inches (5.08 cm) of the scanner, but some NFC chips have an 8 inch (20.32 cm) range. This short-distance range helps to limit wireless network security threats. However, criminals can carry a portable NFC scanner into a crowded area to pick up NFC chip data from items like credit cards stored inside purses and wallets. To protect against this type of data theft, the cards should be placed inside special NFC/RFID sleeves that make the chips unreadable until they are removed from the sleeves. NFC technology may also be used in the pairing process for Bluetooth connections.
Long Range Wide Area Network (LoRaWAN)
LoRaWan is an open source networking protocol designed to connect battery powered, wireless IoT devices to the Internet for widely dispersed networks.
Troubleshooting and the Future of Networking
Introduction to Troubleshooting and the Future of Networking
After every possible safeguard in place, misconfiguration happens and:
Error still pop-up
Misconfiguration occur
Hardware breaks down
System incompatibilities come to light
Error-detection
“The ability for a protocol or program to determine that something went wrong.”
Error-recovery
“The ability for a protocol or program to attempt to fix it.”
Verifying Connectivity
Ping: Internet Control Message Protocol (ICMP)
ICMP Message
ICMP packet is sent to troubleshoot network issues.
The make-up of an ICMP packet is pretty simple, it has a HEADER and DATA section.
The ICMP HEADER has the following fields:
TYPE: 8-bits long, which specifies what type of data is being delivered. Like, destination unreachable or time exceeded.
CODE: 8-bits long, which indicates a more specific reason than just a type. I.e., destination unreachable type, there are different cods for destination network unreachable or destination port unreachable.
Checksum: 16-bits checksum, that work like every other checksum field.
Rest of Header 32-bits long, this field is optionally used by some specific codes and types to send more data.
Data Payload section for ICMP
The payload for an ICMP packet exists entirely so that the recipient of the message knows which of their transmissions caused the error being reported.
It contains the entire IP Header, and the first 8-bytes of the data payload section of the offending packet.
ICMP isn’t developed for the humans to interact with.
Ping
Ping lets you send a special type of ICMP message called an Echo Request.
Echo Request just asks, hi, are you there?
If the destination is up and running and able to communicate on the network, it’ll send back an ICMP Echo Reply message type.
Traceroute
“A utility that lets you discover the path between two nodes, and gives you information about each hop along the way.”
Two similar tools to traceroute are:
MTR - Linux/macOS
pathping - Windows
Testing Port Connectivity
Sometimes, you need to know if things working at transport layer.
There are two powerful tools for this at your disposal:
netcat - Linux/macOS
Test-NetConnection - Windows
Digging into DNS
Name Resolution Tools
The most common tool is nslookup.
Available on all OSs.
Public DNS Servers
An ISP almost always gives you access to a recursive name server as part of the service it provides.
Many businesses run their own name servers. To give names to the Printers, computers etc. instead of referring them with their IPs.
Another option is using DNS as a service provider. It is becoming more popular.
Some organizations run Public DNS servers, like Google’s 8.8.8.8, Cloudflare’s 1.1.1.1, quad9’s 9.9.9.9 etc.
Some level 3 DNS provider also provide free public DNS servers, but not advertised by them. I.e., 4.2.2.3 etc.
Name servers specifically set up so that anyone can use them, for free.
Most public DNS servers are available globally through anycast.
One should be careful when using Public DNS server, hijacking outbound DNS query, and redirecting the traffic to a malicious website is a common intrusion technique.
Always make sure the name server is run by a reputable company, and try to use the name servers provided by your ISP outside of troubleshooting scenarios.
DNS Registration and Expiration
Registrar
An organization responsible for assigning individual domain names to other organizations or individuals.
Originally, there was only one company, Network Solutions INC responsible for domain Registration.
Network Solutions Inc. and USA government came to an agreement to let other companies also sell domain names.
Hosts Files
The original way that numbered network addresses were correlated with words was through hosts files.
Most modern system, like computers and Mobile phones, still hosts files.
Hosts files are a popular way for the computer viruses to disrupt and redirect users’ traffic.
Hosts File
“A flat file that contains, on each line, a network address followed by the host name it can be referred to as.”
Loopback Address
A way of sending network traffic to yourself.
Loopback IP for IPv4 is 127.0.0.1
Almost all hosts files in existence will, in the very least, contain a line that reads 127.0.0.1 localhost, most likely followed by ::1 localhost, where ::1 is the loop back address for IPv6.
The Cloud
What is The Cloud?
Not a single technology, it’s a technique.
Cloud Computing
“A technological approach where computing resources are provisioned in a shareable way, so that lots of users get what they need, when they need it.”
Or
“A new model in computing where large clusters of machines let us use the total resources available in a better way.”
Hardware virtualization is at the heart of cloud computing.
Hardware virtualization platforms deploy what’s called a hypervisor.
Virtualization
“A single physical machine, called a host, could run many individual virtual instances, called guests.”
Hypervisor
“A piece of software that runs and manages virtual machines, while also offering these guests a virtual operating platform that’s indistinguishable from an actual hardware.”
Public Cloud
A large cluster of machines runs by another company.
Private Cloud
Used by a single large corporation and generally physically hosted on its own premises.
Hybrid Cloud
A term used to describe situations where companies might run a thing like their most sensitive proprietary technologies on a private cloud, while entrusting their less-sensitive servers to a public cloud.
Everything as a Service
X as a Service, where X can mean many things.
Infrastructure as a Service (IaaS)
You shouldn’t have to worry about building your own network or your own servers.
Platform as a Service (PaaS)
A subset of cloud computing where a platform is provided for customers to run their services.
Software as a Service (SaaS)
A way of licensing the use of software to others while keeping that software centrally hosted and managed.
Gmail for Business
Office 365 Outlook
Cloud Storage
Operate in different geographic region.
Pay as you use
Good for backup
IPv6
IPv6 Addressing and Subnetting
IPv4 was run out of new IPs
IPv5 was an experimental protocol that introduced the concept of connections.
IPv6 = 128 bits, written as 8 groups of 16-bits each. Each one of these groups is further made up of four hexadecimal numbers.
Full IPv6 address looks like this
Reserved IPv6 range is as follows, for education, documentation, books, courses etc.
Shortening of an IPv6 address
Two rules
Remove any leading zeros from a group
Any number of consecutive groups composed of just zeros can be replaced with two colons ::.
Any IPv6 address begins with FF00:: is used for multicast.
Any IPv6 address begins with FE80:: is used for Link-local unicast.
The first 32-bits of IPv6 are network ID, and last are host ID.
IPv6 uses the same CIDR notation for subnet mask.
Multicast
A way of addressing groups of hosts all at once.
Link-local unicast
Allow for local network segment communication and are configured based upon a host’s MAC address.
IPv6 Headers
Header, much simpler than IPv4 header.
IPv6 header has the following components:
Version field
A 4-bit field that defines what version of IP is in use.
Traffic class field
An 8-bit field that defines the type of traffic contained within the IP datagram, and allows for different classes of traffic to receive different priorities.
Flow Label Field
A 20-bit field that’s used in conjunction with the traffic class field for routers to make decisions about the quality of service level for a specific datagram.
Payload length field
A 16-bit field that defines how long the data payload section of the datagram is.
Next header field
A unique concept of IPv6, and needs a little extra explanation. It defines what header is up next after that. To help reduce the problems with additional data that IPv6 addresses impose on the network, the IPv6 header was built to be a short as possible. One way to do that is to take all the optional fields and abstract them away from the IPv6 header itself. The next header field defines what kind of header is immediately after this current one. These additional headers are optional, so they’re not required for a complete IPv6 datagram. Each of these additional optional headers contain a next header field and allow for a chain of headers to be formed if there’s a lot of optional configuration.
Hop limit
An 8-bit field that’s identical in purpose to the TTL field in an IPv4 header.
Source Address : 128-bits
Destination Address : 128-bits
Data Payload section
IPv6 and IPv4 harmony
Not possible for whole Internet to switch to IPv6 in no time.
So, IPv6 and IPv4 traffic need to coexist during the transition period.
This is possible with IPv4 mapped address space. The IPv6 specifications have set aside a number of addresses that can be directly correlated to an IPv4 address.
More important is IPv6 traffic needs to travel to IPv4 servers.
This is done through IPv6 tunnels.
IPv6 tunnels
Servers take incoming IPv6 traffic and encapsulate it within traditional IPv4 datagram.
They consist of IPv6 tunnel servers on either end of a connection. These IPv6 tunnel servers take incoming IPv6 traffic and encapsulate it within traditional IPv4 datagrams. This is then delivered across the IPv4 Internet space, where it’s received by another IPv6 tunnel server. That server performs the de-encapsulation and passes the IPv6 traffic further along in the network.
IPv6 tunnel broker
Companies that provide IPv6 tunneling endpoints for you, so you don’t have to introduce additional equipment to your network.
-Filter parameter is used with ls so search for particular files in a directory.
The -Filter parameter will filter the results for file names that match a pattern.
ls <path\to\the\file> -Recurse -Filter *.exe
The asterisk means match anything, and the .exe is the file extension for executable files in Windows.
Linux: Searching within Files
To search in files
grep <Search String> <path/to/the/file>
To search through multiple files at once
grep <Search String> *.txt
Windows: Input, Output, and the Pipeline
echo hello_word > hello.py
The echo is an alias for PowerShell command Write-Output.
Every Windows process and every PowerShell command can take input and can produce output. To do this, we use something called I/O streams or input output streams.
I/O streams are
stdin
stdout
stderr
The symbol > is something we call a Redirector operator that let us change where we want our stdout to go.
The symbol » is used to not create a new file, just append the stdout
echo 'Hello Planet' >> hello.py
| Pipe operator is used to redirect the stdout of one command to stdin of another command.
cat hello.py | Select-String planet
To put new stdout to a new file.
cat hello.py | Select-String pla > planet.txt
If we don’t want to see error in CLI, to get them in a file
rm secure_file 2> error.txt
All the output streams are numbered, 1 is for stdout and 2 for stderr
If we don’t care about error messages and don’t want to save them in a file, we can redirect them to a null variable (a black hole for stderr)
rm secure_file 2> $null
Linux: Input, Output, and the Pipeline
On Linux, stdin operator can be used via symbol <.
cat < SomeFile.py
Here we are using < operator for file input instead of keyboard input.
To redirect error message to a file
ls /dir/fake_dir 2> error_output.txt
To filter out error message completely without saving
ls /dir/fake_dir 2> /dev/null
Windows and Linux Advanced Navigation
For more advance navigation, regex is used.
Regular expression (Regex)
Used to help you do advance pattern-based selections.
Users and Permissions
Users and Groups
User, Administrators, and Groups
Two different types of users
Standard user
Admin
Users are put into different groups, according to level of permissions and ability to do certain tasks.
1) Standard user
One who is given access to a machine but has restricted access to do things like install software or change certain settings.
2) Administrator (Admin)
A user that has complete control over a machine.
Windows: View User and Group Information
To view user and groups information, Computer management application is used.
In an Enterprise environment, you can manage multiple machines in something called a domain.
You can manage admin tasks while being logged in as a normal user. This is done through User Access Control (UAC) prompt.
Windows domain
A network of computers, users, files, etc. that are added to a central database.
User Access Control (UAC)
A feature on Windows that prevents unauthorized changes to a system.
Windows: View User and Group Information using CLI
To check all users on the system and either admin access enabled or not.
Get-LocalUser
To get all the groups present on a local machine
Get-LocalGroup
To check members of an individual group
Get-LocalGroupMember Administrator
Linux: Users, Superuser and Beyond
To see all groups, who are their members
cat /etc/group
It shows information something like this
sudo:x:27:user1, user2, user3
First field is a group name
2nd is password but redacted
3rd is a group id
4th is a list of users in a group
To view all users on a machine
cat /etc/passwd
Most of these accounts are system processes running the computer.
Windows: Passwords
An admin shouldn’t know the password of the user using it.
But as an admin to manage users passwords, computer management application is used.
To change user’s password from CLI
net user <username> <password>
To interactively change the password
net user <username> *
To force user itself to change its password on next logon
net user <username> /logonpasswordchg:yes
Linux: Passwords
To change a password on Linux
sudo passwd <username>
To force a user to change his/her password
sudo passwd -e <username>
Windows: Adding and Removing Users
To add users
net user <username> * /add
To add a new user and forcing him/her to change its password on new logon
net user <username> password /add /logonpasswordchg:yes
To remove a local user
net user <username> /del
OR
Remove-LocalUser <username>
Linux: Adding and Removing Users
To add a user
sudo useradd <username>
To remove a user
sudo userdel <username>
Permissions
Windows: File Permissions
On Windows, files and directory permissions assigned using Access Control Lists or ACLs. Specifically, we’re going to be working with Discretionary Access Control Lists or DACLs.
Windows files and folders can also have System Access Control Lists or SACLs assigned to them.
SACLs are used to tell Windows that it should use an event log to make a note of every time someone accesses a file or folder.
Windows allow certain permissions to be set for files and folders.
Read
The Read permission lets you see that a file exists, and allow you to read its contents. It also lets you read the files and directories in a directory.
Read & Execute
The Read & Execute permission lets you read files, and if the file is an executable, you can run the file. Read & Execute includes Read, so if you select Read & Execute, Read will be automatically selected.
List folder contents
List folder contents is an alias for Read & Execute on a directory. Checking one will check the other. It means that you can read and execute files in that directory.
Write
The Write permission lets you make changes to a file. It might be surprising to you, but you can have write access to a file without having read permission to that file!
The Write permission also lets you create subdirectories, and write to files in the directory.
Modify
The Modify permission is an umbrella permission that includes read, execute, and write.
Full control
A user or group with full control can do anything they want to the file! It includes all the permissions to Modify, and adds the ability to take ownership of a file and change its ALCs
To view file permissions in a CLI, Improved change ACLs command icacls is used
To view more options and their explanation
icacls /? #icacls is a old dos command
icacls <filepath>
Linux: File Permissions
There are three different permissions you can have on Linux
Read – This allows someone to read the contents of a file or folder.
Write – This allows someone to write information to a file or folder.
Execute – This allows someone to execute a program.
To see file permissions
ls -l <filepath>
Windows: Modifying Permissions
To modify permissions
icacls <filepath> /grant 'Everyone:(OI)(CI)(R)'
Everyone gives permissions to literally everyone of the computer including guest users, to avoid this
This is a special type of user that’s allowed to use the computer without a password. Guest users are disabled by default. You might enable them in very specific situations.
Linux: Modifying Permissions
The permissions are changed by chmod command
The owner, which is denoted by a “u”
The group the file belongs to, which is denoted a “g”
Or other users, which is denoted by an “o”
To change execute permission
chmod u+x <filepath>
chmod u-x <filepath>
To add/remove multiple permissions to file
chmod u+rx <filepath>
To change permissions for owner, the group, and others
chmod ugo+r <filepath>
This format of changing permissions is called symbolic format.
Other method is changing permissions numerically, which is faster.
The numerical equivalent of rwx is:
4 for read or r
2 for write or w
1 for execute or x
To change permissions numerically
chmod 745 <filepath>
1st is for user
2nd is for group
3rd is for other
To change ownership of a file
sudo chown <username> <filepath>
To change group of a file
sudo chgrp <username> <filepath>
Windows: Special Permissions
The permissions we looked so far are called simple permissions.
Simple Permissions
Simple permissions are actually sets of special, or specific permissions.
When you set the Read permission on a file, you’re actually setting multiple special permissions.
To see special permissions, icacls command is used
icacls <filepath>
Linux: SetUID, SetGID, Sticky Bit
SetUID is a special permission, use to allow a file to be run as the owner of the file.
To apply SetUID
sudo chmod u+s <filepath>
The numerical value for SetUID is 4
sudo chmod 4755 <filepath>
SetGID is a special permission which allow a user to run a particular file in a group member though the user isn’t part of that group.
sudo chmod g+s <filepath>
The numerical value for SetGID is 2.
sudo chmod 2755 <filepath>
Sticky Bit is a special permission, use to allow anyone to write to a file or folder but can’t delete it.
sudo chmod +t <filepath>
The numerical value for Sticky bit is 1.
sudo chmod 1755 <filepath>
Package and Software Management
Software Distribution
Windows: Software Packages
On Windows, software is usually packaged in a .exe executable file.
Software is packaged according to Microsoft Portable Executable or PE format.
Executable not only include install instructions but also things like text or computer code, images that the program might use, and potentially something called an MSI file.
For precise granular control over installation, you can use executable with a custom installer packaged in something like setup.exe.
On the other hand, .msi installer along with Windows installer program has some strict guidelines to be followed.
Windows store uses a package format called APPX.
To install an executable from CLI, type its name.
Executable file (.exe)
Contain instructions for a computer to execute when they’re run.
Microsoft install package (.msi)
Used to guide a program called the Windows Installer in the installation, maintenance, and removal of programs on the Windows operating system.
Linux: Software Packages
Fedora use Red-Hat package manager package or (.RPM).
Debian uses .deb file.
To install a standalone .deb package
sudo dpkg -i abc.deb
To remove package on Debian
sudo dpkg -r abc.deb
To list .deb Packages
dpkg -l
Mobile App Packages
Software is distributed as Mobile Applications or Apps.
Mobile phones use App stores for software installation
Enterprise App management allows companies to distribute their custom apps internally.
Enterprise Apps are managed through Mobile Device Management or (MDM) service.
Another way to install apps is through side-loading
Apps stored their files to storage assigned to them called cache.
Clearing the cache will remove all changes to the settings, and sign out of any accounts that the app was signed-into.
Clearing the cache might not be the first step in application troubleshooting, but it is handy in desperate times.
App Stores
A central, managed marketplace for app developers to publish and sell mobile apps.
Side-loading
Where you install mobile apps directly, without using an app store.
Mobile apps are standalone software packages, so they contain all their dependencies.
To compress files from CLI
Compress-Archive -Path <filepath: files to be compressed> <filepath: Where to save compressed file>
Windows: Archives
7-zip is a popular Windows tools for archives management.
Archive
Comprised of one or more files that’s compressed into a single file.
Popular archive types are .tar, .zip, .rar.
Package archives
The core or source software files that are compressed into one file.
Linux: Archives
p7zip is the Linux version of 7-zip.
To extract a file, use the command 7z and the flag e for extract and then the file you want to extract.
7z e <filepath>
Windows: Package Dependencies
A game might depend on rendering library for graphic and physics engine for correct movements.
On Windows, these shared libraries are called Dynamic Link Libraries or DLL.
A useful feature of DLL is, one DLL can be used by ‘many’ different programs.
In the past, when one DLL gets updated, some programs dependent on it, would become unusable, as they didn’t know how to update the DLL for next version number.
On modern systems, more shared libraries and resources on Windows are managed by something called side-by-side assemblies or SxS
Most of these shared libraries are stored in C:\Windows\WinSxS
If an application needs to use a shared library, this is declared in a file called manifest.
SxS stores multiple versions of DLLs, so programs dependent on them remain functioning.
Using a cmdletFind-Package, can locate software, along with its dependencies, right from the command line.
Having Dependencies
Counting on other pieces of software to make an application work, since one bit of code depends on another, in order to work.
Library
A way to package a bunch of useful code that someone else wrote.
cmdlet
A name given to Windows PowerShell commands
Linux: Package Dependencies
dpkg on Debian and Debian-based Linux systems doesn’t handle dependencies automatically
So, package managers come to your rescue for automatic dependency resolution.
Package managers
Come with the works to make package installation and removal easier, including installing package dependencies.
Package Managers
Windows: Package Manager
“Makes sure that the process of software installation, removal, update, and dependency management is as easy and automatic as possible.”
Chocolatey is a third party package manager for Windows.
NuGet is another third party package manager for Windows.
Based on Windows PowerShell
Configuration management tools like SCCM & puppet integrate with Chocolatey.
APT comes with default distro software repo linked.
To add other repos, we add them through /etc/apt/sources.list
Ubuntu and based-distros have additional repos in the form of PPAs
PPAs are not as vetted by distros, so use them careful, or you might get infected, or break your installation with defected programs.
Personal Package Archive (PPA)
A Personal Package Archive or PPA is a software repo for uploading source packages to be built and published as an Advanced Packaging Tool (APT) repo by Launchpad.
What’s happening in the background?
Windows: Underneath the Hood
When click an .exe to install, next step depends on the developer, how he, setups the installation instructions for his/her program.
If an EXE contains code for a custom installation that doesn’t use the Windows installer system, then the details of what happens under the hood will be mostly unclear. As the most Windows’ software are closed source packages.
So, you can’t really see what instructions are given, but tools like Process Monitoring provided by Microsoft CIS internal toolkit.
It will show any activity the installation executable is taking, like the files it writes and any process activity it performs.
In case of MSI files, though code is closed source, but developers need to stick to strict guidelines.
Orca tool lets you examine, create and edit MSI files, it’s part of Windows SDK.
Linux: Underneath the Hood
Installations are clearer than Windows due to open nature of the OS
Software usually consists of setup script, actual app files and README.
Most devices you’ve got on your computer will be groped together according to some broad categories by Windows.
This grouping typically happens automatically when you plug in a new device, Plug&Play or PnP system.
When a new device plugs-in, Windows asks for its hardware ID.
When it gets the right hardware ID, it searches for its drivers in some known locations, starting with a local list of well-known drivers. Then goes on to Windows Update or the driver store.
Other times devices comes with custom drivers.
Device Software Management
Windows: Devices and Drivers
Device Manager console is used in GUI, for devices and drivers management.
You can open it by searching devmgmt.msc from the search console, or right-click on This PC and click Device Manager.
Driver
Used to help our hardware devices interact with our OS.
Linux: Devices and Drivers
On Linux, everything is considered a file, even the hardware devices.
When a new device is connected, a file is created in the /dev/ directory.
There are lots of devices in /dev/ directory, but not all of them are physical devices.
The more common one in there are character devices and block devices.
As in long ls listing - in the front represents file, and d represents directory, in /dev/, c shows block devices, and b represents block devices.
Device drivers on Linux are easy at the same time difficult to install.
Linux kernel is monolithic software, that contains drivers for popular devices as well.
The devices that don’t have driver backed in the kernel, will have drivers in the form of kernel modules.
Character Devices
Like a keyboard or a mouse, transmit data character by character.
Block Devices
Like USB drives, hard drives and CDROMs, transfer blocks of data; a data block is just a unit of data storage.
Pseudo Devices
Device nodes on Unix-like OSs, that don’t necessarily have to correspond to physical devices. I.e. /dev/null, /dev/zero, /dev/full etc.
Windows: Operating System Updates
When your OS vendor discovers a security hole in a system, they prepare a security patch.
As an IT specialist, it’s important to keep your system up-to-date with security and other patches, though feature updates can be delayed for reasons.
The Windows Update Client service runs in the background and download and install security patches and updates.
Security Patch
Software that’s meant to fix up a security hole.
Linux: Operating System Updates
For Ubuntu based distros
sudo apt update && sudo apt upgrade
To be on the latest security patches, you need to run and update newer kernels.
To see your kernel version
uname -r
-r is a flag, to know kernel release, to know kernel version you have.
Filesystems
Filesystem Types
Review of Filesystems
FAT32 reading and writing data to Windows, Linux, and macOS
Shortcomings are, max file size supported is 4 GB
Max file system 32 GB
Disk Anatomy
A storage device can be divided into partitions
You can dual-boot Windows and Linux, with disk partitions dedicated for each.
Other component is Partition table
Two main Partition tables are used
Master Boot Record (MBR)
GUID Partition Table (GPT)
For new booting standard UEFI, you need GPT table.
Partition
The piece of a disk that you can manage.
Partition Table
Tells the OS how the disk is partitioned.
Windows: Partitioning and Formatting a Filesystem
Windows ships with a great tool, Disk Management Utility.
To manage disks from CLI, a tool called Diskpart is used.
Diskpart
Typing Diskpart in the CLI, will open an interactive shell.
Next, type list disk to list out all the storage devices on your computer
Then to select a disk:
select disk <Disk ID>
After to wipe all volumes and files from the disk, type clean in the interactive shell.
To create blank partition in a disk
create partition primary
Then, to select the newly created partition
select partition 1
To mark it as active, simply type active.
To format the disk with filesystem:
format FS=NTFS label=<Label the Disk> quick
Cluster
Cluster (allocation unit size) is the minimum amount of space a file can take up in a volume or drive.
Cluster size
Cluster size is the smallest division of storage possible in a drive. Cluster size is important because a file will take up the entire size of the cluster, regardless of how much space it actually requires in the cluster.
For example, if the cluster size is 4kb (the default size for many formats and sizes) and the file you’re trying to store is 4.1kb, that file will take up 2 clusters. This means that the drive has effectively lost 3.9 Kb of space for use on a single file.
Volume
A single accessible storage area with a single file system; this can be across a single disk or multiple.
Partition
A logical division of a hard disk that can create unique spaces on a single drive. Generally used for allowing multiple operating systems.
Windows: Mounting and Unmounting a Filesystem
When you plug a USB drive, it shows up in the list of your devices, and you can start using it right away.
When done using, safely eject it.
Mounting
Making something accessible to the computer, like filesystem or a hard disk.
Linux: Disk Partitioning and Formatting a Filesystem
There are different disk partitioning CLI tools
parted Can be used in both interactive and in command line.
Parted
To list the devices
sudo parted -l
To run parted in interactive mode on some disk
sudo parted /dev/sdX
You can use help to see different commands used in the interactive mode.
To format the partition with filesystem using mkfs
sudo mkfs -t ext4 /dev/sdXx
Linux: Mounting and Unmounting a Filesystem
To mount the previously formatted disk
sudo mount /dev/sdXx /my_disk/
To unmount the disk
sudo umount /dev/sdXx
File System table (fstab)
To permanently mount a disk, we need to make changes in a fstab file.
The fstab configuration table consists of six columns containing the following parameters:
Device name or UUID (Universally Unique ID)
Mount Point: Location for mounting the device
Filesystem Type
Options : list of mounting options in use, delimited by commas.
Backup operation of dump – this is an outdated method for making device or partition backups and command dumps. It should not be used. In the past, this column contained a binary code that signified:
0 = turns off backups
1 = turns on backups
Filesystem check (fsck) order or Pass – The order in which the mounted device should be checked by the fsck utility:
0 = fsck should not run a check on the filesystem
1 = mounted device is the root file system and should be checked by the fsck command first.
2 = mounted device is a disk partition, which should be checked by fsck command after the root file system.
Example of an fstab table:
To get a UUID of a disk
sudo blkid
Windows: Swap
Windows use Memory Manager to handle virtual memory.
On Windows, pages saved to disk are stored in a special hidden file on the root partition of a volume called pagefile.sys
Windows provides the way to modify size, number, and location of paging files through a control panel applet called System Properties.
Virtual memory
How our OS provides the physical memory available in our computer (like RAM) to the applications that run on the computer.
Linux: Swap
You can make swap, with tools like fdisk, parted, gparted etc.
To make it auto-mount on system start, add its entry in the fstab file.
Swap space
On Linux, the dedicated area of the hard drive used for virtual memory.
Windows: Files
NTFS uses Master File Table or MFT to represent the files.
Every file on the system has at least one entry on the MFT
Shortcut is an MFT entry which takes us to the specific location of a file, which it is a shortcut of.
Other methods to link to files are:
Symbolic Links: OS treats Symbolic links just like the files themselves
To create a symbolic link:
mklink <Symlink Name> <Original File Name>
Hard Links: When you create a hard link in NTFS, an entry is added to the MFT that points to the linked file record number, not the name of the file. This means the file name of the target can change, and the hard link will still point to it.
To create a hard link:
mklink /H <Hard link Name> <Original File Name>
File metadata
All the data, other than the file contents.
Master File Table (MFT)
The NTFS file system contains a file called the master file table or MFT, There is at least one entry in the MFT for every file on an NTFS file system volume, including the MFT itself.
All information about a file, including its size, time and date stamps, permissions, and data content, is stored either in the MFT table, or in space outside the MFT that describe by MFT entries.
As files are added to an NTFS file system volume, more entries are added to the MFT and the MFT increases in size. When files are deleted from an NTFS file system volume, their MFT entries are marked as free and may be reused.
Linux: Files
In Linux, metadata and files organize into a structure called an inode.
Inode doesn’t store filename and the file data.
We store inodes in an inode table, and they help us manage the files on our file system.
Shortcut on Linux, referred to as Softlink.
To create a soft link:
ln -s <File Name> <Softlink Name>
To create a hard link:
ln <File Name> <Hardlink Name>
If you move a file, all the Softlinks, will be broken
Windows: Disk Usage
To check disk usage, open up, computer management utility.
Disk cleanup is done through CleanManager.exe, to clear out, cache, log file, temporary files, and old file etc.
Another disk health feature is Defragmentation.
This beneficial for spinning hard drives, and less of important for SSDs.
Defragmentation in spinning drives is handled by task schedulers on Windows automatically, and you don’t need to worry about manual intervention most of the time.
To start manual defragmentation, start Disk defragmenter tool.
For Solid state drives, the system can use the Trim feature to reclaim unused space.
For CLI, disk cleanup du tool is used
Defragmentation
The idea behind disk defragmentation is to take all the files stored on a given disk, and reorganize them into neighboring locations.
Linux: Disk Usage
To see disk usage:
du -h
du List file sizes of current directory if no option is specified.
To see free disk space:
df -h
Linux generally does a good job of avoiding fragmentation, more than Windows.
Windows: File-system Repair
Ejecting a USB drive is necessary, as the file copying/moving might still be running in the background, even after successful copy/move prompt.
When we read or write something to a drive, we actually put it into a buffer, or cache, first.
If you don’t give enough time for data to be moved away from buffer, you may experience a Data corruption.
Power outage, system failure, or some bug in the OS or the program, can also cause data corruption.
NTFS has some advanced feature in the form of Data journaling, which avoid data corruption or even attempts data recovery in case of failure.
Minor errors and data corruptions are self healed by NTFS.
To check self-heal status:
fsutill repair query C:
In case of catastrophic failure, run chkdsk tool in PowerShell as an admin, by default it will run in read-only mode. So it will only report the error, and not fix it.
chkdsk
To fix the errors
chkdsk /F <Drive Path>
Most of the time, you won’t need to run chkdsk manually, and OS will handle it for you running it, and then fixing the errors, by looking the at the NTFS Journaling log.
Data buffer
A region of RAM that’s used to temporarily store data while it’s being moved around.
Linux: File-system Repair
Run fsck on unmounted drive, otherwise it will damage it.
sudo fsck /dev/sdX
On some systems, fsck runs automatically on boot.
Operating Systems in Practice
Remote Access
Remote Connection and SSH
The most popular SSH client on Linux is **OpenSSH program.
The most popular SSH program on Windows is PuTTY.
Another way to connect to a remote machine is VPN.
On Linux, GUI remote connection can be established through programs like RealVNC.
On MAC, remote GUI connections are possible via Microsoft RDP on Mac.
Remote Connection
Allows us to manage multiple machines from anywhere in the world.
Secure shell (SSH)
A protocol implemented by other programs to securely access one computer from another.
We can authenticate via password in SSH.
But more secure way is the use of SSH keys. An SSH key is a pair of two keys:
Private
Public
Virtual private network (VPN)
Allows you to connect to a private network, like your work network, over the Internet.
Remote Connections on Windows
Microsoft has built Remote Desktop Protocol or RDP for GUI remote connections.
A client named Microsoft Terminal Services Client or mtsc.exe is used for remote RDP connections.
PuTTY
A free, open source software that you can use to make remote connections through several network protocols, including SSH.
To connect via PuTTY in a CLI:
putty.exe -ssh username@ip_address <Port Number> # Port number is 22 by default for SSH connections
To enable remote connection on a pc go-to:
MY PC > Properties > Remote Settings
Remote Connection File Transfer
Secure copy (SCP)
A command you can use on Linux to copy files between computers on a network.
To copy file from local computer to remote:
scp <filepath> username@ip_address:location
Remote Connection File Transfer on Windows
PuTTY comes with PuTTY Secure Copy Client or pscp.exe.
pscp.exe <filepath> username@ip_address:location
To transfer files via PuTTY is a little time-consuming, so Windows came up with the concept of ShareFolders.
To share folders via CLI:
net share <ShareName>=<drive>:<DirectoryPath> /grant:everyone,full
To list currently shared folders on your computer:
net share
Virtualization
Virtual Machines
To manage virtual instances, we can use FOSS program Virtual Box.
Virtual Instance
A single virtual machine.
Logging
System Monitoring
Log
A log is a system diary of events happening on the system.
Logging
The act of creating log events.
The Windows Event Viewer
It stores all the events happening on a Windows computer.
Linux logs
The logs on Linux are stored in /var/log directory.
One log file that pretty much everything on the system is /var/log/syslog
The utility logrotate is used for log cleanup by the system.
Centralized logging is used for parsing multiple systems log files in a single place.
Working with Logs
The logs are written in a very standard way, so we don’t need to go through each and every bit of them to troubleshoot problems, all you need to do is look for specific things.
Logs can be searched with keywords like, error.
Name of the troublesome program.
The troubleshooting technique is viewing logs in the real time, to find the out the specific errors causing the program to fail.
To see real-time logs on Linux:
tail -f /var/log/syslog
Operating System Deployment
Imaging Software
It is extremely cumbersome to install OSs on new machines via USB drive formatted with OS.
In IT world, tools are used to format a machine with an image of another machine, which includes everything, from the OS to the settings.
Operating Systems Deployment Methods
Disk cloning tools are used to obtain an image of a computer OS and settings. Some tools are:
Clonezilla (FOSS)
Symantec Ghost (Commercial)
Different disk cloning tools offer different methods to clone systems
Disk-to-disk cloning
Let’s use Linux CLI tool dd to copy files from a disk to make a clone.
Another useful CLI tool is uptime, which show info about the current time, how long your computer running, how many users are logged on, and what the load average of your machine is.
When ejecting a USB drive, you get the error “Device or resource busy” though none of the files on the USB drive is in use or opened anywhere, or so you think. Using the lsof lists open files and what processes are using them.
It is great for tracking down pesky processes that are holding open files.
System Administration and IT Infrastructure Services
This courses is sub-divided into 6 weeks of study program, which has 5 sub-topics and a final project.
Subsections of SysAmin and IT Infrastructure Services
What is System Administration?
System Administration
The field in IT that’s responsible for maintaining reliable computer systems in a multi-user environment.
What is System Administration?
IT Infrastructure
IT Infrastructure encompasses the software, the hardware, network, services required for an organization to operate in an enterprise IT environment.
Sysadmins work in the background to make sure the company’s IT infrastructure is always up and running.
In large companies, sysadmin can be split-up into:
Network Administrators
Database Administrators
Servers Revisited
Sysadmins, responsible for managing things like
Email
File storage
Running a website and more.
These services are stored on servers.
Server
Software or a machine that provides services to other software or machines.
Servers include:
Web server
Email server
SSH server
The servers can be of three of the most common types in terms of their space efficiency:
Tower Servers
Rack Servers
Blade Servers
KVM Switch
Keyboard, Video, and Mouse (KVM) is an industry standard hardware device for connecting directly to the servers.
The Cloud
Cloud computing, a concept in which you can access your files, emails etc. from anywhere in the world.
Cloud is not a magical thing, rather hundreds and even thousands of computer act as a server to form a cloud, somewhere in the data center.
Data Center
A facility that stores hundreds, if not thousands, of servers.
System Administration
Organizational Policies
In a small company, it’s usually a Sysadmin’s responsibility to decide what computer policies to use.
In larger companies with hundreds of employees or more, this responsibility typically falls under the chief security officer or CSO.
User and Hardware Provisioning
In other responsibilities, Sysadmins have is managing users and hardware.
There are four stages of hardware life cycle
Routine Maintenance
To affectively update a fleet of hardware, you set up a Batch update, once every month or so, depending upon company policies.
Good practice is to install security and critical bug fixes routinely.
Vendors
Not only do sysadmins in a small company work with using computers, they also have to deal with printers and phone, too.
Whether your employees have cellphones or desk phones, their phone lines have to be setup.
Other hardware generally used in companies is:
Printers
Fax machines
Audio/video conferencing equipment
Sysadmins might be responsible for making sure printers are working or, if renting a commercial printer, they have to make sure that someone can be on site to fix it.
Setting up businesses account with vendors like **Hewlett Packard, Dell, Apple, etc. is usually beneficial since they generally offer discounts for businesses.
Troubleshooting and Managing Issues
While working in an organization, sysadmins have to constantly troubleshoot and fix issues on machines.
You need to prioritize the issues all the time.
In Case of Fire, Break Glass
As a sysadmin, you need to have some recovery plan for companies critical data and IT infrastructure in case of a critical failure.
Applying Changes
With Great Power Comes Great Responsibility
Avoid using administrator’s rights for tasks that don’t require them.
When using Admin rights, make sure to:
Respect the privacy of others.
Think before you type or do anything.
With great power comes great responsibility.
Documenting what you do is pretty important, for future you or someone else in the company to troubleshoot the same issues.
script Command used to record a group of commands as they’re being issued on Linux
Start-Transcript is an equivalent command on Windows
We can record the desktop with some GUI application.
Some commands are easy to rollback than others, so be careful of what you’re doing.
Script
In the case of script you can call it like this:
script session.log
This writes the contents of your session to the session.log file. When you want to stop, you can write exit or press CTRL+D.
The generated file will be in ANSI format, which includes the colors that were displayed on scree. In order to read them, you can use CLI tools like, ansi2txt or ansi2html to convert it to plain text or HTML respectively.
Start-Script
In the case of Start-Script, you can call it like this:
Start-Script -Path <drive>:\Transcript.txt # File name can be anything.
To stop recording, you need to call Stop-Transcript. The file created is a plain text file where the commands executed, and their outputs, are stored.
Rollback
Reverting to the previous state is called a rollback.
Never Test in Production
Before pushing any changes to Production, test them first on the Test environment to make sure, they are bug free.
If you’re in charge of an important service that you need to keep running during a configuration change, it’s recommended that you have a secondary or stand-by machine.
First apply the changes after testing them in the test environment, to the stand-by or secondary machine, then make that machine primary, and apply changes to the production machine.
For even bigger services, when you have lots of servers providing the service, you may want to have canaries. (canaries: small group of servers, if anything still doesn’t work, it shouldn’t take down the whole infrastructure.)
Production
The parts of the infrastructure where a certain service is executed and served to its users.
Test environment
A virtual machine running the same configuration as the production environment, but isn’t actually serving any users of the service.
Secondary or stand-by machine
This machine will be exactly the same as a production machine, but won’t receive any traffic from actual suers until you enable it to do so.
Assessing Risk
There is no point of having test/secondary servers, when nobody cares about the downtime.
So, it’s very important to assess the risk before going forward to invest in the backup plans.
In general, the more users your service reaches, the more you’ll want to ensure that changes aren’t disruptive.
The more important your service is to your company’s operations, the more you’ll work to keep the serve up
Fixing Things the Right Way
Reproduction case
Creating a roadmap to retrace the steps that led the user to an unexpected outcome.
When looking for a Reproduction case, there are three questions you need to look for:
What steps did you take to get to this point?
What is the unexpected or bad result?
What is the expected result?
After applying your fix, retrace the same steps that took you to the bad experience. If your fix worked, the expected experience should now take place.
Network and Infrastructure Services
Types of IT Infrastructure Services
You can use Cloud Infrastructure Services or IaaS, if you don’t want to use own hardware. Some common IaaS providers are:
Amazon EC2
Linode
Windows Azure
Google Compute Engine (GCP)
Networks can be integrated into an IaaS
But in recent years, Network as a Service or NaaS has emerged.
Every company needs, some email service, word processor, ppt makers, CMS, etc. Software as a Service or SaaS can handle it for you.
Some companies have a product built around a software application. In this case, there are some things that software developers need to be able to code, build and shape their software.
First, specific applications have to be installed for their programming development environment.
Then, depending on the product, they might need a database to store information.
Finally, if they’re serving web content like a website, they might need to publish their product on the Internet.
For all in one solution, Platform as a Service or PaaS, is used.
The last IT Infrastructure service we’ll discuss is the management of users, access, and authorization. A directory service, centralizes your organization’s users and computers in one location so that you can add, update, and remove users and computers. Some popular directory services are:
Windows Active Directory (AD)
OpenLDAP
The directory services can be directly deployed in the cloud via Directory as a Service or DaaS.
Physical Infrastructure Services
Server Operating Systems
Regular operating systems that are optimized for server functionality.
Windows Server
Linux Servers
macOS Servers
Virtualization
Advantages:
Resource Utilization
Maintenance
Point of Failure
Cost
Connectivity
Limitations:
Performance
Network Services
FTP, SFTP, and TFTP
Network service commonly used in an organization is File transfer service.
PXE Boot (Preboot Execution)
It allows you to boot into software available on the network.
NTP (Network Time Protocol)
One of the oldest network protocols
You can use Public NTP server, or deploy your own if you have a fleet of hundreds and thousands of computers.
Network Support Services Revisited
There are a few services that are used internally in an IT enterprise environment, to improve employee productivity, privacy, and security.
Intranet
Proxy servers
Intranet
An internal network inside a company; accessible if you’re on a company network.
Proxy server
Acts as an intermediary between a company’s network and the Internet.
DNS
Maps human-understandable names to IP addresses.
DNS for Web Servers
First, we need a domain name.
We can also have own server, pointed to the domain name.
DNS for Internal Networks
The other reason we might want our own DNS servers is, so we can map our internal computers to IP addresses. That way, we can reference a computer by name, instead of IP address.
You can do this through hosts files.
Hosts, files allow us to map IP addresses to host name manually.
AD/OpenLDAP can be used to handle user and machine information in its central location. Once local DNS servers is set, it will automatically populate with machine to IP address mappings.
When connecting to a network, you have two options for IP address assignment:
Static IP
DHCP assigned IP
Troubleshooting Network Services
Unable to Resolve a Hostname or Domain Name
To check if website accepts ping requests
ping google.com
To verify if your DNS is giving you correct address for <google.com>
nslookup google.com
Remember that when a DNS query is performed, your computer first checks the host file. To access a host file:
sudo vim /etc/hosts
Managing System Services
What do Services Look Like in Action
We have looked at many services so far:
DHCP
DNS
NTP etc.
It’s important to understand how the programs that provide these services operate. So, that you can manage them and fix any problems that pop-up.
These programs as background processes, also known as daemons, or just services.
This means that the program doesn’t need to interact with a user through the graphical interface or the CLI to provide the necessary service.
Each service has one or more configuration file, you as Sysadmin will determine how to operate.
Some services offer interactive interface for configuration and changes, others may rely on the system’s infrastructure.
It means you need to edit the configuration file yourself.
You should also know how to start or stop a service.
Services are usually configured to start when the machine boots, so that if there’s a power outage or a similar event that causes the machine to reboot, you won’t need a system administrator to manually start the service.
Managing Services on Linux
To check if NTP daemon running on a system
timedatectl
If there is a change of more than 120ms, the NTP daemon will not adjust for the change.
Stopping and starting the NTP service manually, will adjust the clock to correct settings.
Restart first stops and then start the service.
Managing Services on Windows
Here, for example, we will deal with Windows Update Service
To check the status of the service:
Get-Service wuauserv # Short hand for Windows Update Service
To get more information about the service:
Get-Service wuauserv | Format-List *
To stop service (Admin required):
Stop-Service wuauserv
To start a service (Admin required):
Start-Service wuauserv
To list all services running in the system:
Get-Service
**Same actions can be performed via Service Management Console in GUI.
Configuring Services on Linux
Most services are enabled as you install them, they are default services ship with the program itself.
The configuration files for the installed services are located in the /etc directory.
Here we will use the example of ftp client.
After installing ftp client vsftpd, it will start the service automatically.
We can start ftp client
lftp localhost
It requires username and password to view contents
To enable anonymous ftp logins, we can edit the configuration file in /etc/vsftpd.conf
Then reload the ftp client
sudo service vsftpd reload
lftp
A ftp client program that allows us to connect to a ftp server.
Reload
The service re-reads the configuration without having to stop and start.
Configuring Services on Windows
Here as an example we will use Internet Information Services, the feature offered by Windows to serve the web pages.
First, Turn the Feature ON and OFF in the settings to first enable it.
Then we can add and remove IIS in the server manager, where IIS tab is now available after applying the above changes.
Configuring DNS with Dnsmasq
dnsmasq
A program that provides DNS, DHCP, TFTP, and PXE services in a simple package.
To install it:
sudo apt install dnsmasq
It immediately gets enabled with basic functionality, provides cache for DNS queries. This means you can make DNS request to it, and it’ll remember answers, so your machine doesn’t need to ask an external DNS server each time.
To check this functionality, we’ll use dig command, which lets us query DNS servers and see their answers:
dig www.example.com @localhost
Part after @ sign specifies which DNS server to use for query.
To see what’s happening in the background, we can run dnsmasq in the debug mode.
First stop the service:
sudo service dnsmasq stop
Now, run it in debug mode:
sudo dnsmasq -d -q
Now open a second console, and run dig command again, dnsmasq console running with flags -d (debug), q (query logging)
Configuring DHCP with Dnsmasq
A DHCP server is usually set up on a machine or a device that has a static IP address configured to the network interface which is being used to serve the DHCP queries. That interface is then connected to the physical network that you want to configure through DHCP, which can have any number of machines on it. In real life, the DHCP server and the DHCP client typically run on two separate machines.
For this example, we’ll use a single machine
In this machine, we have an interface called eth_srv, that’s configured to be the DHCP server’s interface.
We also have an interface called eth_cli, which is the interface that we’ll use to simulate a client requesting an address using DHCP. This interface doesn’t have an IP configured yet.
So, I’m going to type in
ip address show eth_cli
We can see that this interface doesn’t have an IPV4 address configured. We will change this by using our DHCP server. To do this, we need to provide additional configuration to dnsmasq. There are lots of things we can configure. We’re going to use a very basic set of options. Let’s look at the configuration file.
cat DHCP config.
The interface option tells dnsmasq that it should listen for DHCP queries on the eth_srv interface. The bind interfaces option tells it not to listen on any other interfaces for any kind of queries. This allows us to have more than one dnsmasq server running at the same time, each on its own interface. The domain option tells the clients, the networks’ domain name and will be used for querying host names. Then, we have two different DHCP options, which are additional information that will be transmitted to DHCP clients when the IP is assigned. In this case, we’re telling clients what to configure as a default gateway and which DNS servers should be used. There are a lot more options that we can set, but these two are the most common ones.
Finally, we configure the DHCP range. This is the range of IP addresses that the DHCP server can hand out. Depending on your specific setup, you may want to reserve some addresses in your network for machines that need to have a static address. If you don’t plan to do that, you can make the range larger, but make sure you don’t include the address of the DHCP server itself. The last value in the DHCP range Line is the length of the lease time for the IP address. In this case, it’s 12 hours, which means that once an address is assigned to a machine, it will be reserved for that machine for those 12 hours. If the lease expires without the client renewing it, the address can be assigned to a different machine.
Let’s tell dnsmasq to start listening for queries using this config.
sudo dnsmasq -d -q -c dhcp.conf
We can see in the output that dnsmasq is listening for DHCP queries on the eth_srv interface with the options that we set in our configuration file. Now, let’s run a DHCP client on a second terminal.
sudo dhclient -i eth_cli -v
We’re using dhclient which is a very common DHCP client on Linux. We’re telling it to run on the eth_cli interface, and we’re using the -v flag to see the full output of what’s happening.
ip address show eth_cli
Our eth_cli interface has successfully acquired an IP address.
Provide a platform for developers to code, build, and manage software applications.
Software Services
Services that employees use that allow them to do their daily job functions.
Major software services are
Communication services
Security services
User productivity services
Communication services
Some instant chat communication services are:
Internet Chat relay (IRC)
Paid for options: HipChat and Slack
IM protocols: XMPP or Extensible Messaging and Presence Protocol
Configuring Email Services
Domain name for company
Google Suite
Some email protocols are:
POP3 or Post Office Protocol 3
It first downloads the email from the server and onto your local device. It then deletes the email from the email server. If you want to retrieve your email through POP3, you can view it from one device.
IMAP or Internet Message Protocol
Allows you to download emails from your email server onto multiple devices. It keeps your messages on the email server.
SMTP or Simple Mail Transfer Protocol
It is an only protocol for sending emails.
Configuring User Productivity Services
When considering software licenses, it’s important to review the terms and agreements.
Software used has consumer won’t be the same as the software used as business.
Configuring Security Services
Different protocols for managing the security of the online services
Hyper Text Transfer Protocol Secure (HTTPS)
The secure version of HTTP, which makes sure the communication your web browser has with the website is secured through encryption.
Transport layer security protocol or TLS
Secure Socket layer or SSL (deprecated)
To enable TLS, so a website can use HTTP over TLS, you need to get an SSL certificate for Trust authority.
File Services
What are File Services?
Network File Storage
Only few file systems are cross-compatible. Like FAT32.
Network File System (NFS), allows us to share files over a network, cross-compatible.
NFS is even through cross-compatible, but there are some compatibility issues on Windows.
Even your fleet is mostly Windows, you can use Samba, though Samba is also cross-platform.
SMB or Server Message Block is a protocol that Samba uses.
An affordable solution is to use Network Attached Storage or NAS. They are optimized for network storage and comes with the OS stripped down and optimized for file transfer and storage.
Print Services
Configuring Print Services
On Windows, print feature can be enabled
In Linux, CUPS, or Common Unix Printing Service.
Platform Services
Web Servers Revisited
Web server
Stores and serves content to clients through the Internet.
Some server software:
Apache2
Nginx
Microsoft IIS
What is a database server?
Databases
Allow us to store, query, filter, and manage large amounts of data.
Common databases:
MySQL
PostgreSQL
There is a specialized field within IT that handles databases:
Database Administration
Troubleshooting Platform Services
Is the Website down?
HTTP status codes are of great help for troubleshooting web servers errors.
Knowing common HTTP status codes comes handy for fixing website errors.
HTTP status Codes
HTTP status Codes are codes or numbers that indicate some sort of error or info messages that occurred when trying to access a web resource.
HTTP status codes that start with 4xx indicate an issue on the client-side.
The other common HTTP status codes you might see start with 5xx. These errors indicate an issue on the server-side.
They tell us more than just errors. They can also tell us when our request is successful, which is denoted by the codes that begin with 2xx.
404 Not Found
A 404 error indicates that the URL you entered doesn’t point to anything.
Managing Cloud Resources
Cloud Concepts
When setting up cloud server, region is important
SaaS
The software is already pre-configured and the user isn’t deeply involved in the cloud configuration.
IaaS
You’re hosting your own services in the cloud. You need to decide how you want the infrastructure to look, depending on what you want to run on it.
Regions
A geographical location containing a number of data centers.
Each of these data centers are called zones.
If one of them fails for some reason, the others are still available and services can be migrated without visibly affecting users.
Public cloud
Cloud services provided to you by a third party.
Private cloud
When your company owns the services and the rest of your infrastructure – whether on-site or in a remote data center.
Hybrid cloud
A mixture of both private and public clouds.
Typical Cloud Infrastructure Setups
Let’s say you have a web server providing a website to a client. In a typical setup for this kind of service running in a cloud, a number of virtual machines will be serving this same website using Load balancers.
To make sure servers running properly, you can set:
Monitoring
Alerting
Load Balancer
Ensures that each VM receives a balanced number of queries.
Auto-scaling
It allows the service to increase or reduce capacity as needed, while the service owner only pays for the cost of the machines that are in use at any given time.
Directory Services
Introduction to Directory Services
What is a directory server?
“Contains a lookup service that provides mapping between network resources and their network addresses.”
A sysadmin will be responsible for directory server:
Setup
Configuration
Maintenance
Replication
The stored directory data can be copied and distributed across a number of physically distributed servers, but still appear as one, unified data store for querying and administrating.
Directory services
Useful for organizing data and making it searchable for an organization.
Implementing Directory Services
Directory services became an open network standard for interoperability among different vendors.
Directory Access Protocol or DAP
Directory System Protocol or DSP
Directory Information Shadowing Protocol or DISP
Directory Operational Bindings Management Protocol or DOP
The most popular of these alternatives was:
Lightweight Directory Access Protocol or LDAP
The popular industry implementation of these protocols are:
Microsoft Active Directory or AD
OpenLDAP
Centralized Management
What is centralized management?
“A central service that provides instructions to all the different parts of the company’s IT infrastructure.”
Directory services provide centralized authentication, authorization, and accounting, also known as AAA.
Role base access control or RBAC is super important in centralized management to restrict access to authorized users only.
They’re super powerful configuration management, and automation software tools like:
Chef
Puppet
SCCM
LDAP
What is LDAP?
“Used to access information in directory services, like over a network.”
The most famous one which use LDAP:
AD
OpenLDAP
LDIF (LDAP data Interchange Format) has the following fields
dn (distinguished name)
This refers to the name that uniquely identifies an entry in the directory.
dc (domain component)
This refers to each component of the domain.
ou (organizational unit)
This refers to the organizational unit (or sometimes the user group) that the user is part of.
cn (common name)
This refers to the individual object (person’s name; meeting room; recipe name; job title; etc.) for whom/which you are querying.
What is LDAP Authentication
There are three ways of LDAP authentication:
Anonymous
Simple
SASL - Simple Authentication & Security Layer
The common SASL authentication technique is Kerberos.
Kerberos
A network authentication protocol that’s used to authenticate user identity, secure the transfer of user credentials, and more.
Active Directory
What is Active Directory?
The native directory service for Microsoft Windows.
Central point for managing Group Policy Objects or GPOs.
Managing Active Directory Users and Groups
Local user accounts and security groups are managed by the **Security Accounts Manager (SAM) on a local computer.
There are three group scopes:
Universal
global
domain local
Managing Active Directory User Passwords
Passwords are stored as cryptographic hash.
If there’s more than one person who can authenticate using the same username and passwords, then auditing become difficult or even impossible.
If a user forgets his/her password, you as a sysadmin can reset their password for them.
Password reset will wipe out any encrypted files on the user’s computer.
Designated user accounts, called recovery agents > accounts, are issued recovery agent certificates with public keys and private keys that are used for EFS data recovery operations.
Joining an Active Directory Domain
A computer not part of the AD is called a WorkGroup computer.
Settings > System and Security > System > Computer name, domain, and workgroup settings
Functional levels determine the available AD Domain Service (AD DS) domain or forest capabilities. They also determine which Windows Server OS you can run on domain controllers in the domain or forest.
What is Group Policy?
Group Policy Object (GPO)
A set of policies and preferences that can be applied to a group of objects in the directory.
When you link a GPO, all the computers or users under that domain, site, or OU will have that policy applied.
A GPO can contain computer configuration, user configuration, or both.
Group Policy Management tool, or gpms.msc, to change GPOs.
Policies
Settings that are reapplied every few minutes, and aren’t meant to be changed even by the local administrators.
By default, a GPO, will be applied every 90 mins, so OUs don’t drift away from policies.
Group policy preferences
Settings that, in many cases, are meant to be a template for settings.
Windows Registry
A hierarchical database of settings that Windows, and many Windows applications, use for storing configuration data.
GPOs are applied by changing Windows Registry settings.
Group Policy Creation and Editing
Always make backup before creating new policies or editing existing ones.
Group Policy Inheritance and Precedence
When a computer is processing GPO that apply to it, all of these policies will be applied in Precedence rules.
The Resultant Set of Policy or RSOP report is used to review applied policies and preferences.
When GPOs collide, they’re applied:
Site → Domain → OU (Applied from least specific to the most specific)
Group Policy Troubleshooting
One of the most common issues you might encounter is when a user isn’t able to log in to their computer, or isn’t able to authenticate to the Active Directory domain.
Maybe user locked out due to multiple failed log-in attempts.
Sometimes they just forget their password.
Start with the simplest problem statement, like perhaps there is a network connectivity issue, not directly from AD troubleshooting.
Possibly there is a problem with DNS record and computer cannot find src-record.
The SRV records that we’re interested in are _ldap._tcp.dc_msdcs.Domain.Name, where DOMAIN.NAME is the DNS name of our domain.
OpenLDAP is an open source implementation of Lightweight Directory Access Protocol (LDAP)
Using LDAP Data Interchange Format (LDIF), you can authenticate, add, remove users, groups and so on in the active directory service.
Works on Linux, Windows, and macOS.
To install it on Debian and Debian-based distros:
sudo apt install slapd ldap-utils
Then we’ll reconfigure the slapd package:
sudo dpkg-recofigure slapd
Now you have a running ldap server.
To get Web Interface:
sudo apt install phpldapadmin
The web server is now configured to serve the application, but we need to make additional changes. We need to configure phpldapadmin to use our domain, and not to autofill the LDAP login information.
sudo vim /etc/phpldapadmin/config.php
Look for the line that start with $ servers->setValue('server','name
$server->setValue('server','name','Example LDAP')
Next, move down to the $servers->setValue('server','base' line.
The last thing that we need to adjust is a setting that controls the visibility of some phpLDAPadmin warning messages. By default, the application will show quite a few warning messages about template files. These have no impact on our current use of the software. We can hide them by searching for the hide_template_warning parameter, uncommenting the line that contains it, and setting it to true:
“The process of trying to restore data after an unexpected even that results in data loss or corruption.”
How you go for data recovery depends on few factors:
Nature of Data Loss
Backups already in place
When an unexpected even occurs, your main objective is to resume normal operations asap, while minimizing the disruption to business functions.
The best way to be prepared for a data-loss event is to have a well-thought-out disaster plan and procedure in place.
Disaster plans should involve making regular backups of any and all critical data that’s necessary for your ongoing business processes.
Postmortem
A Postmortem is a way for you to document any problems you discovered along the way, and most importantly, the ways you fixed them so, you can make sure they don’t happen again.
Backing Up Your Data
Absolutely necessary data should be backed up.
Backed up data as well as, data in transit for backup, both should be encrypted.
Backup Solutions
Too many backup solutions are there, some of them are:
rsync
A file transfer utility that’s designed to efficiently transfer and synchronize files between locations or computers.
Time Machine
Apple’s backup solution, that can restore entire snapshot or individual files.
Microsoft Backup and Restore
Backup and restore is used to back up files as well as, system snapshots in the disk.
This tool can do following tasks:
Back up
Create a system image
Create a restore point
Testing Backups
Disaster recovery testing should be done every year or so.
Restoration procedure
Should be documented and accessible so that anyone with the right access can restore operations when needed.
Types of Backup
Ways to Perform Regular Backups:
Full backup
Differential backup
Regular incremental backups
It’s a good practice to perform infrequent full backups, while also doing more frequent differential backups.
While a differential backup backs up files that have been change or created since the last full backup, an incremental backup is when only the data that’s changed in files since the last incremental backup is backed up**.
RAID array can solve the problem of failing disks on on-site backups.
Redundant Array of Independent Disks (RAID)
A method of taking multiple physical disks and combining them into one large virtual disk.
RAID isn’t a replacement for backups
It’s data storage solution which can save you from accidental deletion, or malware.
User Backups
For user backups:
Dropbox
Apple iCloud
Google Drive
Disaster Recovery Plans
What’s Disaster Recovery Plan?
“A collection of documented procedures and plans on how to react and handle an emergency or disaster scenario, from the operational perspective.”
Preventive measures
Any procedures or systems in place that will proactively minimize the impact of a disaster.
Detection measures
Meant to alert you and your team that a disaster has occurred that can impact operations.
Environmental Sensors
Flood sensors
Temp and Humidity Sensors
Evacuation procedures
Corrective or recovery measures
Those enacted after a disaster has occurred.
Designing Disaster Recovery Plan
No fit for all plan, there is a lot to go into a disaster recovery plan.
Designing a Disaster Recovery Plan:
Perform Risk Assessment
Determine Backup and Recovery Systems
Determine Detection & Alert Measures & Test Systems
Determine recovery measures
Risk assessment
Allows you to prioritize certain aspects of the organizations that are more at risk if there’s an unforeseen event.
Postmortems
What’s a Postmortem?
“A Postmortem is a way for you to document any problems you discovered along the way, and most importantly, the ways you fixed them so, you can make sure they don’t happen again.”
We create a Postmortem after an incident, an outage, or some event when something goes wrong, or at the end of a project to analyze how it went.
Writing a Postmortem
Typical postmortem report consists of:
Brief Summary of the incident happened
Detailed Timeline of Key events
Root Cause
Resolution and Recovery Efforts
Actions to Avoid Same Scenario
What went well?
Final Project: SysAdmin and IT Infrastructure Services
System Administration for Network Funtime Company
Scenario 1
You’re doing systems administration work for Network Funtime Company. Evaluate their current IT infrastructure needs and limitations, then provide at least five process improvements and rationale behind those improvements. Write a 200-400 word process review for this consultation. Remember, there’s no right or wrong answer, but make sure to provide your reasoning.
The company overview:
Network Funtime Company is a small company, that builds open-source software.
The Company is made up of 100 employees:
Software engineers
Designers
A Single HR Department
A Small Sales Team
Problem Statement
There is no technical support personnel.
The HR, is responsible for buying hardware for new resources.
Due to lack of funds, company go for the cheapest hardware possible.
Due to lack of funds, everyone in the company has different laptops models.
There are no backups for hardware, which creates additional wait time for new employees to start working.
Due to missing standardized labeling convention, when a laptop or computer goes missing/stolen, there is no way to audit it.
No Inventory system.
HR manages System setups for engineers as well as answer their support queries through email.
No standard way for login management, password management and recovery.
The company use cloud applications like:
Email
Word Processor
Spreadsheets
Slack – Instant Communication
The Improvements
The company should hire an IT Support specialist, who will take care of:
Buying new hardware, and disposing off the retired machines
According to company budget, selecting a hardware with similar specs.
Keep the inventory record, and labeling each and every machine before handing over to new employees.
Keeping a few machines as a backup in the inventory.
Managing a ticking system for employees’ support question.
Keeping the documentation of the fixes and issues.
Keeping a bootable USB of the OSs used in the company.
When the company hires a new resource, he/she sets up their machine for them.
The company should move to OpenLDAP or Active Directory for centralized passwords and permissions management and recovery.
The HR should be responsible for his/her tasks instead of providing IT Support, Hardware management, and Employees’ software installation and setup.
The Rationale Behind Improvements
Hiring an IT support specialist:
Will reduce the work of an HR
Keep the inventory record, which will make auditing very easy.
Selecting a standardized hardware, will make troubleshooting and tracking issues and fixes much easier, which in turn lessen the time spent in fixing and more in doing the work.
Keeping backups in the inventory, reduce time wastage for the new employees, they can start working asap.
Having a ticketing system or some centralized way of tracking issues and fixes, will create a documentation for future reference, and if the same issue arises again, it will be solved in no time.
Keeping bootable USB, saves in hunting down the software and makes the setup process easy, so reduces the overhead for new employees. And They can start working immediately.
Centralized management:
OpenLDAP/Active Directory, will make sure to centrally manage users and permissions, so everyone has only required access to the company’s sensitive documents.
Password resets will become more easy, there be less time wastage.
Scenario 2
You’re doing systems administration work for W.D. Widgets. Evaluate their current IT infrastructure needs and limitations, then provide at least five process improvements and rationale behind those improvements. Please write a 200-400 word process review for this consultation. Remember, there’s no right or wrong answer, but make sure to provide your reasoning.
The Company Overview
The company is in the business of selling widgets. There are mostly sales persons in the company.
The company size is 80–100 people.
Problem Statement
Sole IT person
Manual installation of the software on new machines.
Direct emails for IT support related issues.
Almost every software is kept in house:
Email server
Local Machine Software
Instant messenger
The Single file server for customers data.
No centralized management of the data.
No backups
Everyone has their copy with their unique data.
The company growth is exponential. They expect to hire hundreds of new employees.
The Improvements
The company should hire new talent for IT Support related stuff.
The automation for the following should be done:
Installation of software on the new machines.
Automated backups should be in place for critical data.
Storage server should be redundant.
A centralized management of the data is required:
To manage customers information in a single place
The company should move from one server to many redundant storage solutions.
Permissions, and access to the data, should be limited to the role of the person.
To answer IT Support questions:
There should be a ticketing system in place.
There should be documentation of the common issues.
The company should move some of their services to the cloud, like:
Email
Instant Chats
The Rationale
Hiring new tech talent:
Will make sure you’re ready for next big step of your expansion
Will distribute the work load, so fewer burnouts.
The automation will make sure:
There is no manual input, so fewer chances of errors.
No hours wasted on installing software, and configuring the new machines.
The cloud will make the company:
Less reliant on local servers, which require more maintenance, and security related complex configuration.
It will reduce the number of the people required for managing those servers.
There will be almost zero maintenance overhead for the cloud.
The data will be centrally available and backed up.
Email and chat servers are pretty complex to manage, and require a lot of security knowledge.
The centralized management:
Will make sure the right person has access to the right information
Removing the access of Ex-employees will become easy.
Role based access control, will make sure sensitive internal documents are exposed to wrong persons.
Scenario 3
You’re doing systems administration work for Dewgood. Evaluate their current IT infrastructure needs and limitations, then provide at least five process improvements and rationale behind those improvements. Please write a 200-400 word process review for this consultation. Remember, there’s no right or wrong answer, but make sure to provide your reasoning.
The Company Overview
A small local non-profit of 50 employees.
Sole IT person
Problem Statement
Computers are bought directly in a physical store on the day new talent is hired.
Due to budget issue, they can’t keep extra stock.
The company has a single server with multiple services:
Email
File server
Don’t have an internal chat system.
AD is used, but Ex-employees are not disabled.
Ticketing system is confusing and difficult to use, so:
Many employees reach out to IT person, to know how to use it.
Employees are always asking around the questions of how to use it.
IT person, takes backups on a personal Drive and takes it home.
A website with single HTML page is hosted on internal server, and remain down many times, no one know why.
The Improvements and Rationale
The computer should be purchased directly from vendors:
Vendors offer special discounts to businesses and non-profits, so it will save cost.
There should some standardization to which hardware to buy to avoid fix issues every time for new hardware type.
The company should move their email sever to the cloud:
The cloud solutions are cheap.
There’s virtually no maintenance is involved.
Maintaining own email servers, requires a lot of complex configuration to make sure the security and redundancy, which isn’t possible with Single IT Person.
Should use some cloud-based solution for internal instant chats:
The teams can keep track of each other progress.
The teams can discuss issues, plans, and procedure without any hiccups.
To improve the customer ticketing system:
There should be proper documentation of to use it, so every time an employee doesn’t have to go to the IT person for help.
The common issues and fixes should properly document and stored on the server, so employees can access them, and fix the common issues themselves to reduce time wastage.
For the backups:
There should be on-site and off-site backups for sensitive data for redundancy purposes.
The cloud backup solutions can also be used for a small company.
Self-hosted backups should be automatic, and redundant.
Backups tests and recovery should be done once every year or so, to make sure in the case of an emergency, your backups will prove reliable.
IT Security: Defense against the Digital Dark Arts
It has 6 sub-modules about different security related topics and a 7th project module.
The Information we have is readily accessible to those people that should have it.
Essential Security Terms
Risk
The possibility of suffering a loss in the event of an attack on the system.
Vulnerability
A flaw in a system that could be exploited to compromise the system.
0-day vulnerability (zero day)
A vulnerability that is not known to the software developer or vendor, but is known to an attacker.
Exploit
Software that is used to take advantage of a security bug or vulnerability.
Threat
The possibility of danger that could exploit a vulnerability.
Hacker
Someone who attempts to break into or exploit a system.
White-hat hackers
Black-hat hackers
Attack
An actual attempt at causing harm to a system.
Malicious Software
Malware
A type of malicious software that can be used to obtain your sensitive information, or delete or modify files.
Adware
Software that displays advertisements and collects data.
Trojan
Malware that disguises itself as one thing but does something else.
Spyware
A type of malware that’s meant to spy on you.
Keylogger
A common type of spyware that’s used to record every keystroke you make.
Ransomeware
“A type of attack that holds your data or system hostage until you pay some sort of ransom.”
If the computer has one or more of the following symptoms, it may be infected with malware:
Running slower than normal
Restarts on its own multiple times
Uses all or a higher than normal amount of memory
After you’ve gathered information, verify that the issues are still occurring by monitoring the computer for a period of time. One way to monitor and verify is to review the activity on the computer’s resource manager, where you can see open processes running on a system.
When looking at the resource manager, you might see a program with a name you do not recognize, a program that is using a lot of memory, or both. If you see a suspicious program, you should investigate this application by asking the user if it is familiar to them.
Quarantine malware
Some malware communicates with bad actors or sends out sensitive information. Other malware is designed to take part in a distributed botnet. A botnet is a number of Internet-connected devices, each of which runs one or more bots. Because of malware’s potential ability to communicate with other bad actors, you should quarantine the infected device.
To quarantine, or separate, the infected device from the rest of the network, you should disconnect from the internet by turning off Wi-Fi and unplugging the Ethernet cable. Once the computer is disconnected, the malware can no longer spread to other computers on the network.
You should also disable any automatic system backup. Some malware can reinfect a computer by using automatic backup, because you can restore the system with files infected by the malware.
Remove malware
Once you have confirmed and isolated the malware on a device, you should attempt to remove the malware from the device. First, run an offline malware scan. This scan helps find and remove the malware while the computer is still disconnected from the local network and internet.
All antivirus/anti-malware programs rely on threat definition files to identify a virus or malware. These files are often updated automatically, but in the case of an infected computer they may be incomplete or unable to update. In this case, you may need to briefly connect to the internet to confirm that your malware program is fully updated.
The scan should successfully identify, quarantine, and remove the malware on the computer. Once the process is complete, monitor the computer again to confirm that there are no further issues.
To help ensure that a malware infection doesn’t happen again, threat definitions should be set to update automatically, and to automatically scan for and quarantine suspected malware.
After the malware has been removed from the computer, you should turn back on the automatic backup tool and manually create a safe restore point. If the computer needs attention in the future, this new restore point is confirmed safe and clean.
Malware education
One of the most important things an IT professional can do to protect a company and its employees is to educate users about malware. The goal of education is to stop malware from ever gaining access to company systems. Here are a few ways users and IT professionals can protect their computer and the company from malware:
Keep the computer and software updated
Use a non-administrator account whenever possible
Think twice before clicking links or downloading anything
Be careful about opening email attachments or images
Don’t trust pop-up windows that ask to download software
Limit your file-sharing
Use antivirus software
When all employees are on the lookout for suspicious files, it’s much easier to prevent malware and viruses from taking hold.
Botnets
Designed to utilize the power of the internet-connected machines to perform some distributed function.
Backdoor
A way to get into a system if the other methods to get in the system aren’t allowed.
Rootkit
A collection of software or tools that an Admin would use.
Man-in-the-middle attack is an attack that places the attacker in the middle of two hosts that think they’re communicating directly with each other.
The methods of Man-in-the-middle attack are:
Session or Cookie hijacking
Rogue AP
Evil twin
Rogue AP
An access point that is installed on the network without the network administrator’s knowledge.
Evil Twin
The premise of an evil twin attack is for you to connect to a network that is identical to yours. This identical network is our network’s evil twin and is controlled by our attacker.
Denial-of-service (DoS) attack
An attack that tries to prevent access to a service for legitimate users by overwhelming the network or server.
The ping of death or POD is an example of DoS attack, where the attacker sends the large number of pings to take down the server.
Another example is a ping flood, sends tons of ping packets to a system. More specifically, it sends ICMP echo requests.
Similar is a SYN flood, to make a TCP connection a client needs to send a SYN packet to a server it wants to connect to. Next, the server sends back a SYN-ACK message, then the client sends in ACK message.
In a SYN flood, the server is being bombarded with SYN packets.
During SYN flood, the TCP connection remains open, so it is also called a Half-open attack.
A type of injection attack where the attacker can insert malicious code and target the user of the service.
SQL injection attack
Password Attacks
Utilize software like password-crackers that try and guess your password.
Brute Force Attack
A Catchpa, can save your website from brute force attack.
Dictionary Attack
Deceptive Attacks
Social Engineering
An attack method that relies heavily on interactions with humans instead of computers.
The popular types of social engineering attacks:
Phishing attack – Use of email or text messaging
Spear phishing — Attack individuals
Email Spoofing
Baiting – Entice a victim to do something
Tailgating
Whaling – Spear phishing a high value target
Vishing - Use of Voice over IP (VoIP)
Spoofing
A source masquerading around as something else.
Tailgating
Gaining access into a restricted area or building by following a real employee in.
Pelcgbybtl (Cryptology)
Symmetric Encryption
Cryptography
The cryptography has two main fields:
Cryptology: The study of cryptographic methods.
Cryptanalysis: The study of breaking the cryptography.
Encryption
The act of taking a message, called plaintext, and applying an operation to it, called a cipher, so that you receive a garbled, unreadable message as the output, called ciphertext.
The reverse is Decryption.
The Cipher is made up of two components:
Encryption algorithm
Key
Encryption algorithm
The underlying logic of the process that’s used to convert the plaintext into ciphertext.
These algorithms are usually very complex. But there are also simple algorithms as well.
Security through obscurity is a principle where underlying encryption algorithm is also kept hidden for security purposes. But you shouldn’t rely on it, as once the underlying mechanism is discovered, your whole security will wash away.
The underlying principle of cryptography is called Kirchhoff’s principle.
Cryptosystem
A collection of algorithms for key generation and encryption and decryption operations that comprise a cryptographic service should remain secure – even if everything about the system is known, except the key.
The system should remain secure even if your adversary knows exactly what kind of encryption systems you’re employing, as long as your keys remain secure.
Frequency analysis
The practice of studying the frequency with which letters appear in a ciphertext.
An Arab mathematician of 9th century, used this first cryptographic method
Steganography
The practice of hiding the information from observers, but not encoding it.
The writing of messages with invisible ink.
The modern steganographic techniques involves, hiding the code/scripts in the PDF or image files etc.
Types of cryptanalysis attack
Known-Plaintext Analysis (KPA)
Requires access to some or all the of the plaintext of the encrypted information. The plaintext is not computationally tagged, specially formatted, or written in code. The analyst’s goal is to examine the known plaintext to determine the key used to encrypt the message. Then they use the key to decrypt the encoded information.
Chose-Plaintext Analysis (CPA)
Requires that the attacker knows the encryption algorithm or has access to the device used to do the encryption. The analyst can encrypt one block of chosen plaintext with the targeted algorithm to get information about the key. Once the analyst obtains the key, they can decrypt and use sensitive information.
Ciphertext-Only Analysis (COA)
Requires access to one or more encrypted messages. No information is needed about the plaintext data, the algorithm, or data about the cryptographic key. Intelligence agencies face this challenge when intercepting encrypted communications with no key.
Adaptive Chosen-Plaintext attack (ACPA)
ACPA is similar to a chosen-plaintext attack. Unlike a CPA, it can use smaller lines of plaintext to receive its encrypted ciphertext and then crack the encryption code using the ciphertext.
Meddler-in-the-Middle (MITM)
MITM uses cryptanalysts to insert a meddler between two communication devices or applications to exchange their keys for secure communication. The meddler replies as the user, and then performs a key exchange with each party. The users or systems think they communicate with each other, not the meddler. These attacks allow the meddler to obtain login credentials and other sensitive information.
These types of algorithms use the same key for encryption and decryption.
Substitution cipher
An encryption mechanism that replaces parts of your plaintext with ciphertext.
E.g., Caesar cipher, ROT13 etc.
Stream cipher
Takes a stream of input and encrypts the stream one character or one digit at a time, outputting one encrypted character or digit at a time.
Initialization vector (IV) is used, to add a random string of characters to the key.
Block ciphers
The cipher takes data in, places it into a bucket or block of data that’s a fixed size, then encodes that entire block as one unit.
Symmetric Encryption Algorithms
Data Encryption Standard (DES)
One of the earliest standard is Data Encryption Standard (DES).
With input from NSA, IBM developed it in the 1970s.
It was used as a FIPS.
Used 64-bits key sizes.
FIPS
Federal Information Processing Standard.
Standard Encryption Standard (AES)
NIST (National Institute of Standards and Technology), adopted Advanced Encryption Standard (AES) in 2001.
128-blocks, twice the size of DES blocks, and supports key length of 128-bits, 192-bits, or 256-bits.
Because of the large key size, brute-force attacks on AES are only theoretical right now, because the computing power required (or time required using modern technology) exceeds anything feasible today.
An important thing to keep in mind when considering various encryption algorithms is speed, and ease of implementation.
RC4 (Rivest Cipher 4)
A symmetric stream cipher that gained widespread adoption because of its simplicity and speed.
The first practical asymmetric cryptography systems to be developed is RSA.
Pretty complex math is involved in generating key pair for RSAs.
This crypto system was patented in 1983 and was released to the public domain by RSA Security in the year 2000.
Digital Signature Algorithm or DSA
It was patented in 1991, and is part of the US government’s Federal Information Processing Standard.
Similar to RSA, the specification covers the key generation process along with the signing and verifying data using the key pairs. It’s important to call out that the security of this system is dependent on choosing a random seed value that’s incorporated into the signing process. If this value was leaked or if it can be inferred if the prime number isn’t truly random, then it’s possible for an attacker to recover the private key.
Diffie-Hellman
Named after coworkers, invented it. It is solely used for key exchange.
Let’s assume we have two people who would like to communicate over an unsecured channel, and let’s call them Suzanne and Daryll. First, Suzanne and Daryl agree on the starting number that would be random and will be a very large integer. This number should be different for every session and doesn’t need to be secret. Next, each person decides another randomized large number, but this one is kept secret. Then, they combine their shared number with their respective secret number and send the resulting mix to each other. Next, each person combines their secret number with the combined value they received from the previous step. The result is a new value that’s the same on both sides, without disclosing enough information to any potential eavesdroppers to figure out the shared secret. This algorithm was designed solely for key exchange, though there have been efforts to adapt it for encryption purposes.
Elliptic curve cryptography (ECC)
A public-key encryption system that uses the algebraic structure of elliptic curves over finite fields to generate secure keys.
The benefit of elliptic curve based encryption systems is that they are able to achieve security similar to traditional public key systems with smaller key sizes. So, for example, a 256 bit elliptic curve key, would be comparable to a 3,072 bit RSA key. This is really beneficial since it reduces the amount of data needed to be stored and transmitted when dealing with keys.
Both Diffie-Hellman and DSA have elliptic curve variants, referred to as ECDH and ECDSA, respectively.
The US NEST recommends the use of EC encryption, and the NSA allows its use to protect up to top secret data with 384 bit EC keys
But, the NSA has expressed concern about EC encryption being potentially vulnerable to quantum computing attacks, as quantum computing technology continues to evolve and mature.
A type of function or operation that takes in an arbitrary data input and maps it to an output of fixed size, called a hash or digest.
You feed in any amount of data into a hash function, and the resulting output will always be the same size. But the output should be unique to the input, such that two different inputs should never yield the same output.
Hashing can also be used to identify duplicate data sets in databases or archives to speed up searching tables, or to remove duplicate data to save space.
Cryptographic hashing is distinctly different from encryption because cryptographic hash functions should be one directional.
The ideal cryptographic has function should be deterministic, meaning that the same input value should always return the same hash value.
The function should not allow Hash collisions.
Hash collisions
Two different inputs mapping to the same output.
Hashing Algorithms
MD5
Designed in early 1990s. Operates on 512-bits block and generates 128-bits hash digest.
While MD5 was designed in 1992, a design flaw was discovered in 1996, and cryptographers recommended using the SHA-1 hash.
In 2004, it was discovered that is MD5 is susceptible to hash collisions.
In 2008, security researchers create a fake SSL certificate that was validated due to MD5 hash collision.
Due to these very serious vulnerabilities in the hash function, it was recommended to stop using MD5 by 2010.
In 2012, this hash collision was used for nefarious purposes in the flame malware, which used to forge a Microsoft digital certificate to sign their malware, which resulted in the malware appearing to be from legitimate software that came from Microsoft.
Create a text file
echo 'This is some text in a file' > file.txt
To create an MD5 hash:
md5sum file.txt > file.txt.md5
To verify the hash
md5sum -c file.txt.md5
SHA-1
SHA-1 is part of the Secure Hash Algorithm suite of functions, designed by the NSA, published in 1995.
Operated at 512-bits blocks and use 160-bits hash digest.
It is used in popular protocols like:
TLS/SSL
PGP SSH
IPsec
VCS like git
NIST recommended stopping the use of SHA-1, and relying on SHA-2 in 2010.
Major browsers vendor dropped support for SSL certificates that use SHA-1 in 2017.
In early 2017, full collision of SHA-1 was published. Two PDFs were created with same SHA-1 hashes.
MIC or Message Integrity Check to make sure there is no data corruption in transit to the hash digest.
To create a hash
shasum file.txt > file.txt.sha1
To verify sha1
shasum -c file.txt.sha1
To create SHA256 hash
shasum -a 256 file.txt > file.txt.sha256
For verification, use the same command as above.
Defense against hash attacks
The passwords should not be stored in plaintext, instead they should be hashed and, store a hash.
Brute-force attack against a password hash can be pretty computationally expensive, depending upon the hash system used.
A successful brute force attack, against even the most secure system imaginable, is a function of attacker time and resources.
Another common methods to help raise the computational bar and protect against brute force attacks is to run the password through the hashing function multiple times, sometimes through thousands of iterations.
A rainbow table is ta table of precalculated hashes.
To protect against these precalculated rainbow tables, password salt come into play.
Password salt
Additional randomized data that’s added into the hashing function to generate a hash that’s unique to the password and salt combination.
Modern systems use 128-bits salt.
It means there are 2^128 possible salt combination.
Cryptographic Applications
Public Key Infrastructure (PKI)
PKI is a system that defines the creation, storage, and distribution of digital certificates. A digital certificate is a file that proves that an entity owns a certain public key.
The entity responsible for storing, issuing, and signing digital certificates is call Certificate authority or CA.
There’s also a Registration authority, or RA, that’s responsible for verifying the identities of any entities requesting certificates to be signed and stored with the CA.
A central repository is needed to securely store and index keys, and a certificate management system of some sort makes managing access to stored certificates and issuance of certificates easier.
PKI signing process
Start from the Root Certificate authority, which signs the certificate itself, as no one above it.
This Root certificate authority can now use the self-signed certificate and the associated private key to begin signing other public keys and issuing certificates.
A certificate that has no authority as a CA is referred to as an end-entity or leaf certificate.
The X.509 standard is what defines the format of digital certificates.
The fields defined in X.509 are:
Version
What version of the X.509 standard the certificate adheres to.
Serial number
A unique identifier for the certificate assigned by the CA, which allows the CA to manage and identify individual certificates.
Certificate Signature Algorithm
This field indicates what public key algorithm is used for the public key and what hashing algorithm is used to sign the certificate.
Issuer Name
This field contains information about the authority that signed the certificate.
Validity
This contains two subfields – “Not Before” and “Not After” – which define the dates when the certificate is valid for.
Subject
This field contains identifying information about the entity the certificate was issued to.
Subject Public Key Info
These two subfields define the algorithm of the public key, along with the public key itself.
Certificate Signature Algorithm
Same as the Subject Public Key Info field; These two fields must match.
Certificate Signature Value
The digital signature data itself.
SSL/TLS server certificate
This is a certificate that a web server presents to a client as part of the initial secure setup of an SSL, TLS connection.
Self-signed certificate
Signed by the same entity that issued the certificate. Signing your own public key using your own with private key.
SSL/TLS client certificate
As the names implies, these are certificates that are bound to clients and are used to authenticate the client to the server, allowing access control to an SSL/TLS service.
Code Signing Certificates
This allows users of these signed applications to verify the signatures and ensure that the application was not tampered with.
Webs of Trust
Individuals are signing each other certificates, after verifying the identity of the persons with agreed upon methods.
Cryptography in Action
HTTPS
The secure version of HTTP, the Hyper Text Transport Protocol.
It can also be called HTTP over the TLS.
Even though, TLS is a completely independent protocol from HTTPS.
TLS
It grants us three things
A secure communication line, which means data being transmitted, is protected from potential eavesdroppers.
The ability to authenticate both parties communicating, though typically only the server is authenticated by the client.
The integrity of communications, meaning there are checks to ensure that messages aren’t lost or altered in transit.
To establish a TLS channel, there is a TLS handshake in place.
The session key is the shared symmetric encryption key used in TLS sessions to encrypt data being sent back and forth.
Secure Shell (SSH)
A secure network protocol that uses encryption to allow access to a network service over unsecured networks.
SSH uses public key cryptography.
Pretty Good Privacy (PGP)
An encryption application that allows authentication of data, along with privacy from third parties, relying upon asymmetric encryption to achieve this.
Securing Network Traffic
Virtual Private Network (VPN)
A mechanism that allows you to remotely connect a host or network to an internal, private network, passing the data over a public channel, like the internet.
There are different VPN protocols:
IPsec
IPsec support two modes:
When transport mode is used, only the payload of the IP packet is encrypted, leaving the IP headers untouched.
In tunnel mode, the entire IP packet, header payload and all, is encrypted and encapsulated inside a new IP packet with new headers.
Layer 2 tunneling protocol or L2TP
It is not an all alone protocol, it is used in conjunction with IPsec protocol.
The tunnel is provided by L2TP, which permits the passing of unmodified packets from one network to another. The secure channel, on the other hand, is provided by IPsec, which provides confidentiality, integrity, and authentication of data being passed.
The combination of L2TP and IPsec is referred to as L2TP/IPsec and was officially standardized in IETF RFC 3193
OpenVPN
OpenVPN is an example of LT2p/IPsec.
It uses OpenSSL library to handle key exchange and encryption of data, along with control channels.
OpenVPN can operate over either TCP or UDP, typically over port 1194.
It can either rely on a Layer 3 IP tunnel or a Layer 2 Ethernet tap. The Ethernet tap is more flexible, allowing it to carry a wider range of traffic.
OpenVPN supports up to 256-bits encryption through OpenSSL library. It runs in user space, so avoid the underlying vulnerabilities of the system.
Cryptographic Hardware
TPM or Trusted Platform Module
Another interesting application of cryptography concepts, is the Trusted Platform Module or TPM. This is a hardware device that’s typically integrated into the hardware of a computer, that’s a dedicated crypto processor.
TPM offers:
Secure generation of keys
Random number generation
Remote attestation
Data binding and sealing
There’s been a report of a physical attack on a TPM which allowed a security researcher to view and access the entire contents of a TPM.
For Full disk encryption or FDE, we have the number of options:
PGP
BitLocker
Filevault 2
dm-crypt
Generating OpenSSL Public-Private Key pairs
To generate a 2048-bits RSA private key
openssl genrsa -out private_key.pem 2048
To generate a public key from the private_key.pem file
In order to issue client certificates, an organization must set up and maintain CA infrastructure to issue and sign certificates.
The certificates are checked against CRL.
Certificate revocation list (CRL)
A signed list published by the CA which defines certificates that have been explicitly revoked.
LDAP
Lightweight Directory Access Protocol (LDAP) is an open, industry-standard protocol for accessing and maintaining directory services.
Bind: How clients authenticate to the server.
StartTLS: It permits a client to communicate using LDAP v3 over TLS
Search: For performing look-ups and retrieval of records.
Unbind: It closes the connection to the LDAP server.
RADIUS
Remote Authentication Dial-In User Service (RADIUS) is a protocol that provides AAA services for users on a network.
Kerberos
A network authentication protocol that uses “tickets” to allow entities to prove their identity over potentially insecure channels to provide mutual authentication.
TACACS+
Terminal Access Controller Access-Control System Plus
TACACS+ is primarily used for device administration, authentication, authorization, and accounting.
Single Sign-On
An authentication concept that allows users to authenticate once to be granted access to a lot of different services and applications.
OpenID
Authorization
Pertains to describing what the user account has access to, or doesn’t have access to.
Authorization and Access Control Methods
One popular and open standard for authorization is:
OAuth
Access Control
OAuth
An open standard that allows users to grant third-party websites and applications access to their information without sharing account credentials.
OAuth’s permissions can be used in phishing-style attacks to again access to accounts, without requiring credentials to be compromised.
This was used in an OAuth-based worm-like attack in early 2017, with a rash of phishing emails that appeared to be from a friend or colleague who wants to share a Google Document.
Access Control List (ACL)
A way of defining permissions or authorization for objects.
Accounting
Keeping records of what resources and services your users accessed, or what they did when they were using your systems.
Auditing
Tracking Usage and Access
What exactly accounting tracks, depends on the purpose and intent of the system.
A TACACS+ server would be more concerned with keeping track of user authentication, what systems they authenticated to, and what commands they ran during their session.
TACACS+ is a devices access AAA system that manages who has access to your network devices and what they do on them.
CISCO’s AAA system supports accounting of individual commands executed, connection to and from network devices, commands executed in privileged mode, and network services and system details like configuration reloads or reboots.
RADIUS will track details like session duration, client location and bandwidth, or other resources used during the session.
RADIUS accounting can be used by ISPs to charge for their services.
Securing Your Networks
Secure Network Architecture
Network Hardening Best Practices
Disable the network services that are not needed.
Monitoring network traffic
Analyze the network logs
Network separation
Network hardening
The process of securing a network by reducing its potential vulnerabilities through configuration changes and taking specific steps.
Implicit deny
A network security concept where anything not explicitly permitted or allowed should be denied.
Analyzing logs
The practice of collecting logs from different network and sometimes client devices on your network, then performing an automated analysis on them.
Log analysis systems are configured using user-defined rules to match interesting or atypical log entries.
Normalizing log data is an important step, since logs from different devices and systems may not be formatted in a common way.
This makes correlation analysis easier.
Correlation analysis
The process of taking logs data from different systems and matching events across the systems.
Flood guards
Provide protection against DoS or Denial of Service attacks.
fail2ban
Network Hardware Hardening
To protect against Rogue DHCP server attack, enterprise switches offer a feature called DHCP snooping.
Another form of network hardening is Dynamic ARP inspection.
Dynamic ARP inspection is also a feature of enterprise switches.
IP Source Guard is used to protect against IP spoofing attacks in enterprise switches.
To really hardened your network, you should apply IEEE 802.1X recommendation.
IEEE 802.1x is a protocol developed to let clients connect to port based networks using modern authentication methods.
There are three nodes in the authentication process: supplicant, authenticator, and authentication server.
The authentication server uses either a shared key system or open access system to control who is able to connect to the network.
Based on the criteria of the authentication server, the supplicator will grant the authentication request and begin the connection process, or it will be sent an Access Reject message and terminate the connection.
EAP-TLS
An authentication type supported by EAP that uses TLS to provide mutual authentication of both the client and the authenticating server.
In the ideal world, we all should protect our wireless networks with 802.1X with EAP-TLS.
If 802.1X is too complicated for a company, the next best alternative would be WPA2 with AES/CCMP mode.
But to protect against Rainbow tables attack, we need some extra measures.
A long and complex passphrase that wouldn’t find in a dictionary would increase the amount of time and resources an attacker would need to break the passphrase.
If your company values security over convenience, you should make sure that WPS isn’t enabled on your APs.
Network Monitoring
Sniffing the Network
There are number of network sniffing open source tools like:
Aircrack-ng
Kismet
Packet sniffing (packet capture)
The process of intercepting network packets in their entirety for analysis.
Promiscuous Mode
A type of computer networking operational mode in which all network data packets can be accessed and viewed by all network adapters operating in this mode.
Port mirroring
Allows the switch to take all packets from a specified port, port range, or entire VLAN and mirror the packets to a specified switch port.
Monitor mode
Allows us to scan across channels to see all wireless traffic being sent by APs and clients.
Wireshark and tcpdump
Tcpdump
A super popular, lightweight, command-line based utility that you can use to capture and analyze packets.
Wireshark
A graphical tool for traffic monitoring, that is more powerful and easier to use than tcpdump.
Intrusion Detection/Prevention System
IDS or IPS systems operate by monitoring network traffic and analyzing it.
They look for matching behavior for malicious packets.
IDS on logs the packets, while IPS can change firewall rules on the fly to drop malicious packets.
IDS/IPS may be host-based or network-based.
Network Intrusion Detection System (NIDS)
The detection system would be deployed somewhere on a network, where it can monitor traffic for a network segment or subnet.
Bro NIDS (Rename to the Zeek Network Security Monitor)
Unified Threat Management (UTM)
UTM solutions stretch beyond the traditional firewall to include an array of network security tools with a single management interface. UTM simplifies the configuration and enforcement of security controls and policies, saving time and resources. Security event logs and reporting are also centralized and simplified to provide a holistic view of network security events.
UTM options and configurations
UTM solutions are available with a variety of options and configurations to meet the network security needs of an organization:
UTM hardware and software options:
Stand-alone UTM network appliance
Set of UTM networked appliances or devices
UTM server software application(s)
Extent of UTM protection options:
Single host
Entire network
UTM security service and tool options can include:
Firewalls
IDS
IPS
Antivirus software
Anti-malware software
Spam gateway
Web and content filters
Data leak/loss prevention (DLP)
VPN
Stream-based vs. proxy-based UTM inspections
UTM solutions offer two methods for inspecting packets in UTM firewalls, IPS, IDS, and VPNs:
Stream-based inspection, also called flow-based inspection: UTM ddevices,inspects data samples from packets for malicious content and threats as the packets flow through the device in a stream of data. This process minimizes the duration of the security inspection, which keeps network data flowing at a faster rate than a proxy-based inspection.
Proxy-based inspection: A UTM network appliance works as a proxy server for the flow of network traffic. The UTM appliance intercepts packets and uses them to reconstruct files. Then the UTM device will analyze the file for threats before allowing the file to continue on to its intended destination. Although this security screening process is more thorough than the stream-based inspection technique, proxy-based inspections are slower in the transmission of data.
Benefits of using UTM
UTM can be cost-effective
UTM is flexible and adaptable
UTM offers integrated and centralized management
Risk of using UTM
UTM can become a single point of failure in a network security attack
UTM might be a waste of resources for small businesses
Home Network Security
Employees, who work from home, use home networks to access company files and programs. Using home networks creates security challenges for companies. Companies can provide employees guidance for protecting their home networks from attacks. This reading will cover common attacks on home networks and steps to make home networks more secure.
Common security vulnerabilities
Meddler in the middle attacks allows a meddler to get between two communication devices or applications. The meddler then replies as the sender and receiver without either one knowing they are not communicating with the correct person, device, or application. These attacks allow the meddler to obtain login credentials and other sensitive information.
Data Theft is when data within the network is stolen, copied, sent, or viewed by someone who should not have access.
Ransomware uses malware to keep users from accessing important files on their network. Hackers grant access to the files after receiving a ransom payment.
Keeping home networks secure
Change the default name and password
Limit access to the home network
Create a guest network
Turn on Wi-Fi network encryption
Turn on the router’s firewall
Update to the newer Wi-Fi standard
Defense in Depth
System Hardening
Intro to Defense in Depth
The concept of having multiple, overlapping systems of defense to protect IT systems.
Disabling Unnecessary Components
Two important security risk mitigation components:
Attack Vectors
Attack surfaces
The less complex something is, the less likely there will be undetected flaws.
Another way to keep things simple is to reduce your software deployments.
Telnet access for a managed switch has no business being enabled in a real-world environment.
Attack vector
The method or mechanism by which an attacker or malware gains access to a network or system.
Attack surface
The sum of all the different attack vectors in a given system.
Host-Based Firewall
Protect individuals hosts from being compromised when they’re used in untrusted, potentially malicious environments.
A host-based firewall plays a big part in reducing what’s accessible to an outside attacker.
If the users of the systems have administrator rights, then they have the ability to change firewall rules and configuration.
Bastion Hosts
Bastion hosts are specially hardened and minimized in terms of what is permitted to run on them. Typically, bastion hosts are expected to be exposed to the internet, so special attention is paid to hardening and locking them down to minimize the chances of compromise.
These are servers that are specifically hardened and minimized to reduce what’s permitted to run on them.
Logging and Auditing
Security Information and Event Management (SIEM) system is a centralized log management system.
Once logs are centralized and standardized, you can write an automated alerting based on rules.
Lots of unprotected systems would be compromised in a matter of minutes if directly connected to the internet without any safeguards or protections in place.
Antivirus software will monitor and analyze things, like new files being created or being modified on the system, in order to watch for any behavior that matches a known malware signature.
Antivirus software is just one piece of our anti-malware defenses.
There are binary whitelisting defense software, that only allow white listed programs on the system.
Home directory or file-based encryption only guarantees confidentiality and integrity of files protected by encryption.
Full-disk encryption (FDE)
Works by automatically converting data on a hard drive into a form that cannot be understood by anyone who doesn’t have the key to “undo” the conversation.
When you implement a full disk encryption solution at scale, it’s super important to think how to handle cases where passwords are forgotten.
Key Escrow
Allows the encryption key to be securely stored for later retrieval by an authorized party.
Application Hardening
Software Patch Management
As an IT Support Specialist, it’s critical that you make sure that you install software updates and security patches in a timely way, in order to defend your company’s systems and networks.
The best protection is to have a good system and policy in place for your company.
Critical infrastructure devices should be approached carefully when you apply updates. There’s always the risk that a software update will introduce a new bug that might affect the functionality of the device.
Browser Hardening
The methods include evaluating sources for trustworthiness, SSL certificates, password managers, and browser security best practices. Techniques for browser hardening are significant components in enterprise-level IT security policies. These techniques can also be used to improve internet security for organizations of any size and for individual users.
Identifying trusted versus untrusted sources
Use antivirus and anti-malware software and browser extensions
Check for SSL certificates
Ensure the URL displayed in the address bar shows the correct domain name.
Search for negative reviews of the website from trusted sources.
Don’t automatically trust website links provided by people or organizations you trust.
Use hashing algorithms for downloaded files.
Secure connections and sites
Secure Socket Layer (SSL) certificates are issued by trusted certificate authorities (CA), such as DigiCert. An SSL certificate indicates that any data submitted through a website will be encrypted. A website with a valid SSL certificate has been inspected and verified by the CA. You can find SSL certificates by performing the following steps:
Check the URL in the address bar. The URL should begin with the https:// protocol. If you see http:// without the “s”, then the website is not secure.
Click on the closed padlock icon in the address bar to the left of the URL. An open lock indicates that the website is not secure.
A pop-up menu should open. Websites with SSL certificates will have a menu option labeled “Connection is secure.” Click on this menu item.
A new pop-up menu will appear with a link to check the certificate information. The layout and wording of this pop-up will vary depending on which browser you are using. When you review the certificate, look for the following items:
The name of this suer – Make sure it is a trusted certificate authority.
The domain it was issue to – This is name should match the website domain name.
The expiration date – The certificate should not have passed its expiration date.
Note that cybercriminals can obtain SSL certificates too. So, this is not a guarantee that the site is safe. CAs also vary in how thorough they are in their inspections.
Application Policies
A common recommendation, or even a requirement, is to only support or require the latest version of a piece of software.
It’s generally a good idea to disallow risky classes of software by policy. Things like file sharing software and piracy-related software tend to be closely associated with malware infections.
Understanding what your users need to do their jobs will help shape your approach to software policies and guidelines.
Helping your users accomplish tasks by recommending or supporting specific software makes for a more secure environment.
Extensions that require full access to websites visited can be risky, since the extension developer has the power to modify pages visited.
Creating a Company Culture for Security
Risk in the Workplace
Security Goals
If your company handles credit card payments, then you have to follow the PCI DSS, or Payment Card Industry Data Security Standard.
PCI DSS is subdivided into 6 broad objectives:
Build and maintain a secure network and systems.
Protect cardholder data.
Maintain a vulnerability management program.
Implement strong access control measures.
Regularly monitor and test networks.
Maintain an information security policy.
Measuring and Assessing Risk
Security is all about determining risks or exposure; understanding the likelihood of attacks; and designing defenses around these risks to minimize the impact of an attack.
Security risk assessment starts with threat modeling.
High-value data usually includes account information, like usernames and passwords. Typically, any kind of user data is considered high value, especially if payment processing is involved.
Another way to assess risk is through vulnerability scanning.
Conducting regular penetration testing to check your defenses.
Vulnerability Scanner
A computer program designed to assess computers, computer systems, networks, or applications for weaknesses.
The practice of attempting to break into a system or network to verify the systems in place.
Privacy Policy
Privacy policies oversee the access and use of sensitive data.
Periodic audits of access logs.
It’s a good practice to apply the principle of least privilege here, by not allowing access to this type of data by default.
Any access that doesn’t have a corresponding request should be flagged as a high-priority potential breach that need to be investigated as soon as possible.
Data-handling policies should cover the details of how different data is classified.
Once different data classes are defined, you should create guidelines around how to handle these different types of data.
Data Destruction
Data destruction makes data unreadable to an operating system or application. You should destroy data on devices no longer used by a company, unused or duplicated copies of data, or data that’s required to destroy. Data destruction methods include:
Recycling: erasing the data from a device for reuse
Physical destruction: destroying the device itself to prevent access to data
Outsourcing: using an external company specializing in data destruction to handle the process
If you can, ask for a third-party security assessment report.
Security Training
Helping others keep security in mind will help decrease the security burdens you’ll have as an IT Support Specialist.
Incident Handling
Incident Reporting and Analysis
The very first step of handling an incident is to detect it in the first place.
The next step is to analyze it and determine the effects and scope of damage.
Once the scope of the incident is determined, the next step is containment.
If an account was compromised, change the password immediately. If the owner is unable to change the password right away, then lock the account.
Another part of incident analysis is determining severity, impact, and recoverability of the incident.
Severity includes factors like what and how many systems were compromised, and how the breach affects business functions.
The impact of an incident is also an important issue to consider.
Data exfiltration
The unauthorized transfer of data from a computer.
Recoverability
How complicated and time-consuming the recovery effort will be.
Incident Response
Incident handling requires careful attention and documentation during an incident investigation’s analysis and response phases.
Be familiar with what types of regulated data may be on your systems, and ensure proper procedures are in place to ensure your organization’s compliance.
DRM technologies can be beneficial for safeguarding business-critical documents or sensitive information and helping organizations comply with data protection regulations.
When incident analysis involves the collection of forensic evidence, you must thoroughly document the chain of custody.
Incident Response and Recovery
Update firewall rules and ACLs if an exposure was discovered in the course of the investigation.
Create new definitions and rules for intrusion detection systems that can watch for the signs of the same attack again.
Mobile Security and Privacy
Screen lock
Storage encryption
Apps permissions
Bring Your Own Device (BYOD)
Organizations are taking advantage of the cost savings created by adopting “bring your own device” (BYOD) policies for employees. However, permitting employees to connect personal mobile devices to company networks introduces multiple security threats. There are a variety of security measures that IT departments can implement to protect organizations’ information systems:
Develop BYOD policies
Enforce BYOD policies with MDM software
Distribute MDS settings to multiple OSes through Enterprise Mobile Management (EMM) systems
Require MFA
Create acceptable use policies for company data and resources
Final Project: Creating a Company Culture for Security Design Document
Assignment
In this project, you’ll create a security infrastructure design document for a fictional organization. The security services and tools you describe in the document must be able to meet the needs of the organization. Your work will be evaluated according to how well you met the organization’s requirements.
About the Organization
This fictional organization has a small, but growing, employee base, with 50 employees in one small office. The company is an online retailer of the world’s finest artisanal, hand-crafted widgets. They’ve hired you on as a security consultant to help bring their operations into better shape.
Organization Requirements
As the security consultant, the company needs you to add security measures to the following systems:
An external website permitting users to browse and purchase widgets
An internal intranet website for employees to use
Secure remote access for engineering employees
Reasonable, basic firewall rules
Wireless coverage in the office
Reasonably secure configurations for laptops
Since this is a retail company that will be handling customer payment data, the organization would like to be extra cautious about privacy. They don’t want customer information falling into the hands of an attacker due to malware infections or lost devices.
Engineers will require access to internal websites, along with remote, command line access to their workstations.
Security Plan
This plan will explain the steps required for improving the security of the organization’s existing infrastructure, depending upon their needs and requirements.
Centralized Access Management System
The company should deploy some directory services like OpenLDAP or Windows Active Directory service so:
Centralized management of permissions to company infrastructure
Group based permissions: Only software engineers should have access to the source code, only sales people should have access to the sales data etc.
To better manage passwords, and ability to centrally reset and change them when required.
Revoke Ex-employee’s access to the company infrastructure.
Company network should be divided into Virtual Local Area Networks (VLANS), to containerize every department to their premise.
External Website Security
To make the company’s website secure from external threats:
Make sure admin pages are not exposed on the clearnet. You can robo.txt to tell Google Website Crawler to don’t crawl them.
When a user, signs up for the website or enter any query in the website console, the standards, and methods for query sanitization and validation should be in place.
Make sure the website uses HTTPS to ensure encrypted communication across the servers.
Place firewall rules and IPS/IDS systems for threat detection and prevention.
As the company is involved in the online retail, make sure:
PCI DSS standards are met for secure debit and credit cards transactions.
Only those employees should have access to stored data, that explicitly need it.
Internal Intranet Website
To make the company’s internal website is secure:
Configure the website as such that it should only be accessible through the company’s internal network.
To make sure the employees working away from the office have access to the internal website and other resources, use Virtual Private Networks (VPNs), or Reverse Proxy for secure tunnel.
Remote Connections
To give remote access:
Use Secure Shell (SSH), Virtual Private Networks, or Reverse Proxies.
Firewalls and IPS/IDS Solutions
Host based firewalls should be used on employees’ laptops.
Network-based firewalls should be used to protect the company’s network.
Intrusion Detection and Intrusion Prevention Systems (IDS/IPS) should in-place.
There should be some kind of monitoring and alerting system, to tell you of the suspicious activity on your network.
Firewalls should only allow traffic explicitly mentioned in the rules list, instead of allowing every packet to enter the network.
Wireless Security
To protect wireless traffic:
Use WPA2 security protocol which uses modern cipher technology AES for encryption which is a lot harder to crack than old WEP or WPA.
Install protection against IP Spoofing attacks and Rogue AP attacks.
Divide your network into vLANs, one for guests and one for employees.
Employees AP should use whitelisting MAC address to allow connection to the network.
Employees Laptop Configuration
The laptops should equip with:
Full-disk encryption
Host-based firewalls with whitelisting rules for better security
Managing the accounts and passwords for laptop through AD.
The employees should not leave their laptops logged in and unlocked on their desks or café.
The Company Security Culture
The humans are always the first line of defense for any system or organization, so educating them about the security is more necessary than anything else.
Organize seminar, record short videos, have small sessions occasionally to educate your employees about imminent security threats, and latest security techniques.
Educate them about phishing attacks to avoid any stolen data or credentials.
There should be small exercise including quizzes and real life examples of what not to do in security realm, how to react if you get phished or hacked after every possible cautionary step.
IBM IT Support Professional Certificate
1. Introduction to Technical Support
This is the IBM version of introduction to IT Support. But it also gives information about different ticketing systems and service level agreements. It provides details about job opportunities and different skill levels in the field.
This course is all about building computers and installing different operating systems on them. It also explains about computer connectors and their types, and peripheral devices. In the end, it gives details about how to troubleshoot a system step by step.
3. Introduction to Software, Programming, and Databases
It goes into details about different computing platforms and types of software applications. It also lists down the available web-browsers, types of cloud computing, basics of programming and types of database queries.
It teaches about the types of networks, like LAN, WAN etc. It lists down the storage types and also goes into the details of troubleshooting common networking problems like DNS issues etc.
The global IT spending on devices, including PCs, tablets, mobile phones, printers, as well as data center systems, enterprise software, and communication services came to 4.24 trillion USD in 2021.
It expected to increase by approximately 5.1 percent to around 4.45 trillion USD in 2022.
A computer is a device or system that includes:
Functions of computing
Benefits of computing
Common Computing Devices and Platforms
Stationary computing devices
Remain on a desk, rack, or other stationary location.
Consist of a box or chassis.
Includes processors, storage, memory, input, and output connections.
Memory and storage, often updatable.
Workstations
Used at the office and at home.
Typically, in a hard box containing processors, memory, storage, slots.
Include connections for external devices and wireless connectivity.
Enable memory, storage, and graphic card upgrades.
Use Microsoft Windows, macOS, and Linux OSes.
Servers: functions
Installed on networks
Enabling shared access
Media storage – movies videos, sound
Web servers – websites
Print servers – print documents
File servers – files and documents
Email servers – email storage
Provide fault tolerance for businesses to keep working
Servers: hardware support
Motherboard providers hardware support for multiple:
Processors
Memory (RAM)
Graphic cards
Storage
Port connections
Servers: operating systems
Use operating systems that support distributed workloads:
Console include Microsoft Xbox, Sony PlayStation, and Nintendo
Hardware features enhanced memory caching and graphics processing
Required additional hardware devices such as wired or cabled handheld devices
Usually not upgradable
Mobile devices
Laptop processing power matches desktop performance
Tablets have both business and personal uses
Smartphones are a hub for life management
Portable and Wi-Fi enabled gaming systems abound
Transforming both business and personal life
IoT devices
Contain chips, sensors, input and output capabilities, and onboard software.
Enable the exchange of data with other devices and systems.
Communicate via Wi-Fi, Bluetooth, NFC, Zigbee, and other protocols.
Software updatable, but generally no hardware upgrades.
IoT devices: categorized
Understanding How Computers Talk
Notational systems defined
A system of symbols that represent types of numbers.
Notational systems – decimal
Notational systems – binary
Convert to decimal to binary
Convert binary to decimal
Notational Systems – hexadecimal
Uses 16 digits, referred to as base 16, including the numbers 0 through 9, and the letters A through F.
Enables compact notation for large numbers
Used for MAC addresses, colors, IP addresses, and memory addresses
Convert hex to binary
Note the hex number, and represent each hex digit by its binary equivalent number.
Add insignificant zeros if the binary number has less than 4 digits. For example, write the decimal 10 as 0010.
String (concatenate) all the binary digits together from left to right.
Discard any leading zeros at the left of the concatenated number.
The result is 100100011010.
Data Types
Character Types
ASCII
American Standard Code for Information Interchange:
Developed from telegraph code and first published in 1963.
Translates computer text to human text.
Originally a 7-byte system (to save on transmission costs) representing 128 binary character.
Expanded to 8-bytes representing another 256 characters.
Full charts are available online.
Unicode
Unicode includes ASCII and other characters from languages around the world, as well as emojis.
Web pages use UTF-8.
Popular programming languages use Unicode 16-bit encoding and a few use 32-bit.
Commonly formatted as U+hhhh, known as “code points”, where hhhh is character hexadecimal value.
Conversion services are available online.
An Introduction to Operating Systems
Operating system basics
Operating systems consist of standardized code for:
Input>Output>Processing>Storage
CLI
GUI
Operating system history
The first generation (1945-1955)
Operating systems that worked for multiple computers didn’t yet exist.
All input, output, processing, and storage instructions were coded every time, for every task.
This repetitive code became the basis for future operating systems.
The second generation (1955-1965)
Mainframe computers became available for commercial and scientific use.
Tape drives provided input and output storage.
In 1956, GM Research produced the first single-stream batch operating system for its IBM 704 computing system.
IBM became the first company to create OSes to accompany computers.
Embedded operating systems were developed in the early 1960s and are still in use.
Focus on a single task.
Provide split-second response times.
Real-time operating systems are a type of embedded operating system used in airplanes and air traffic control, space exploration.
As the time passed, real-time OSes started being used in satellite systems, Robotics, Cars/automobiles.
The third generation (1965-1980)
Additional companies began creating their own batch file operating systems for their large computing needs.
Network operating systems were developed during this time.
Provide scalable, fast, accurate, and secure network communications.
Enables workstations to operate independently.
In 1969, the UNIX operating system, operable on multiple computer systems, featured processor time-sharing.
The fourth generation (1980 to now)
Multitasking operating systems enable computers to perform multiple tasks at the same time.
Linux
1991: Linus Torvalds created a small, open source PC operating system.
1994: Version 1.0 released.
1996: Version 2.0 released, included support for network-based SMP benefitting commercial and scientific data processing.
2013: Google’s Linux-based mobile operating system, Android, took 75% of the mobile operating system market share.
2018: IBM acquired Red Hat for $34 billion.
macOS
1999: OS X and macOS, based on UNIX, offered with PowerPC with PowerPC-based Macs.
2006: Apple began selling Macs using Intel Core processors.
2020: Apple began the Apple Silicon chip transition, using self-designed 64-bit, ARM-based Apple M1 processors on new Mac computers.
Windows
1981: MS-DOS launched
1985: Launched a graphical user interface version of the Windows operating system.
1995: Windows 95 catapulted Microsoft’s dominance in the consumer operating system software market.
Today, Microsoft holds about 70% of consumer desktop operating system market share.
Microsoft also offers network, server management, mobile, and phone operating systems.
ChromeOS
2011: Launched ChromeOS, built atop Linux.
Offers a lightweight operating system built for mobile devices.
Requires less local storage and costs less.
Currently composes about 10% of the laptop market.
Mobile operating systems also fit the definition of multitasking operating systems.
Android
iOS
Windows
ChromeOS
Getting Started with Microsoft Windows
Logging into Windows
Four methods of logging into Windows
PIN
Password
Photo
Fingerprint
Using Keyboard Shortcuts
Computing Devices and Peripherals
Identifying Hardware Components and Peripherals
What is a computer component?
A physical part needed for computer functioning, also called “hardware”.
Each component performs a specific task.
Components can be internal or external.
External components connect via ports and connectors.
Without a given component, such as a CPU, a computer system cannot function as desired.
Common internal components
A part inside a computing device:
RAM
Hard Drive
CPU
Peripherals
Connect to the computer to transfer data.
External devices easily removed and connected to a computer.
Connections vary
Examples: Mouse, Printer, and a Keyboard etc.
Categories of peripherals
Input – send commands to the computer
Output – receive commands from the computer
Storage – save files indefinitely
Connectors for Components
A connector is the unique end of a plug, jack, or the edge of a card that connects to a port.
For example, all desktop computer expansion cards have an internal connector that allows them to connect to a slot on the motherboard.
A Universal Serial Bus (USB) connector at the end of a cable is an example of an external connector.
Ports
A connector plugs into an opening on a computer called a port.
A port is the jack or receptacle for a peripheral device to plug into.
Ports are standardized for each purpose.
Common ports include USB ports and HDMI ports.
Input and Pointing Devices
Input Devices
Keyboards
Mouse
Camera
Joystick
Trackball
Pointing Devices
The stylus (Pen)
Input tool
Moves the cursor and sends commands
Generally used on tablets
Uses capacitive technology
Detects heat and pressure
Hard Drives
Hard drives:
are a repository for images, video, audio, and text.
RAM
ROM
HDD/SSD/NVMe
Hard drive performance
Measurement benchmarks
Spin speed: how fast the platter spins.
Access time: how fast the data is retrieved.
Transfer/media rate: how fast the data is written to the drive.
Connecting an internal hard drive
Back up data
transfer the enclosure
Secure with screws
prevent movement
attach to motherboard via SATA/PATA cables
plug into power supply
finally, it can be configured in the disk management utility of windows
Optical Drives and External Storage
Optical drives
Reading and writing data
Laser pressing or “burning”
Burning pits on lands
Reflective disk surface
Storage disks
Single-sided
Double-side
Types of optical drive
Several types
CD-ROM
CD-RW
DVD-ROM
DVD-RW
Blu-ray
Solid state drives
Solid state drive → (SSD)
Integrated circuit assemblies store data
Flash memory
Permanent, secondary storage
AKA “solid state drive” or “solid state disk”
No moving parts
Unlike hard disk drives and floppy drives
External hard drive
File backup and transfer
Capacity: 250 GB to 20 TB
Several file types
USB or eSATA connection
eSATA – signal, not power
Expansion devices
Additional file storage
Usually, USB
Frees hard drive space
Automatically recognized
Known as a “Thumb drive”
Holds up to 2 TB of data
Flash Drives
Combines a USB interface and Flash memory
Highly portable
Weighs less than an ounce
Storage has risen as prices have dropped
Available capacity up to 2 TB
Memory card
Uses Flash memory to store data
Found in portable devices such as portable media players and smartphones
Contained inside a device
Unlike USB drives
Available in both Secure Digital (SD) and Micro Secure Digital (MSD) formats
Display Devices
Defining display devices:
Hardware component for the output of information in visual form
Tactile monitors present information in a fingertip-readable format
Often seen as television sets and computer monitors
Cathode ray tube (CRT) monitors
Create an image by directing electrons beams over phosphor dots
Used in monitors throughout the mid to late 1990s
By 1990, they boasted 800 × 600 pixel resolution
Flat-screen monitors
Also known as liquid crystal display (LCD)/ Think film transistor (TFT)
Digital signal drives color value of each picture element (Pixel)
Replaced CRT monitors
Touchscreens
Use a touch panel on an electronic display
Capacitive technology measures heat and pressure
Often found on smartphones, laptops, and tablets
Projectors
Take images from a computer and display them
the surface projected onto is large, flat, and lightly colored
Projected images can be still or animated
Printers and Scanners
Output devices
“Hardware that shows data in readable form.”
That data can take many forms:
Scanner and speech synthesizer
Unnecessary (though highly useful) for computer function
Printers
Laser/LED
Inkjet
Thermal
Shared printers
IP-based
Web-based
Scanners
Converts images from analog to digital
Flatbed (stand alone) or multifunction device
Faxes and multifunction devices
Facsimile (fax) machines send documents using landlines
Multifunction devices often include fax capabilities
Audio Visual Devices
Defining audio devices
Digital data is converted into an audible format
Components are used to reproduce, record, or process sound
Examples include microphones, CD players amplifiers, mixing consoles, effects units, and speakers
Defining visual devices
Present images electronically on-screen
Typically, greater than 4" diagonally
Examples include smartphones, monitors, and laptop computers
Interfaces and Connectors
Identifying Ports and Connectors
Ports enable devices to connect to computers
Connectors plug into ports
Each port has a unique function and accepts only specific connectors
Interfaces
Point of communication between two or more entities
Can be hardware or software based
Common Interfaces are:
USB
USB connectors
Thunderbolt
Combines data transfer, display, and power
Initial versions reused Mini DisplayPort
New versions reuse USB-C connectors
Identified with a thunderbolt symbol
FireWire
Predecessor to Thunderbolt
FireWire 400 = 400 mBits/second
FireWire 800 = 800 mBits/second
Uses a serial bus to transfer data on e bit at a time
Still used for audio/video connections on older computers (before 2011), and in the automobile and aerospace industries
PS/2
Developed for IBM PS/2
Connects keyboard and mice
Ports are device specific
Green for mice
Purple for keyboard
Considered a legacy port
eSATA
Standard port for connecting external storage devices
Allows hot swapping of devices
Since 2008, Upgraded eSATAp that supports both eSATA and USB on the same port
eSATA revisions:
Revision 1: Speeds of 1.5 Gbps
Revision 2: Speeds of 3 Gbps
Revision 3: Speeds of 6 Gbps
Identifying Graphic Devices
Display Unit
Display unit (GPU) connected to the computer via a display card or adapter
Low-end generic graphic cards come built into the computer
Require specialized adapters for high-end functions
ATI/AMD, nVIDIA, SiS, Intel, and Via are leading manufacturers
Display System
VGA Display System
LED Display System
Display Connectors
Different cables and connectors for different display adapters
Each connector has specific function and benefits
HDMI Interface
Most widely used digital audio and video interface
Also offers remote control and content protection
Uses a proprietary 19-pin connector
Offers up to 8K UHD resolutions
DisplayPort
Royalty-free complement to HDMI
First interface to use packetized data transmission
Uses a 20-pin connector
Can support even different transmission modes of increasing bandwidth
Thunderbolt
Developed by Intel and Apple, primarily for Apple laptops and computers
Can be used as either a display or peripheral interface
Initial versions used the MiniDP interface
Version 3 and now version 4 use the USB-C interface
Thunderbolt features don’t work with a standard USB-C cable and port
Digital Visual Interface (DVI)
Designed as a high-quality interface for flat-paneled devices
Support both analog and digital devices
DVI-I supports both analog and digital
DVI-A supports only analog
DVI-D supports only digital
Single-link for lower resolutions and Dual-link for HDTV
Superseded by HDMI and Thunderbolt
Video Graphics Array (VGA)
A legacy interface, used for analog video on PC
Has a 15-pin connector that can be secured with screws
Identifying Audio Connectors
The audio connection
Onboard or internal expansion
Has multiple ports to connect a variety of devices
Used for multimedia application, education and entertainment, presentation, and teleconferencing
Audio connectors
Sound cards
Bluetooth
Game ports/USB ports
External audio interfaces
External audio interfaces
Single device for multiple input and output ports
Mostly used in professional studies
Use USB, FireWire, Thunderbolt, or similar connectors
Wired and Wireless Connections
Data packets
Communication technology allows components to communicate over a network
Data packets are sent from one smart object to another
Information about the sending and receiving device, along with the message
Devices built to talk over a network can communicate with each other
Network types
Closed (limited number of devices can connect)
Open (unlimited number of devices can connect)
Either could be wired or wireless
Wired connectors
Wire connection benefits
Faster data transmission
Up to 5 Gbps
More reliable than wireless
Immune to signal drops and dead zones
Less prone to radio interference
More secure
Less likely to be hacked
Wireless connections
Use different technologies based on connection requirements
Wireless Fidelity (Wi-Fi)
Connects a router to a modem for network access
Bluetooth
1998
Pairing
Radio-frequency identification (RFID)
Identification and tracks objects using tags
Range up to several hundred meters
Collection of road tolls
Other uses of RFID tags
Livestock tracking, tacking pharmaceuticals through warehouses, preventing theft, and expediting checkout in stores
NFC (Near Field Communication)
Based on RFID
Extremely short range
Transmits data through electromagnetic radio fields
Wireless connection advantages
Increased mobility
Reduced time to set up
Flexibility and scalability
Wider reach
Lower cost of ownership
Peripherals and Printer Connections
Common installation steps
Computers require software that enables peripheral or printer device recognition and communication using:
Onboard Plug and Play software
Device driver software
Device application software
Initial stand-alone, peripheral installation often still requires a wired connection or network connection
Connect the printer to the computer using a cable
Turn on the printer
Frequently used stand-alone peripherals are:
USB
Bluetooth
Wi-Fi
NFC
Three other connection methods are:
Serial port
Parallel port
Network
Serial cable connections
Are less common
Transmit data more slowly
RS232 protocol remains in use
Data can travel longer distances
Better noise immunity
Compatibility among manufacturers
Cables commonly feature 9-pin connections and two screws to secure the cable
Parallel port cable connection
Are less common
Send and receive multiple bits of data simultaneously
Feature 25-pin connections
Include two screws to keep the cable connected
Network connections
Generally, are Wi-Fi or wired Ethernet connections
Before you begin, verify that your computer has a network connection
Connecting to local printers
Installation Types
Plug and Play
Driver Installation
PnP vs. driver installation
PnP devices work as soon as they’re connected to a computer
Examples include mice and keyboards
A malfunctioning device should be investigated in Device Manager.
Possible cause of malfunction is an outdated driver
IP-based peripherals
Hardware connected to a TCP/IP network
Examples of such devices include wireless routers and security cameras
These devices must be connected to a local area network (LAN) or the Internet to function
Web-based configuration
Different from installation
Used for networking devices such as routers
Is an easier process to set up a device
Completed on a web page
Often on the manufacturer’s site
Internal Computer Components
Internal Computer Components
Motherboard
Main printed circuit board (PCB) in computers
Contains significant subsystems
Allows communication among many of the crucial internal electronic components
Enables communications and power distribution for peripherals and other components
Chip sets
A set of electronic components in an integrated circuit
Manage data flow
Have two distinct parts: the northbridge and the southbridge
Manage communications between the CPU and other parts of the motherboard
Chip sets: Northbridge and southbridge
Northbridge – the first half of the core logic chip set on a motherboard
Directly connected to the CPU
Responsible for tasks that require the highest performance
Southbridge – the second half of the core logic chip set
Implements slower-performance tasks
Not directly connected to the CPU
What is a bus?
A high-speed internal connection on a motherboard
Used to send control signals and data internally
The front-side bus carries data between the CPU and the memory controller hub (northbridge)
Sockets
“Components not directly attached to a motherboard connect via sockets”
Array of pins holding a processor and connecting the processor to the motherboard
Differ based on the motherboard
Power connectors
Found on a motherboard
Allow an electrical current to provide power to a device
ATX-style power connectors are larger than most
Join the power supply to the motherboard
Data Processing and Storage
Central Processing Unit (CPU)
Silicon chip in a special socket on the motherboard
Billions of microscopic transistors
Makes calculations to run programs
32-bit is like a two-lane information highway
64-bit is like a four-lane information highway
Memory (RAM)
Typically used to store working data
Volatile: Data existing in RAM is lost when power is terminated
Is cold pluggable (cold swappable)
Speed measured in Megahertz (MHz)
Available in varying speeds
Available in varying storage capacities
Types of Memory
Choice depends on the motherboard
Dynamic Random-Access Memory (DRAM)
Synchronous Dynamic Random-Access Memory (SDRAM)
Double Data Rate Synchronous Dynamic Random-Access Memory (DDR-SDRAM)
Double Data Rate 3 Synchronous Dynamic Access Memory (DDR3 and DDR4)
Small outline Dual Input Memory Module (SO-DIMM)
Memory Slots
Hold RAM chips on the motherboard
Allow the system to use RAM by enabling the motherboard to communicate with memory
Most motherboards include two to four memory slots
Type determines which RAM is compatible
Expansion Slots
Use PCI or PCIe slots
Add additional capabilities
Peripherals (such as sound cards)
Memory
High-end graphics
Network interfaces
Availability depends on the motherboard configuration
Disk Controllers
Circuit that enables the CPU to communicate with hard disk drive
Interface between the hard disk drive and the bus
Integrated Drive Electronics is a standard
IDE controller-circuit board guides how the hard disk drive manages data
Have memory that boosts hard drive performance
BIOS (Basic Input Output System)
Manages your computer’s exchange of inputs and outputs
Preprogrammed into the motherboard
Needs to always operate
Update in a flash
Use the System Summary window
CMOS: Battery and chip
Uses a coin-sized battery
Is attached to the motherboard
Powers the memory chip that stores hardware settings
Replace the computer’s system data, time, and hardware settings
Internal Storage
Hard drive characteristics
Introduced by IBM in 1956, internal hard drives provide:
- Stable, long-term data storage
- Fast access time
- Fast data transfer rates
Traditional hard drive technology
IDE and PATA drives
1980s to 2003:
Integrated Drive Electronics (IDE) hard drives and Parallel Advanced Technology Attachment (PATA) drives were popular industry standard storage options
Early ATA drives: 33 Mbps
Later ATA drives: 133 Mbps
SATA drives
2003 to today:
Serial advanced technology attachment drives (SATA) became an industry standard technology
Communicate using a serial cable and bus
Initial data processing of 1.5 Gbps
Current processing of 6 Gbps
Available in multiple sizes
Spin at 5400 or 7200 rpm
Capacity: 250 GB to over 30 TB
Still dominate today’s desktop and laptop market
Each SATA port supports a single drive
Most desktop motherboards have at least four SATA ports
SCSI drives
1986:
Small computer system interface, pronounced “scuzzy” (SCSI) drives
Historical speeds: 10,000 or 15,000 rpm
1994:
Discontinued usage
Solid-state drives
1989:
Solid-state drives (SSDs) came to market
Consist of nonvolatile flash memory
Provide faster speeds: 10 to 12 Gbps
Capacity: 120 GB to 2 TB
Cost: More expensive than SATA or SCSI drives but also more reliable
Available as internal, external, and hybrid hard drives
As part of an internal hybrid configuration:
SSD serves as a cache
SATA drive functions as storage
Hybrid drives tend to operate slower than SSD drives
Optical Drives
1992:
Invented in the 1960s, but came to the market in 1992.
CDs and DVDs provide nonvolatile storage.
Optical drives use low-power laser beams to retrieve and write data.
Data is stored in tiny pits arranged in a spiral track on the disc’s surface.
CDs and DVDs compared
Blu-ray discs
Media specific for movies and video games
Provide high resolution
Single-sided, but with up to four layers
Store 25 GB per layer
Writable Blu-ray discs exist in 100 GB and quad-layer 128 GB formats
Writable Blu-ray discs require BD-XL-compatible drives
Expansion Slots
Locations on the motherboard where you can add additional capabilities, including hard drive storage
Display Cards and Sound Cards
Video card
An expansion card installed in an empty slot on the motherboard
Or a chip built into a system’s motherboard
Allows the computer to send graphical information to a video display device
Also known as a display adapter, graphics card, video adapter, video board, or video controller
Graphics processing unit (GPU)
Specialized processor originally designed to accelerate graphics rendering
Process many pieces of data simultaneously
Machine learning, video editing, and gaming applications
Several industries rely on their power processing capabilities
Audio card
Also known as a sound card
Integrated circuit that generates an audio signal and send it to a computer’s speakers
Can accept an analog sound and convert it to digital data
Usually built into PC motherboard
Users desiring higher-quality audio can buy a dedicated circuit board
MIDI controller
A simple way to sequence music and play virtual instruments and play virtual instruments on your PC
Works by sending musical instrument digital interface (MIDI) data to a computer or synthesizer
Interprets the signal and produces a sound
Frequently used by musicians
Network Interface Cards
A hardware component without which a computer cannot connect to a network
A circuit board that provides a dedicated network connection to the computer
Receives network signals and translates network signals and translates them into data that the computer displays
Types of NIC
Provides a connection to a network
Usually, the Internet
Onboard: built into motherboard
Add-on: fit into expansion slot
No significant difference in speed or quality
Wired and wireless network cards
Wireless – use an antenna to communicate through radio frequency waves on a Wi-Fi connection
Wired-use an input jack and a wired LAN technology, such as fast Ethernet
Modems
Connects your system to the Internet.
Translates ISP signals into a digital format.
Then feeds those digitized signals to your router, so you can connect to a network.
Cooling and Fans
System cooling
Computers generate heat
Excessive heat can damage internal components
Never operate a computer w/out proper cooling
Designed to dissipate heat produced by the processor
Allow the accumulated heat energy to flow away from vital internal parts
Cooling methods
Passive
Active
Fans draw cool air through front vents and expel warm air through the back
Forced convection
Using thermal paste and a baseplate
Cooling methods – heat sink
Heat sink
Use heat sink compound to fill gaps
Place the heat sink over the CPU
Excess heat is drawn away
Before warm air can damage the internal components
Liquid-based cooling
Quieter and more efficient than fans
Water blocks rest atop the chip
Cool liquid in the blocks cool the chip
Heated fluid is pumped to a radiator-cooled by fans.
That fluid goes back to the water block to repeat the cycle.
Workstation Setup Evaluation and Troubleshooting
Managing File and Folders
Rules for naming files and folders
Name so the file or folder you want is easy to find
Make names short but descriptive
Use 25 characters or fewer
Avoid using special characters
Use capitals and underscores
Consider using a date format
Introduction to Workstation Evaluation, Setup, and Troubleshooting
Screen Capture and Tools
Screen capture on macOS
Saves screenshots on the desktop.
Command + shift +3
Capture entire screen
Command + shift +4
Capture part of the screen
Command + shift +5
Capture as photo/video
Screen captures on Windows
Saves screenshots to the screenshot folder.
Windows + PrintSc
Capture entire screen
Alt + PrintSc
Capture active window
Windows + Shift + S (Opens up snip and sketch tool)
Entire screen
Part of the screen
Active window
Screen captures on a Chromebook
Saves screenshots to Downlaods or Google Drive.
Ctrl + Show Windows
Capture entire screen
CTRL + shift + show windows
Capture part of the screen
Evaluating Computing Performance and Storage
Assessing processor performance
The processor’s speed
The number of cores
The bus types and speeds
Located on the processor’s perimeter
The data highway wiring from the processor to other board components
The presence of cache or other onboard memory
Bus types
Historically, three bus types:
Bus alternatives
Replacement technologies include:
And others.
Cache
Consist of processor platform memory that buffers information and speeds tasks
Can help offset slower processor speeds
Storage
RAM error symptoms
Screen or computer freezes or stops working
Computer runs more slowly
Browser tabs error or other error messages display
Out-of-memory or other error messages display
Files become corrupt
Computer beeps
A “blue screen” with an error message displays
Workstation Evaluation and Setup
Identifying user needs
Environment: Where does the use work?
What are the user’s workspace conditions?
Network access: What are the user’s options?
Data storage requirements:
Application requirements:
Evaluating peripheral needs
Suggested computing solutions
Evaluating computing options
Purchasing decisions
Four important considerations:
Workstation setup
Environment
Is a desk present or needed? If so, is the desk safe and sturdy?
Is a chair present? If so, is the chair safe and sturdy?
Is lighting present?
Are electrical outlets present, of appropriate amperage and grounded?
Can the use physically secure the computer?
Unboxing
Read and follow the manufacturer’s practices for workstation setup
Move boxes and packing materials into a safe location, out of the user’s workspace
Cable management
Reduce service calls with three practices
Install shorter cable lengths where possible
Securely attach and identify each cable
Collect and tie the cables together
Electrical
Safety for you and your user:
Label each electric cable.
Verify that electrical connections are away from the user and are accessible.
Connect power supplies to their assigned wall or power strip location. Note the wall outlet number.
Ergonomics
Can the user work comfortably?
Feet are on the floor.
Monitor at or just below eye height.
Arms are parallel with the keyboard, table, and chair.
Shoulders are relaxed and not hunched.
The environment provides enough light to see the display and keyboard.
Cords and cables are out of the way.
Workstation setup
Power on the workstation and peripherals
Setup the operating system and options for the user:
User logon credentials
Keyboard options
Monitor resolution
Printer connections
Sound options
Security options
Network connections
Select the user’s default browser
Uninstall bloatware or unnecessary software
Install and configure additional productivity software
Modify the desktop Productivity pane
Setup backup options
Introduction to Troubleshooting
3 Basic Computer Support Concepts
Determining the problem
Ask questions
Reproduce the problem
Address individual problems separately
Collect information
Examining the problem
Consider simple explanations
Consider all possible causes
Test your theory
Escalate if needed
Solving the problem
Create your plan
Document the process beforehand
Carry out the solution
Record each step
Confirm the system is operational
Update your documentation
Troubleshooting
“Troubleshooting is a systematic approach to problem-solving that is often used to find and correct issues with computers.”
Troubleshooting steps
Gathering information
Duplicating the problem
Triaging the problem
Identifying symptoms
Researching an online knowledge base
Establishing a plan of action
Evaluating a theory and solutions
Implementing the solution
Verifying system functionality
Restoring Functionality
Common PC issues
Internet Support
Manufacturer Technical Support
Before contacting support:
Have all documentation
Be prepared to provide:
Name of the hardware/software
Device model and serial number
Date of purchase
Explanation of the problem
CompTIA troubleshooting model
The industry standard troubleshooting model comes from The Computing Technology Industry Association (CompTIA)
CompTIA model steps
Identify the problem
Gather information
Duplicate the problem
Question users
Identify symptoms
Determine if anything has changed
Approach multiple problems individually
Research knowledge base/Internet
Establish a theory of probable cause
Question the obvious
Consider multiple approaches
Divide and conquer
Test the theory to determine the cause
Establish a plan of action
Implement the solution or escalate
Verify fully system functionality and implement preventive measures
Document findings/lessons, actions, and outcomes
Advanced Microsoft Windows 10 Management and Utilities
Policy management
Applies rules for passwords, retries, allowed programs, and other settings
Type “group policy” in the taskbar search box
View Edit group policy and click open
Select the User Configuration settings to view its details and edit policy settings
Process management
Schedules processes and allocates resources
Task manager
Memory management
Windows uses:
RAM for frequent memory tasks
Virtual memory for less-frequent tasks
When you notice that:
Performance is slow
You see errors that report “low on virtual memory”
Service management
Automatically manages background tasks and enables advanced troubleshooting of performance issues.
Capabilities include:
Stopping services
Restarting services
Running a program
Taking no action
Restarting the computer
Driver configuration
Drivers are the software components that enable communications between the operating system and the device
Utilities
Utilities help you administer and manage the operating system:
Subsections of Software, Programming, and Databases
Computing Platforms and Software Application
A computing platform is the environment where the hardware and the software work together to run applications.
Hardware is the type of computer or device, such as a desktop computer, a laptop, or a smartphone.
Software refers to the type of operating system (OS), such as Windows, macOS, iOS, Android and Linux, and the programs and applications that run on the OS.
Types of computing platforms
Desktop platform
Includes personal computers and laptops that run operating system like Windows, macOS, and Linux.
Web-based platform
Includes modern browsers like Firefox, and Chrome that function the same in various operating system, regardless of the hardware.
Mobile platform
Includes devices like Pixel and the iPhone that run operating systems like Android OS and iOS.
Single-platform vs. cross-platform
Compatibility concerns
Cross-platform software acts differently or may have limited usability across devices and platforms.
Software is created by different developers, and programs may interpret the code differently in each application.
Functionality and results differ across platforms, which might mean undesired results or a difference in appearance.
Commercial and Open Source Software
Commercial Software
Commercial Proprietary Closed source
Copyrighted software, which is identified in the End User License Agreement (EULA).
Private source code, which users are not allowed to copy, modify, or redistribute.
Developed for commercial profit and can include open source code bundled with private source code.
Commercial software usually requires a product key or serial number to certify that software is original.
Some commercial software is free, but upgrades and updates may cost extra, or the software contains ads.
Examples: Microsoft Office, Adobe Photoshop, and Intuit QuickBooks.
Open source software
Open source: Free and open source (FOSS)
Free software, which can be downloaded, installed, and used without limits or restrictions
Free source code, which can be freely copied, modified, and redistributed.
Open access to the software functions and software code without cost or restrictions.
Developers and users can contribute to the source code to improve the software.
Open source software requires users to agree to an End User License Agreement (EULA) to use the software.
Examples: Linux, Mozilla Firefox, and Apache OpenOffice.
Software Licenses
What is a software license?
A software license states the terms and conditions for software providers and users.
It is a contract between the developer of the source code and the user of the software.
It specifies who owns the software, outlines copyrights for the software, and specifies the terms and duration of the license.
Likewise, it states where the software can be installed, how many copies can be installed, and how it can be used.
Not only that, but it can be lengthy and full of definitions, restrictions, and penalties for misuse.
Agreeing to licensing terms
If you want to use software, you must agree to the licensing terms and requirements, called an End-User License Agreement (EULA).
Agreeing means you accept the terms of the license, such as how many computers the software can be installed on, how it can be used, and what the limitations on developer liability are.
Different software programs and applications have various ways of presenting their EULAs.
Types of software licenses
Single-use license
Allows single installation.
Allows installation on only one computer or device.
Ideal for a single user to install on computers or devices owned only by the user.
Group use, corporate, campus, or site license
Allows multiple installation for specified number of multiple users.
Allows installation on many computers or devices.
Idea for use with computers and devices that are required and owned by organizations.
Concurrent license
Allows installation on many computers, but can only use concurrently by a lower number.
Allows many users to have access, but is not used often by a lot of people at once.
Ideal for companies that do not have all workers using the software at the same time.
Software licensing cost
Costs vary, depending on the type of software, how it will be used, and how much was spent to develop the software.
The cost is for the license to use the software.
Several options are available, such trial subscription, and one-time purchase.
Trial licenses are usually free for a limited time, for a user to decide if they want to purchase the software.
Subscription or one-time licenses
Software Installation Management
Before installing software
Read application details and be selective.
Avoid ads or other unwanted software.
Avoid downloading software that contains malware.
Review permissions requests to access other apps and hardware on your device.
Be selective when allowing application privileges.
Installing software
Consider minimum system requirements, such as:
Minimum processor speed
Minimum amount of RAM
Minimum amount of hard disk space available
Compatible OS versions
Additional requirements may be:
Specific display adapter
Amount display adapter RAM
Internet connection to use the software.
Software versions
Software versions are identified by version number.
Version numbers indicate:
When the software was released.
When it was updated.
If any minor changes or fixes were made to the software.
Software developers use versioning to keep track of new software, updates, and patches.
Version numbers
Version numbers can be short or long, with 2,3, or 4 sets.
Each number set is divided by a period.
An application with a 1.0 version number indicated the first release.
Software with many releases and updates will have a larger number.
Some use dates for versioning, such as Ubuntu Linux version 18.04.2 released in 2018 April, with a change shown in the third number set.
What do version numbers mean?
Some version numbers follow the semantic numbering system and have 4 parts separated by a period.
The first number indicates major changes to the software, such as a new release.
The second number indicated that minor changes were made to a piece of software.
The third number in the version number indicates patches or minor bug fixes.
The fourth number indicates build numbers, build dates, and less significant changes.
Version compatibility
Older versions may not work as well in newer versions.
Compatibility with old and new versions of software is a common problem.
Troubleshooting compatibility issues by viewing the software version.
Update software to a newer version that is compatible.
Backwards-compatible software functions properly with older versions of files, programs, and systems.
Productivity, Business, and Collaboration Software
Types of software
Productivity software enables users to be productive in their daily activities.
Business software is related to work tasks and business-specific processes.
Collaboration software enables people to work together and communicate with each other.
Utility software helps manage, maintain, and optimize a computer.
Note: A program or application can be categorized as multiple types of software.
What is productivity software?
“Productivity software is made up of programs and application that we use every day.”
Types of productivity software
What is business software?
Programs and applications that help businesses complete tasks and function more efficiently are considered business software.
Some business software is uniquely designed to meet an industry-specific need.
Types of business software
What is collaboration software?
Collaboration software helps people and companies communicate and work together.
Collaboration software can also be business software, but they are not interchangeable.
The primary purpose is to help users create, develop, and share information collaboratively.
Types of collaboration software
What is utility software?
Utility software runs continuously on a computer without requiring direct interaction with the user.
These programs keep computers and networks functioning properly.
Utility software
Types of File Formats
Executable files
Executable files run programs and applications.
Some executable file format extensions are:
EXE or .exe for Windows applications
BAT or .bat for running a list of commands
SH or .sh for shell commands on Linux/Unix
CMD or .cmd for running command in order
APP or .app for Mac application bundles
MSI or .msi for installer package on Windows
Common compression formats
Common audio and video formats
Audio and video formats often share the same extensions and the same properties.
Some audio formats:
WAV
MPEG, including MP3 and MP4
AAC
MIDI
Some video formats:
AVI
FLV
MPEG, including MP4 and MPG
WMV
Images formats
Some common image formats are:
Document formats
Some examples of document formats and extensions:
TXT / .txt for text files
RTF / .rtf for rich text format
DOCX and DOC / .docx and .doc for Microsoft Word
XLSX and XLS / .xlsx and .xls Microsoft Excel
PDF / .pdf for Adobe Acrobat and Adobe Reader
PPTX and PPT / .pptx and .ppt for PowerPoint
Fundamentals of Web Browsers, Applications, and Cloud Computing
Common Web Browsers
Web Browser components
Browser installs and updates
Importance of browser updates
Compatibility with websites
Security
New features
Frequency of browser updates
Most web browsers update at the same frequency:
Major updates every four weeks
Minor updates as needed within the four-week period
Security fixes, crash fixes, policy updates
Some vendors offer an extended release:
Major updates are much less frequent
Better for structured environments
Malicious plug-ins and extensions
Malicious plug-ins and extensions typically not displayed in list of installed apps and features.
Use an anti-malware program to remove them.
Use trusted sources for plug-ins and extensions to avoid malware.
Basic Browser Security Settings
What is a proxy server?
Acts as go-between when browsing the web.
The website thinks the proxy is the site visitor.
Protects privacy or bypass content restrictions.
Allows organizations to maintain web security, web monitoring, and content filtering.
Controls what, when, and who.
Reduces bandwidth consumption and improves speed.
How does a proxy server work?
Proxy servers perform network address translation to request and retrieve web content on behalf of requesting computers on the network.
Managing cookies
Cookies:
Small text-based data stores information about your computer when browsing
Save session information
More customized browsing experience
Example: Online shopping basket
Cookies can be useful but could be malicious too:
Tracking browsing activity
Falsifying your identity
What is cache?
Cache is temporary storage area
Stores web data, so it can be quickly retrieved and reused without going to original source
Cache is stored on local disk
Improves speed, performance, and bandwidth usage
Cache can be cleared when no longer needed
Browser Security Certificates and Pop-ups Settings
Security certificates
Good security practice to check websites’ authenticity
Look for HTTPS in URL and padlock icon
‘Connection is secure’
If it says ‘not secure’ be wary
Certificate expired
Issuing CA not trusted
Script and pop-ups blockers
Pop-ups:
Typically are targeted online ads
Can be annoying and distracting
Can be malicious
Associated with ‘innocent’ actions
Take care when interacting with pop-ups
Popular third-party pop-up blockers:
Adlock
AdGuard
AdBlock
Ghostery
Adblock Plus
May provide additional features such as ad filtering.
Private Browsing and Client-side Scripting Settings
Private browsing mode that doesn’t save:
History
Passwords
Form data
Cookies
Cache
Only hidden locally
ISPs, websites, workplace can view data
Client-side scripting
Web pages were static in early days of WWW
Dynamic web pages adapt to situation/user
Server-side scripting performed by server hosting dynamic pages
Client-side scripting performed by client’s web browser
Code is embedded in web page
JavaScript
Pros
Client-side scripts are visible to user
No reliance on web server resources
Cons
Client-side scripts have security implications
Malware developers constantly trying to find security flaws
You may need to disable client-side scripts
Should you disable JavaScript?
Pros of disabling
Security
Browsing speed
Browser support
Disabled cookies
Cons of disabling
Lack of dynamic content
Less user-friendly browsing experience
Website navigation
Introduction to cloud computing and cloud deployment and service models
What is cloud computing?
Delivery of on-demand computing resources:
Networks
Servers
Storage
Applications
Services
Data centers
Over the Internet on a pay-for-use basis.
Applications and data users access over the Internet rather than locally:
Online web apps
Secure online business applications
Storing personal files
Google Drive
OneDrive
Dropbox
Cloud computing user benefits
No need to purchase applications and install them on local computer
Use online versions of applications and pay a monthly subscription
More cost-effective
Access most current software versions
Save local storage space
Work collaboratively in real time
Cloud computing
Five characteristics
Three deployment models
Three service models
Cloud computing characteristics
ON-demand self-service
Broad network access
Resource pooling
Rapid elasticity
Measured service
Cloud deployment models
Public Cloud
Private Cloud
Hybrid cloud
Cloud service models
IaaS
PaaS
SaaS
Application Architecture and Delivery Methods
Application Architecture models
How will an application be use?
How will it be accessed?
One-tier model
Single-tier model
Also called monolithic model
Applications run on a local computer
Two-tier model
Workspace-based client – Personal computer
Web server – Database server
Three-tier model
Workspace-based client
Application server or web server
Additional server (Database)
Each tier can be:
Individually developed and updated by a separate team
Modified and upgraded without affecting the other tiers
N-tier model
A number of tiers
Multi-tier model
Workspace-based client
Web server or database server
Security
Additional servers
Preferred for the microservices pattern and Agile model
Pros
Changes can be made to specific tiers
Each tier can have its own security settings
Different tiers can be load balanced
Tiers can be individually backed up by IT administrators
Cons
Changes to all tiers may take longer
Application Delivery methods
Local installation
Hosted on a local network
Cloud hosted
Software Development Life Cycle
Introduction to the SDLC
Structured methodology that defines creating and developing software
Detailed plan to develop maintain, or enhance software
Methodology for consistent development that ensures quality production
Six major steps
Requirement analysis and planning
Design
Coding or implementation
Testing
Deployment
Maintenance
SDLC models
Waterfall
Linear sequential model
Output of one phase is input for the next phase
Next doesn’t start until work is completed on the previous phase
Iterative
Iterative incremental model
Product features developed iteratively
Once complete, final product build contains all features
Spiral
Uses waterfall and prototype models
Good for large projects
Largely reduces risk
Planning, risk analysis, engineering, and evaluation
Follows an iterative process
V-shaped
Verification and validation model
Coding and testing are concurrent, implemented at development stage
Agile
Joint development process over several short cycles
Teams work in cycles, typically two to four weeks
Testing happens in each sprint, minimizes risk
Iterative approach to development
At the end sprint, basic product developed for user feedback
Process is repeated every sprint cycle
Four core values of agile model
Individuals and interactions over process and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following plan
Lean
Application of lean principles
Focuses on delivery speed
Continuous improvement
Reducing waste each phase
Seven rules of Lean Model
Build in quality
Create knowledge
Defer commitment
Deliver fast
Respect people
Optimize the whole
DevOps evolved from Agile and Lean principles
Development and Operations teams work collaboratively
Accelerate software deployment
Traditional SDLC vs. Agile
Basics of Programming
Interpreted and Compiled Programming Languages
Programming Languages
Common programming languages categories:
Interpreted
Compiled
Many programming languages are compiled and interpreted
The developer determines which languages is best suited for the project
Interpreted programming
Some interpreted programming languages are outdated
Some are more versatile and easier to learn languages
Interpreted programming languages need an interpreter to translate the source code
Translators are built into the browser or require a program on your computer to interpret the code
Interpreted programming examples
Compiled programming
Programs that you run on your computer
Packaged or compiled into one file
Usually larger programs
Used to help solve more challenging problems, like interpreting source code
Examples
Examples of compiled programming languages are:
C, C++ and C# are used in many operating systems, like Microsoft. Windows, Apple macOS, and Linux
Java works well across platforms, like the Android OS
Compiled programming
Comparing Compiled and Interpreted Programming Languages
Choosing a programming language
Developers determine what programming language is best to use depending on:
What they are most experienced with and trust
What is best for their users
What is the most efficient to use
Programming Languages
Interpreted Programming Languages
Also called script code or scripting, used to automate tasks
Interpreter programs read and execute the source code line by line
The source code need to be executed each time
Runs on almost any OS with the right interpreter
Compiled programming languages
Also called programming languages
Used for more complex programs that complete larger tasks
Larger programs installed on the computer or device
Longer time to write the code but runs faster
Grouped into one downloadable file
Interpreted vs. compiled
Programming Language examples
C, C++, C#:
Compiled programming language
C is the original language, C++ and C# are variations
Case sensitive
Basis for Windows and many operating systems
Takes more time to learn and use for coding but requires less memory and code runs faster
Java:
Compiled programming language
Case-sensitive, object-oriented programming language
Requires Java Virtual Machine (JVM) to run the code
Programming language for Android OS
Cross-platform language that runs the same code on macOS, Windows and Linux
Python:
Interpreted programming language
Scripting language
General-use, case-sensitive
Used with Windows, macOS, and Linux OSes and with server-side web app code
Requires Python engine to interpret code
JavaScript:
Interpreted
Scripting language that runs on client side web browsers
Case insensitive
Simple scripts are run with HTML
Complex scripts are run in separate files
Not to be confused with Java, the compiled programming language
HTML:
Interpreted
HyperText Markup Language
Mostly case-insensitive
Uses tags to format web pages on client-side web browsers
Query and Assembly Programming Languages
Programming language levels
High-level programming languages
More sophisticated
Use common English
SQL, Pascal, Python
Low-level programming languages
Use simple symbols to represent machine code
ARM, MIPS, X86
Query languages
A query is a request for information from a database
The database searches its tables for information requested and returns results
Important that both the user application making the query and the database handling the query are speaking the same language
Writing a query means using predefined and understandable instructions to make the request to a database
Achieved using programmatic code (query language/database query language)
Most prevalent database query language is SQL
Other query languages available:
AQL, CQL, Datalog, and DMX
SQL vs. NoSQL
NoSQL (not only SQL)
Key difference is data structures
SQL databases:
Relational
Use structured, predefined schemas
NoSQL databases:
Non-relational
Dynamic schemas for unstructured data
How does a query language work?
Query language is predominantly used to:
Request data from a database
Create, read, update, and delete data in a database (CRUD)
Database consists of structured tables with multiple rows and columns of data
When a user performs a query, the database:
Retrieves data from the table
Arranges data into some sort of order
Returns and prevents query results
Query statements
Database queries are either:
Select commands
Action commands (CREATE, INSERT, UPDATE)
More common to use the term “statement”
Select queries request data from a database
Action queries manipulate data in a database
Common query statements
Query statement examples
SELECT * FROM suppliers;
SELECT name FROM suppliers, WHERE name = ‘Mike’;
CREATE DATABASE products;
DROP TABLE suppliers;
ALTER TABLE suppliers;
DROP COLUMN firstname;
SELECT AVG(purchases);
FROM suppliers;
Assembly languages
Less sophisticated than query languages, structured programming languages, and OOP languages
Uses simple symbols to represent 0s and 1s
Closely tied to CPU architecture
Each CPU type has its own assembly language
Assembly language syntax
Simple readable format
Entered one line at a time
One statement per line
{label}mnemonic{operandlist}{;comment}
mov TOTAL, 212;Transfer the value 212 in the memory variable TOTAL
Assemblers
Assembly languages are translated using an assembler instead of a compiler or interpreter
One statement translates into just one machine code instruction
Opposite to high-level languages where one statement can be translated into multiple machine code instructions
Translate using mnemonics:
Input (INP), Output (OUT), Load (LDA), Store (STA), Add (ADD)
Statements consist of:
Opcodes that tell the CPU what to do with data
Operands that tell the CPU where to find the data
Understanding Code Organization Methods
Code organization is important
Planning and organizing software design:
Enables writing cleaner, more reliable code
Helps improve code base
Reduce bugs and errors
Has a positive impact on program quality
Provides consistent and logical format while coding
Pseudocode vs. flowcharts
Pseudocode
Flowcharts
Informal, high-level algorithm description
Pictorial representation of algorithm, displays steps as boxes and arrows
Step-by-step sequence of solving a problem
Used in designing or documenting a process or program
Bridge to project code; follows logic
Good for smaller concepts and problems
Helps programmers share ideas without extraneous waste of a creating code
Provide easy method of communication about logic behind concept
Provides structure that is not dependent on a programming language
Offer good starting point for project
Flowcharts
Graphical or pictorial representation of an algorithm
Symbols, shapes, and arrows in different colors to demo a process of program
Analyze different methods of solving a problem or completing a process
Standard symbols to highlight elements and relationships
Flowchart software
Provides ability to create flowcharts
Drag functionality
Easy-to-use interface
Team collaboration creating flowcharts
Examples:
Microsoft Visio
Lucidchart
Draw.io
DrawAnywhere
Pseudocode advantages
Simply explains each line of code
Focuses more on logic
Code development stage is easier
Words/phrases represent lines of computer operations
Simplifies translation
Code in different computer languages
Easier review by development groups
Translates quickly and easily to any computer language
More concise, easier to modify
Easier than developing a flowchart
Usually less than one page
Branching and Looping Programming Logic
Introduction to programming logic
Boolean expressions and variables
Branching programming logic
Branching statements allow program execution flow:
if
if-then-else
Switch
GoTo
Looping programming logic
There are three basic loop statements:
While loop: Condition is evaluated before processing, if true, then loop is executed
For loop: Initial value performed once, condition tests and compares, if false is returned, loop is stopped
Do-While loop:Condition always executed after the body of a loop
Introduction to Programming Concepts, Part 1
What are identifiers?
Software developers use identifiers to reference program components
Stored values
Methods
Interfaces
Classes
Identifiers store two types of data values:
Constants
Variables
What are containers?
Special type of identifier to reference multiple program elements
No need to create a variable for every element
Faster and more efficient
Examples:
To store six numerical integers – create six variables
To store 1,000+ integers – use a container
Arrays
Simplest type of container
Fixed number of elements stored in sequential order, starting at zero
Declare an array
Specify data type (Int, bool, str)
Specify max number of elements it can contain
Syntax
Data type > array name > max array size [ ]
int my_array[50]
Vectors
Dynamic size
Automatically resize as elements are added or removed
a.k.a. ‘Dynamic arrays’
Take up more memory space
Take longer to access as not stored in sequential memory
Syntax
Container type/data type in <>/name of array
vector <int> my_vector;
Introduction to Programming Concepts, Part 2
What are functions?
Consequence of modular programming software development methodology
Multiple modular components
Structured, stand-alone, reusable code that performs a single specific action
Some languages refer to them as subroutines, procedures, methods, or modules
How functions work
Functions take in data as input
Then process the data
Then return the result as output
Types of functions
Standard library functions – built-in functions
if, else, while, print
User-defined functions – you write yourself
Once a function is written, you can use it over and over
Blocks of code in a function are identified in different ways
Use {}
Use begin-end statements
Use indentations
Using function
Define a function (create)
Function keyword, unique name, statements
Call a function (invoke)
Specified actions are performed using supplied parameters
Declare a function (some programming languages)
C, C++
What are objects?
Objects are key to understanding object-oriented programming (OOP)
OOP is a programming methodology focused on objects rather than functions
Objects contain data in the form of properties (attributes) and code in the form of procedures (methods)
OOP packages methods with data structures
Objects operate on their own data structure
Objects in programming
Consist of states (properties) and behaviors (methods)
Store properties in field (variables)
Expose their behaviors through methods (functions)
Database Fundamentals
Types of Data, Sources, and Uses
What is data?
A set of characters gathered and translated for some purpose, usually analysis
Common types:
Single character
Boolean (true or false)
Text (string)
Number (integer or floating point)
Picture
Sound
Video
Forms of data
Types of data
Categorized by level and rigidity
Structured data
Structured in rows and columns
Well-defined with rigid structure
Relational databases
Microsoft SQL server
IBM Db2
Oracle database
Semi-structured data
Some organizational properties
Not in rows or columns
Organized in hierarchy using tags and metadata
Non-relational database
Unstructured data
No identifiable structure, specific format, sequence, or rules
Most common include text, email
Also images, audio files, and log files
Examples of Semi and Unstructured data
MonoDB
Hbase
Cassandra DB
Oracle NoSQL DB
Data Sources
Using data
Data sources may be internal or external
Internal
Collects data from reports or records from organization
Known as internal sourcing
Accounting
Order processing
Payroll
Order shipping
External
Collects data from outside the organization
Known as external sourcing
Social media feeds
Weather reports
Government
Database and research
Database Fundamentals and Constructs
What is a database?
Components of a database
Schema
Collection of tables of data
A database can have more than one schema
Table
One or more columns of data
Two or more columns of stored data
Column
A pillar of information containing one or more data or values
Can contain dates, numeric or integer values, alphabetic values
Row
A horizontally formatted line of information like rows in Excel
100s or 1000s rows of data are typically in a table
Database constructs
Queries
Request for data
Provide answers
Perform calculations
Combine data
Add, change, or delete data
Constraints
Primary and foreign key enforce rules
Values in columns not repeated
Limit the type of data
Ensure data accuracy and reliability
Database query
Database constraints
Database characteristics
Flat file vs. database
Flat File
Database
Stores data in single table
Uses multiple table structures
Set in various application types
Tables are organized in rows and columns
Sorted based on column values
One piece of data per column
Solution for simple tasks
Faster, more efficient, more powerful
Database Roles and Permissions
Database permissions
Three types of permissions:
Database
Right to execute a specific type of SQL statement
Access second person’s object
Controls use of computing resources
Does not apply to DBA
System
Right to perform any activity
Ability to add or delete columns and rows
Object
Right to perform specific actions
Allows user to INSERT, DELETE, UPDATE, or SELECT data
Object’s owner has permissions for object
Permission commands
Database roles
Benefits of roles
Database types
Structured data type
Tabular data, columns, and rows
These databases are called relational databases
Formed set of data
All rows have same columns
Semi-structured data type
Some structure
Documents in JavaScript Object Notation (JSON) format
Include key-value stores and graph database
Unstructured data type
Not in pre-defined structure or data model
Text heavy files, but may contain numbers and dates
Videos, audio, sensor data, and other types of information
Relational database
Relational
Non-Relational
Structured to recognize relations among stored items of information
Stores data in a non-tabular form, and tends to be more flexible than the traditional, SQL-based, relational database structures
Non-relational database
Permit storing, store data in a format that closely meets the original structure.
Most common types of data stores:
Document data stores
Handles
Objects
Data values
Named string fields in an entity referred to as a document
Generally store data in the form of JSON documents
Key-value stores
Column-oriented databases
Graph databases
Interfacing with Databases
What is a database interface?
Enable users to input queries to a database
Principles of a database interface
How to access a database
Types of access:
Direct
Enters SQL commands
Selects a menu
Accesses tables directly
Works well with locally stored database or local area network
Programmatic
Accesses’ database using programming language
Enables data to be used in more ways
Safer than using direct access
Oracle databases support access from many languages
Might be necessary to perform a query with a supported language
User interface
Microsoft Access permits access to user interface
Optional user interface may be needed
Oracle offers MySQL Workbench as a graphical user interface
Allows ability to input queries without the query language
Menu-base interface
Forms-based interface
GUI displays schema in diagrammatic form
Specific query by manipulating diagram
GUIs utilize both menus and forms
GUIs using point device to pick sections of displayed schema diagram
Natural language interfaces accepts user requests and tries to interpret it
These interfaces have own schema like database conception schemas
Search engine example of entering and retrieving information using natural language
Query
Find specified data using SELECT statement
Query and reporting function included with software like Microsoft Access
Query Builder’s GUI is designed to enhance productivity and simplify query tasks
SQL or SQL displayed visually
Has pane displaying SQL text
Related tables determined by Query Builder that constructs join command
Query and update database using SELECT statement
Quickly view and edit query results
Examples:
Chartio Visual SQL
dbForge Query Builder for SQL Server
Active Query Builder
FlySpeed SQL
QueryDbVis Query Builder
Drag multiple tables, views, and columns to generate SQL statements
Database Management
Managing databases with SQL commands
Queries refer to request information from a database
Queries generate data of different formats according to function
Query commands perform the data retrieval and management in a database
SQL command Categories
DDL
SQL commands that define database schema
Create, modify, and delete database structures
Not set by general user
DML
SQL commands that manipulate data
DCL
SQL commands for rights, permissions, and other database system controls
Inputting and importing data
Data is input manually into a database through queries.
Another way is through importing data from different sources.
SQL Server Import Export Wizard
SQL Server Integrated Services (or SSIS)
OPENROWSET function
Extracting data from a database
Backing Up Databases
What is a database backup?
Two backup types:
Logical
Physical
Physical database backups
Needed to perform full database restoration
Minimal errors and loss
Full or incremental copies
Logical database backups
Copies of database information
Tables, schemas, procedures
Backup pros and cons
Physical backup
Logical backup
Pros:
Pros:
Simple and fast, despite format
Only selected data is backed up
Mirror copy loaded to another device
Saves time and storage
Cons:
Cons:
Used only to recreate system
No file system information
Cannot do full restore
Complications restoring process
Database backup methods
Full
Stores copies of all files
Preset schedule
Files are compressed but may need large storage capacity
Differential
Simplifies recovery
Requires last full backup
Last differential back up for full recovery
Incremental
Saves storage
Back up files generated or updated since last backup
Subsections of Introduction to Networking and Storage
Networking Fundamentals
Network Topologies, Types, and Connections
Types and Topologies
What is a computer network?
Computer networking refers to connected computing devices and an array of IoT devices that communicate with one another.
Network Types
There are multiple network types:
PAN (Personal Area Network)
LAN (Local Area Network)
MAN (Metropolitan Area Network)
WAN (Wide Area Network)
WLAN (Wireless LAN)
VPN (Virtual Private Network)
PAN (Personal Area Network)
A PAN enables communication between devices around a person. PANs can be wired or wireless.
USB
FireWire
Infrared
ZigBee
Bluetooth
LAN (Local Area Network)
A LAN is typically limited to a small, localized area, such as a single building or site.
MAN (Metropolitan Area Network)
A MAN is a network that spans an entire city, a campus, or a small region.
MANs are sometimes referred to as CANs (Campus Area Networks).
WAN (Wide Area Network)
A WAN is a network that extends over a large geographic area.
Businesses
Schools
Government entities
WLAN (Wireless LAN)
A WLAN links two or more devices using wireless communication.
Home
School
Campus
Office building
Computer Lab
Through a gateway device, a WLAN can also provide a connection to the wider Internet.
VPN (Virtual Private Network)
A private network connection across public networks.
Encrypt your Internet traffic.
Disguise your online identity
Safeguard your data.
Topology
Topology defines a network’s structure
A network’s topology type is chosen bases on the specific needs of the group installing that network
Physical Topology: It describes how network devices are physically connected.
Logical Topology: It describes how data flows across the physically connected network devices.
Star topology
Star topology networks feature a central computer that acts as a hub.
Ring topology
Ring topology networks connect all devices in a circular ring pattern, where data only flows in one direction (clockwise).
Bus topology
Bus topology networks connect all devices with a single cable or transmission line.
Small networks, LAN.
Tree topology
Tree topology networks combine the characteristics of bus topology and star topology.
University campus
Mesh topology
Mesh topology networks connect all devices on the network together.
This is called dynamic routing.
It is commonly used in WAN network for backup purposes.
It is not used in LAN implementations.
Wire Connections
Older Internet Connection Types
Newer Internet Connection Types
Wired Networks
Wired networking refers to the use of wire connections that allow users to communicate over a network.
Most computer networks still depend on cables or wires to connect devices and transfer data.
Wire Connections: Dial-Up
Requires a modem and phone line to access the internet.
Pros:
Widely available
Low cost
Easy Setup
Cons:
Very slow speeds
Can’t use phone and Internet at the same time
Wire Connections: DSL
Connects to the Internet using a modem and two copper wires within the phone lines to receive and transmit data.
Pros:
Faster than dial-up
Inexpensive
Dedicated connection (no bandwidth sharing)
Can provide Wi-Fi
Uses existing phone lines
Cons:
Slow speeds (less than 100 Mbps)
Not always available
Wired Connections: Cable
Cable delivers Internet via copper coaxial television cable.
Pros:
Lower cost than fiber
Fast speeds
Better than DSL
Long distances
Lower latency
Cons:
Bandwidth congestion
Slower uploads
Electromagnetic interference
Wired Connection: Fiber Optic
Transmit data by sending pulses of light across strands of glass (up to 200 Gbps).
Pros:
Efficient
Reliable
Covers long distances
Fast speeds
Streaming and hosting
Cons:
Expensive
Not available everywhere
Cables
Cables types
Hard Drive Cables
Hard drive cables connect a hard drive to a motherboard or controller card. May also be used to connect optical drives or older floppy drives.
SATA
Next-generation
Carries high-speed data
Connects to storage devices
IDE
Older tech
40-wire ribbon
Connect motherboard to one or two drives
SCSI
Supports variety of devices
Different cable types
Up to 16 connections
Network Cables
In wired networks, network cables connect devices and route information from one network device to another.
Cable need is determined by:
Network topology
Protocol
Size
Types:
Coaxial
TV signals to cable boxes
Internet to home modems
Inner copper wire surrounded by shielding
Highly Resistant to signal interference
Supports greater cable lengths between devices
10 Mbps capacity, uses DOCSIS standard
Fiber optic
Work over long distances without much interference
Handles heavy volumes of data traffic
Two Types
Single-Mode
Carries one light path
Sourced by a laser
Longer transmission distance
Multimode
Multiple light paths
Sourced by an LED
Ethernet
Consist of four pairs of twisted wires
Reduce interference
Wire a computer to LAN
Fast and Consistent
Two Types:
Unshielded Twisted Pair (UTP)
Cheaper and more common
Shielded Twisted Pair (STP)
More expensive
Designed to reduce interference
Serial Cables
A serial cable follows the RS-232 standard:
“Data bits must flow in a line, one after another, over the cable.”
Used in:
Modems
Keyboards
Mice
Peripheral devices
Video Cables
Transmits video signals.
VGA
Older, analog
DisplayPort
Connects interface to display
HDMI
High definition
Different connector types
Type A is common
DVI
Can be digital or integrated
Can be single or dual link
Mini-HDMI
Type C HDMI
Multipurpose Cables
Multipurpose cables connect devices and peripherals without a network connection. They transfer both data and power.
USB
Low speed 1.5 Mbps @3 meters
Full speed 12 Mbps @5 meters
Lighting
Apple only
Connects to USB ports
Thunderbolt
Apple only
Copper max length 3 meters
Optical max length 60 meters
20-40 Gbps throughput
Wireless Connections
Wireless network types
WPAN networking examples
WLAN networking examples
WMAN networking examples
WWAN networking examples
Wired vs. wireless
Latest Networking Trends
Advantages and Disadvantages of Network Types
Networks vs. devices
Smaller vs. larger
Wired vs. wireless
Network Types
Basic network types are:
Wired
Wireless
PAN
A PAN enables communication between devices around a person. PANs are wired and WPANs are wireless.
Advantages:
Flexible and mobile
One-time, easy setup
Portable
Disadvantages:
Limited range
Limited bandwidth
LAN
Advantages:
Reliable and versatile
Higher data transmission rates
Easier to manage
Disadvantages:
Smaller network coverage area
Number of device affects speed
Security risks
MAN
A MAN is optimized for a larger geographical area, ranging from several building blocks to entire cities.
Advantages:
Cover multiple areas
Easy to use, extend, and exchange
Managed by an ISP, government entity, or corporation
Disadvantages:
Requires special user permissions
Security risk
WAN
WANs and WWANs provide global coverage. Examples include the Internet and cellular networks.
Advantages:
Global coverage
More secure
Disadvantages:
Expensive
Difficult to maintain
Hardware, Network Flow, and Protocols
Networking Hardware Devices
Network Devices
Network devices, or networking hardware, enable communication and interaction on a computer network.
This includes:
Cables
Servers
Desktops
Laptops
Tablets
Smartphones
IoT devices
What is a server?
Other computers or devices on the same network can access the server
The devices that access the server are known as clients
A user can access a server file or application from anywhere
What are nodes and clients?
A node is a network-connected device that can send and receive information.
All devices that can send, receive, and create information on a network are nodes.
The nodes that access servers to get on the network are known as clients.
Client-server
Client-server networks are common in businesses.
They keep files up-to-date
Easy-to-find
One shared file in one location
Examples of services that use client-server networks:
FTP sites
Web servers
Web browsers
Peer-to-peer
Peer-to-peer networks are common in homes on the Internet.
Examples:
File sharing sites
Discussion forums
Media streaming
VoIP services
Hubs and Switches
A hub:
Connects multiple devices together
Broadcasts to all devices except sender
A switch:
Keeps a table of MAC addresses
Sends directly to correct address (More efficient than hubs)
Routers and modems
Routers interconnect different networks or subnetworks.
Manage traffic between networks by forwarding data packets
Allow multiple devices to use the same Internet connection
Routers use internal routing to direct packets effectively
The router:
Reads a packet’s header to determine its path
Consults the routing table
Forwards the packet
A modem converts data into a format that is easy to transmit across a network.
Data reaches its destination, and the modem converts it to its original form
Most common modems are cable and DSL modems
Bridges and gateways
A bridge joins two separate computer networks, so they can communicate with each other and work as a single network.
Wireless bridges can support:
Wi-Fi to Wi-F i
Wi-Fi to Ethernet
Bluetooth to Wi-Fi
A gateway is a hardware or software that allows data to flow from one network to another, for examples, a home network to the Internet.
Repeaters and WAPs
Repeaters
Receive a signal and retransmits it
Used to extend a wireless signal
Connect to wireless routers
Wireless Access Point (WAP)
Allows Wi-Fi devices to connect to a wired network
Usually connects to a wired router as a standalone device
Acts as a central wireless connection point for computers equipped with wireless network adapters
Network Interface Cards (NICs)
NICs connect individual devices to a network.
Firewalls, proxies, IDS, and IPS
A firewall monitors and controls incoming and outgoing network traffic based on predetermined security rules.
Firewalls can be software or hardware
Routers and operating systems have built-in firewalls
A Proxy Server:
Works to minimize security risks
Evaluates requests from clients and forwards them to the appropriate server
Hides an IP address
Saves bandwidth
IDS and IPS:
IDS monitors network traffic and reports malicious activity
IPS inspects network traffic and removes, detains, or redirects malicious items
Packets, IP Addressing, DNS, DHCP, and NAT
What is a packet?
Everything you do on the Internet involves packets.
Packets are also called:
Frames
Blocks
Cells
Segments
Data Transmission Flow Types
IP Packets Transmission Modes
Data Transmission Flow
When you send an email, it is broken down into individually labeled data packets and sent across the network.
IPv4 and IPv6
IPv4 is one of the core protocols for the Internet.
IPv6 is the newest version of Internet Protocol.
What is an IP address?
An IP address is used to logically identify each device (Host) on a given network.
IP Address Types
Static: Static IP addresses are manually assigned.
Dynamic: Dynamic IP addresses are automatically assigned.
Public: Public IP address is used to communicate publically.
Private: Private IP address is used to connect securely within an internal, private network.
Loopback: Loopback is the range of IP addresses reserved for the local host.
Reserved: Reserved IP addresses have been reserved by the IETF and IANA.
DNS
The DNS is the phone book of the internet.
Dynamic Host Configuration Protocol (DHCP)
The DHCP automates the configuring of IP network devices.
A DHCP server uses a pool of reserved IP addresses to automatically assign dynamic IP addresses or allocate a permanent IP address to a device.
Static allocation:
The server uses a manually assigned “permanent” IP address for a device.
Dynamic allocation:
The server chooses which IP address to assign a device each time it connects to the network.
Automatic allocation:
The server assigns a “permanent” IP addresses for a device automatically.
Subnetting (and Subnet Mask)
Subnetting is the process of taking a large, single network and splitting it up into many individual smaller subnetworks or subnets.
Identifies the boundary between the IP network and the IP host.
Internal usage within a network.
Routers use subnet masks to route data to the right place.
Automatic Private IP Addressing (APIPA)
APIPA is a feature in operating systems like Windows that let computers self-configure an IP address and subnet mask automatically when the DHCP server isn’t reachable.
Network Address Translation (NAT)
NAT is a process that maps multiple local private addresses to a public one before transferring the information.
Multiple devices using a single IP address
Home routers employ NAT
Conserves public IP addresses
Improves security
NAT instructions send all data packets without revealing private IP addresses of the intended destination.
Media Access Control (MAC) Addresses
A MAC address is the physical address of each device on a network.
Models, Standards, Protocols, and Ports
Networking Models
A networking model describes:
Architecture
Components
Design
Two types:
OSI Model: A conceptual framework used to describe the functions of a networking system.
TCP/IP Model: A set of standards that allow computers to communicate on a network. TCP/IP is based on the OSI model.
7 Layer OSI Model
5 Layer TCP/IP Model
The TCP/IP model is a set of standards that allow computers to communicate on a network. TCP/IP is based on the OSI model.
Network Standards and their Importance
Networking standards define the rules for data communications that are needed for interoperability of networking technologies and processes.
There are two types of network standards:
De-jure or Formal Standards: Developed by an official industry or government body.
Examples: HTTP, HTML, IP, Ethernet 802.3d
De-Facto Standards: De-facto standards result from marketplace domination or practice.
Examples: Microsoft Windows, QWERTY keyboard
Noted Network Standards Organizations
Standards are usually created by government or non-profit organizations for the betterment of an entire industry.
ISO: Established the well known OSI reference networking model.
DARPA: Established the TCP/IP protocol suit.
W3C: Established the World Wide Web (WWW) standard.
ITU: Standardized international telecom, set standards for fair use of radio frequency.
IEEE: Established the IEEE 802 standards.
IETF: Maintains TCP/IP protocol suites. IETF also developed RFC standard.
Protocols
A network protocol is a set of rules that determines how data is transmitted between different devices in the same network.
Network Management:
- Connection
- Link Aggregation
- Troubleshooting
Protocols – TCP vs. UDP
TCP
UDP
Slower but more reliable
Faster but not guaranteed
Typical applications
Typical application
1) File transfer protocol
1) Online games
2) Web browsing
2) Calls over the internet
3) EMAIL
Protocols – TCP/IP
The TCP/IP suite is a collection of protocols.
Protocols – Internet of Things
Protocols – Crypto Classic
The Crypto Classic protocol is designed to serve as one of the most efficient, effective, and secure payment methods built on the blockchain network.
Bitcoin Protocol: A peer-to-peer network operating on a cryptographic protocol used for bitcoin transactions and transfers on the Internet.
Blockchain Protocol: An open, distributed ledger that can record transactions between two parties efficiently and in a verifiable and permanent way.
Commonly Used Ports
Ports are the first and last stop for information sent across a network.
A port is a communication endpoint.
A port always has an associated protocol and application.
The protocol is the path that leads to the application’s port.
A network device can have up to 65536 ports.
Port numbers do not change.
Wireless Networks and Standards
Network types
WPAN
A WPAN connects devices within the range of an individual person (10 meters). WPANs use signals like infrared, Zigbee, Bluetooth, and ultra-wideband.
WLAN
A WLAN connects computers and devices within homes, offices, or small businesses. WLANs use Wi-Fi signals from routers, modems, and wireless access points to wirelessly connect devices.
WMAN
A WMAN spans a geographic area (size of a city). It serves ranges greater than 100 meters.
WWAN
A WWAN provides regional, nationwide, and global wireless coverage. This includes private networks of multinational corporations, the Internet, and cellular networks like 4G, 5G, LTE, and LoRaWAN.
Wireless ad hoc network
A WANET uses Wi-Fi signals from whatever infrastructure happens to be available to connect devices instantly, anywhere. WANETs are similar in size to WLANs, but use technology that is closer to WWANs and cellular network.
Advantages:
Flexible
No required infrastructure
Can be set up anywhere instantly
Disadvantages:
Limited bandwidth quality
Not robust
Security risks
Cellular networks
A cellular network provides regional, nationwide, and global mesh coverage for mobile devices.
Advantages
Flexibility
Access
Speed and efficiency
Disadvantages
Expensive
Decreased coverage
Hardware limitations
IEEE 802.20 and IEEE 802.22
The IEEE 802.20 and 802.22 standards support WWANs, cellular networks and WANETs.
IEEE 802.20
Optimizes bandwidth to increase coverage or mobility
Used to fill the gap between cellular and other wireless networks
IEEE 802.22
Uses empty spaces in the TV frequency spectrum to bring broadband to low-population, hard-to-reach areas
Protocol Table
Web page protocols
File transfer protocols
Remote access protocols
Email protocols
Network Protocols
Configuring and Troubleshooting Networks
Configuring a Wired SOHO Network
What is a SOHO Network?
A SOHO (small office, home office) network is a LAN with less than 10 computers that serves a small physical space with a few employees or home users.
It can be a wired Ethernet LAN or a LAN made of both wired and wireless devices.
A typical wired SOHO network includes:
Router with a firewall
Switch with 4-8 Ethernet LAN ports
Printer
Desktops and /or laptops
Setup steps – plan ahead
When setting up a SOHO network, knowing the compatibility requirements is very important.
Before setting up any SOHO network, review and confirm everything in your plan to ensure a successful installation.
Setup steps – gather hardware
SOHO networks need a switch to act as the hub of the network
If Internet is desired, a router can be added or used instead
Setup steps – connect hardware
Setup steps – router settings
Log in to router settings
Enter ‘ipconfig’ in a command prompt window to find your router’s public IP address (listed next to default gateway)
Enter it into a browser and log in
Update username and password
All routers have default administrator usernames and passwords
To improve security, change the default username password
Update firmware
Updating router firmware solves problems and enhances security
Check the manufacturer website for available firmware updates
Download and install if your firmware is not up-to-date
Setup steps – additional settings
SOHO wired network security depends on a firewall
Most routers have a built-in firewall, additional software can be installed on individual machines
Servers and hardware have built-in DHCP and NAT actions
DHCP servers use IP addresses to provide network hosts
NAT maps public IPv4 address to private IP addresses
Setup steps – user accounts
User account setup is included in most operating systems.
Setup steps – test connectivity
Network performance depends on Internet strength, cable specification, installation quality, connected devices, and network and software settings.
Test and troubleshoot to ensure proper network performance.
To troubleshoot performance:
Run security tools
Check for updates
Restart devices
Run diagnostic
Reboot the router or modem
Configuring a (wireless) SOHO network
What is a SOHO wireless network?
A SOHO wireless network is a WLAN that serves a small physical space with a few home users.
A SOHO wireless network can be configured with the help of a central WAP, which can cover a range of wireless devices within a small office or home.
Common broadband types
Common broadband types that enable network connection:
DHCP:
The most common broadband type, used in cable modem connections.
PPPoE:
Used in DSL connections in areas that don’t have newer options.
Static IP:
More common in business.
DHCP is the easiest broadband type to use. Internet Service Providers can provide other options if needed.
Wireless security factors
Wireless networks can be setup to be either open (unencrypted) or encrypted.
Get to know your wireless router
Connect to router admin interface
To manage router settings, you must find its default IP address, paste it into a browser and hit enter.
Assign a SSID
SSID is the name of a wireless network.
This name is chosen during setup.
Unique names help to identify the network.
Each country determines band and available modes.
2.4 GHz and 5 GHz have specific supported modes.
Every router has as a default option.
Wireless encryption security modes
Going wireless
Once the router is configured, your wireless network is ready.
Users will see it among the available wireless networks when they click the Wi-Fi icon.
Test and troubleshoot connectivity
Test network performance and Internet connectivity on each wireless device in the vicinity of the WAP.
If required, troubleshoot performance issues (network lags, glitches, or network cannot be accessed) with the following actions:
Check router configuration settings.
Run security tools.
Check for updates.
Restart devices.
Run diagnostics.
Reboot the router or modem.
Check equipment for damage.
Mobile configuration
IMEI vs. IMSI
IMEI and IMSI are used to identify cellular devices and network users when troubleshooting device and account issues.
Internation Mobile Equipment Identity (IMEI)
ID# for phones on GSM, UMTS, LTE, and iDEN networks
Can be used to block stolen phones
International Mobile Subscriber Identity (IMSI)
ID# for cell network subscribers
Stored in a network sim card
Troubleshooting Network Connectivity
Symptoms of connectivity problems
“Can’t connect” or “slow connection” are two of the most common network problems. These symptoms can be caused by several things.
Causes of Connectivity Problems
Common causes of network connectivity problems:
Cable Damage
Cable damage slows or stops network connections. The damage can be obvious or hidden from view.
Ways to solve:
Check for physical damage
Test the cable using different devices or a specialized tool
Replace the cable
Equipment malfunction
An equipment malfunction can slow or stop network connections.
Ways to solve:
Check network adapter drivers in Device Manager
Check switch or router port settings in the management software
Replace the equipment
Out of range
When a user is too far away from a wireless signal, their connection will lag or fail.
Ways to solve:
Move physically closer to the source of the wireless connection
Move the wireless connection source closer to the affected user(s)
Use stronger devices to boost the signal strength
Use more devices to ensure the Wi-Fi reaches users who are farther away
Missing SSID
Network connections can fail when a user can’t find the network name (SSID) in the available networks list.
Ways to solve:
Move physically closer to the Wi-Fi source
Reconfigure the network to ensure the SSID is not hidden
Upgrade devices or use compatibility mode on newer network, so older devices can still connect
Compatibility mode can slow a network
Reserve 2.4 GHz band for legacy devices
Interference
Interference is when a radio or microwave signal slows or breaks a wireless connection.
Ways to solve:
Remove the source of the interference signal
Use a different Wi-Fi frequency (wireless)
Use shielded cables to connect (wired)
Remodel the building with signal-blocking materials
Weak signal strength
When signal strength is weak, a wireless adapter might slow speeds down to make the connection more reliable.
Weak signals cause:
Lags
Dropped connection
Back-and-forth network hopping
Out of range
Interference
Physical obstacles
Ways to solve:
Move closer to signal
Adjust Wi-Fi frequency
Realign router antennae
Wireless access points should be placed up high and in the middle of the space.
DNS and software configuration
Network connections can fail when DNS or software is configured incorrectly.
DNS issue:
Domain not recognized
IP addresses recognized
OS and apps issue:
Software affecting connection
Ways to solve:
For DNS servers, test domains using ipconfig in a command prompt
For apps and OSes, use the network troubleshooter in Windows Settings
Malware
Malware slows or stops network connections intentionally, or as a result of overloading a system with other tasks.
Ways to solve:
Use antimalware tools
Adjust firewall settings
Configure Privacy settings
Windows
Browser
Email
Network Troubleshooting with Command Line Utilities
Common command line utility commands that you would use to troubleshoot or diagnose network issues:
ipconfig
IP address
Subnet mask
Default gateway
ping
You can ping:
IP addresses, or
Domains
nslookup
It lists:
Your DNS server
Your DNS server’s IP address
Domain name
tracert
Tracert lists:
Sent from
Sent to
Number of transfers
Transfer locations
Duration
netstat: It shows if a server’s email and ports are open and connecting to other devices.
Netstat lists:
Protocol
Local address
Foreign address
Current state
Storage Types and Network Sharing
Types of Local Storage Devices
Hard Drive (HD or HDD)
HDDs:
Large storage capacity
Up to 200 MB/s
Can overheat
Were the standard PC storage for decades
Solid-state Drive (SSD)
No moving parts
Do not need power to retain data
faster than any HDD
Solid-state Hybrid Drive (SSHD)
SSHDs integrate the speed of an SSD and the capacity of an HDD into a single device. It decides what to store in SSD vs. HDD based on user activity.
SSHDs are:
Faster than HDDs
Perform better than HDDs
Cost less than SSDs
Higher capacities than SSDs
Optical Disk Drive (ODD)
ODDs are also called:
CD Drives
DVD Drives
BD Drives
Disc Drives
Optical Drives
Flash Drive
Flash drives store data on solid-state drives (SSDs). Less energy is needed to run flash drives, as they don’t have moving parts that require cooling. High-end versions deduplicate and compress data to save space.
Local Storage wit Multiple Drives
Hybrid disk arrays physically combine multiple SSD and HDD devices into an array of drives working together to achieve the fast and easy performance of solid-state and the lower costs and higher capacities of hard-disk.
Direct Attached Storage (DAS)
DAS is one or more storage units within an external enclosure that is directly attached to the computer accessing it.
Ephemeral and Persistent storage
In DAS units and other storage devices, you can configure storage settings to be Ephemeral or Persistent.
Redundant Array of Independent Disks (RAID)
A RAID spread data across multiple storage drives working in parallel.
Companies choose RAID devices for their durability and performance.
Maintain RAID devices
Keep spare drives
Perform routine backups
Troubleshooting Storage Issues
Disk Failure symptoms
Disk failure can be caused by wear and tear over time, faulty manufacturing, or power loss.
Read/write failure
Blue screen of Death (BSoD)
Bad sectors
Disk thrashing
Clicking and grinding noises
Chkdsk and SMART
The chkdsk tools and the SMART program are used to monitor and troubleshoot disk health.
SMART: Self-Monitoring Analysis, and Reporting Technology
wmic/node: localhost diskdrive get status
Check disk tools
chkdsk /r locates bad sectors
chkdsk /f attempts to fix file system errors
Boot failures
When a computer fails to boot:
Computer power up
Lights and sound
Plugged in
Drive configuration
Correct firmware boot sequence
No removable disks
Cables connected and undamaged
Motherboard port enables
Filesystem error
Boot into recovery and enter C: in command prompt.
If invalid media type, reformat disk with bootrec tool (erases all data).
If invalid drive specification, partition structure with diskparttool.
Boot block repair
Errors like “Invalid drive specification” or “OSS not found” indicate boot errors (caused by disk corruption, incorrect OS installation, or viruses).
Try antivirus boot disk and recovery options
Original product disk > Repair
Startup repair
Command prompt
Fix MBR: bootrec /fixmbr
Fix boot sector: bbotrec /fixboot
Correct missing installation in BCD: bootrec /rebuild bcd
File recovery options
For computers that won’t boot, you can try to recover files by removing the hard drive and connecting it to another computer.
Recovery options:
Windows disk management
chkdsk
Third-Party file recovery
Disk Performance issues
Disk performance can slow if a disk is older, too full, or its files are not optimized.
To improve performance:
Defragment the drive
Add RAM
Upgrade to a solid state or hybrid drive
Remove files and applications
Add additional drive space
Troubleshooting optical drives
Optical drives are laser-based and don’t physically touch disks.
Cleaning kits solve read/write errors
CD-ROM drives cannot play DVDs and Blu-rays
DVD and Blu-ray drives have third-party support
Writable discs have recommended write speeds
Buffer underrun
When the OS is too slow for the optical drive’s write process, errors occur.
To fix buffer underrun:
Use latest writes
Burn at lower speeds
Close apps during burn
Save to hard drive instead
Troubleshooting RAID issues
Here are some common RAID troubleshooting steps:
Types of Hosted Storage and Sharing
Storage as a Service (STaaS)
STaaS is when companies sell network storage space to customers, so they don’t have to buy and maintain their own network equipment.
Dropbox
OneDrive
Google Drive
box
Amazon Drive
Email and social media storage
Email
Companies store your data, emails, and attachments in their data centers.
Social Media
Companies store your photos, videos, and messages in their data centers.
Gmail waits 30 days before permanent removal.
Facebook deleted after 90 days, but keeps certain user data indefinitely.
Workgroup and homegroup
A workgroup or homegroup is a group of computers on a SOHO network, typically without a server.
To share files and folders, users set them to ‘public’
Data is stored on the user device that created it.
The added points of failure create higher risk of data loss.
Newer cloud solutions provide the same features more securely.
Workgroups and homegroups are less common. Homegroups have been removed from Windows 10 altogether.
Repositories
A repository is a network location that lets a user store, manage, track, collaborate on, and control changes to their code.
Repositories save every draft. Users can roll things back if problems occur. This can save software developers months of time.
GitHub
DockerHub
Active Directory Domain Service (AD DS)
AD is a Microsoft technology that manages domain elements such as users and computers.
Organizes domain structure.
Grants network access.
Connects to external domains.
It can be managed remotely from multiple locations.
Active Directory Domain Services:
Stores centralized data, manages communication and search.
Authenticates users so they can access encrypted content.
Manages single-sign on (SSO) user authentication.
Limits content access via encryption.
Network drives
Network drives are installed on a network and shared with selected users. They offer the same data storage and services as a standard disk drive.
Network drives can be located anywhere.
Network drives appear alongside local drive.
Network drives can be installed on computers, servers, NAS units, or portable drives.
Network file and print sharing
File and Printer Sharing is part of the Microsoft Networks services.
Appear alongside local drives
Accessed via a web browser
Appears in the printer options
Network Storage Types
Network storage is digital storage that all users on a network can access.
Small networks might rely on a single device for the storage needs of 1–5 people.
Large networks (like the Internet) must rely on hundreds of datacenters full of servers.
Storage Area Network (SAN)
A SAN combines servers, storage systems, switches, software, and services to provide secure, robust data transfers.
Better application performance.
Central and consolidated.
Offsite (data protected and ready for recovery)
Simple, centralized management of connections and settings.
Network Attached Storage (NAS)
A NAS device is a local file server. It acts as a hard drive for all devices on a local network.
Convenient sharing across network devices.
Better performance through RAID configuration.
Remote Access
Work when the Internet is down.
Difference between NAS and SAN
Cloud-based Storage Devices
Cloud storage
Cloud storage is when files and applications are stored and engaged with via the Internet.
Cloud companies manage data centers around the world to keep applications functioning properly, and user data stored securely.
Public Cloud:
Provide offsite storage for Internet users.
Private Cloud:
Provides collaboration and access to private network users.
Hybrid Cloud:
A mix of both. Provides public sharing and restricted private areas via cloud storage and cloud-hosted apps.
File, Block, and Object storage
Cloud companies use multiple data storage types depending on how often they need to access different data and the volume of that data.
File Storage
File storage saves all data in a single file and is organized by a hierarchical path of folders and subfolders. File storage uses app extensions like .jpg or .doc or .mp3.
Familiar and easy for most users
User-level customization
Expensive
Hard to manage at larger scale
Block Storage
Block Storage splits data into fixed blocks and stores them with unique identifiers. Blocks can be stored in different environments (like one block on Windows, and the rest in Linux). When a block is retrieved, it’s reassembled with associated blocks to recreate the original data.
Default storage for data that is frequently updated.
Fast, reliable, easy to manage.
No metadata, not searchable, expensive.
Used in databases and email servers.
Object Storage
Object Storage divides data into self-contained units stored at the same level. There are no subdirectories like in file storage.
Users metadata for fast searching.
Each object has a unique number.
Requires an API to access and manage objects.
Good for large amounts of unstructured data.
Important for AI, machine learning, and big data analytics.
Storage gateways
A storage gateway is a service that connect on-premises devices with cloud storage.
Definition and Essential Characteristics of Cloud Computing
Cloud computing (NIST)
A model for enabling convenient, on-demand network access to a shared pool of configurable computing resources with minimal management effort or service provider interaction.
Examples of computing resources include:
Networks
Servers
Applications
Services
Cloud model
5 Essential characteristics
3 Deployment models
3 Service models
5 Essential characteristics
Cloud Computing as a Service
3 Types of cloud deployment models
Public
Hybrid
Private
3 Service models
Three layers in a computing stack:
Infrastructure (IaaS)
Platform (PaaS)
Application (SaaS)
History and Evolution of Cloud Computing
In the 1950s:
Large-scale mainframes with high-volume processing power.
The practice of time-sharing, or resource pooling, evolved.
Multiple users were able to access the same data storage layer and CPU power.
In the 1970s:
Virtual Machine (VM)
Mainframes to have multiple virtual systems, or virtual machines, on a single physical node
Cloud: Switch from CapEx to OpEx
Key Considerations for Cloud Computing
Key Drivers for moving to cloud
Infrastructure and Workloads
The cost of building and operating data centers can become astronomical.
Low initial costs and pay-as-you-go attributes of cloud computing can add up to significant cost savings.
SaaS and development platforms
Organizations need to consider if paying for application access is a more viable option than purchasing off-the-shelf software and subsequently investing in upgrades
Speed and Productivity
Organizations also need to consider what it means to them to get a new application up and running in ‘x’ hours on the cloud versus a couple of weeks, even months on traditional platforms.
Also, the person-hour cost efficiencies increases from using cloud dashboards, real-time statistics, and active analytics.
Risk Exposure
Organizations need to consider the impact of making a wrong decision – their risk exposure.
Is it safer for an organization to work on a 12-month plan to build, write, test, and release the code if they’re certain about adoption?
And is it better for them to “try” something new paying-as-you-go rather than making long-term decisions based on little or no trial or adoption?
Benefits of cloud adoption
Flexibility
Efficiency
Strategic Value
Challenges of cloud adoption
Data security, associated with loss or unavailability of data causing business disruption
Governance and sovereignty issues
Legal, regulatory, and compliance issues
Lack of standardization in how the constantly evolving technologies integrate and interoperate
Choosing the right deployment and service models to serve specific needs
Partnering with the right cloud service providers
Concerns related to business continuity and disaster recovery
Key Cloud Service Providers and Their Services
Future of Cloud Computing
Cloud Service Providers
Alibaba Cloud
Amazon Web Services
Google Cloud Platform
IBM Cloud
Microsoft Azure
Oracle Cloud
Salesforce
SAP
Business Case for Cloud Computing
Cloud Adoption – No longer a choice
It is no longer a thing of the future
Single individual to Global multi-billion dollar enterprise, anybody can access the computing capacity they need on the cloud.
Cloud makes it possible for businesses to:
Experiment
Fail
Learn
Faster than ever before with low risk.
Businesses today have greater freedom to change course than to live with the consequences of expensive decisions taken in the past.
To remain, competitive, businesses need to be able to respond quickly to marketplace changes.
Product lifecycles have shortened, and barriers to entry have become lower.
The power, scalability, flexibility, and pay-as-you-go economics of cloud has made it underpinning foundation for digital transformation.
Emerging Technologies Accelerated by Cloud
Internet of Things in the Cloud
Artificial Intelligence on the Cloud
AI, IoT, and the Cloud
BlockChain and Analytics in the Cloud
Blockchain & Cloud
A 3-Way Relationship
Analytics on the Cloud
How can analytics technology leverage the cloud?
Track trends on social media to predict future events
Analyze data to build machine learning models in cognitive applications
Data analytics and predictions maintenance solutions for city infrastructure
Cloud Computing Models
Overview of Cloud Service Models
IaaS
PaaS
SaaS
IaaS – Infrastructure as a Service
It is a form of cloud computing that delivers fundamentals:
compute
network
storage
to consumers on-demand, over the internet, on a pay-as-you-go basis.
The cloud provider hosts the infrastructure components traditionally present in an on-premises data center, as well as the virtualization or hypervisor layer.
IaaS Cloud
The ability to track and monitor the performance and usage of their cloud services and manage disaster recovery.
End users don’t interact directly with the physical infrastructure, but experience it as a service provided to them.
Comes with supporting services like auto-scaling and load balancing that provide scalability and high performance.
Object storage is the most common mode of storage in the cloud, given that it is highly distributed and resilient.
IaaS use cases
Test and Development
Enable their teams to set up test and development environments faster.
Helping developers focus more on business logic than infrastructure management.
Business Continuity and Disaster Recovery
Require a significant amount of technology and staff investment.
Make applications and data accessible as usual during a disaster or outage.
Faster Deployments and Scaling
To deploy their web applications faster.
Scale infrastructure up and down as demand fluctuates.
High Performance Computing
To solve complex problems involving millions of variables and calculations
Big Data Analysis
Patterns, trends, and associations requires a huge amount of processing power.
Provides the required high-performance computing, but also makes it economically viable.
IaaS Concerns
Lack of transparency
Dependency on a third party
PaaS – Platform as a Service
PaaS
A cloud computing model that provides a complete application platform to:
Develop
Deploy
Run
Manage
PaaS Providers Host and Manages
Installation, configuration, operation of application infrastructure:
Servers
Networks
Storage
Operating system
Application runtimes
APIs
Middleware
Databases
User manages: Application Code
Essential Characteristics of PaaS
High level of abstraction
Eliminate complexity of deploying applications
Support services and APIs
Simplify the job of developers
Run-time environments
Executes code according to application owner and cloud provider policies
Rapid deployment mechanisms
Deploy, run, and scale applications efficiently
Middleware capabilities
Support a range of application infrastructure capabilities
Use Cases of PaaS
API development and management
Internet of Things (IoT)
Business analytics/intelligence
Business Process Management (BPM)
Master data management (MDM)
Advantages of PaaS
Scalability
Faster time to market
Greater agility and innovation
PaaS available offerings
Risks of PaaS
Information security threats
Dependency on service provider’s infrastructure
Customer lack control over changes in strategy, service offerings, or tools
SaaS – Software as a Service
A cloud offering that provides access to a service provider’s cloud-based software.
Provider maintains:
Servers
Databases
Application Code
Security
Providers manages application:
Security
Availability
Performance
SaaS Supports
Email and Collaboration
Customer Relationship Management
Human Resource Management
Financial Management
Key Characteristics
Multi-tenant architecture
Manage Privileges and Monitor Data
Security, Compliance, Maintenance
Customize Applications
Subscription Model
Scalable Resources
Key Benefits
Greatly reduce the time from decision to value
Increase workforce productivity and efficiency
Users can access core business apps from anywhere
Buy and deploy apps in minutes
Spread out software costs over time
Use Cases for SaaS
Organizations are moving to SaaS to:
Reduce on-premise IT infrastructure and capital expenditure
Avoid ongoing upgrades, maintenance, and patching
Run applications with minimal input
Manage websites, marketing, sales, and operations
Gain resilience and business continuity of the cloud provider
Trending towards SaaS integration platforms.
SaaS Concerns
Data ownership and data safety
Third-party maintains business-critical data
Needs good internet connection
Deployment Models
Public Cloud
Public Cloud providers in the market today
Public cloud characteristics
Public cloud benefits
Public cloud concerns
Public cloud use cases
Building and testing applications, and reducing time-to-market for their products and services.
Businesses with fluctuating capacity and resourcing needs.
Build secondary infrastructures for disaster recovery, data protection, and business continuity.
Cloud storage and data management services for greater accessibility, easy distribution, and backing up their data.
IT departments are outsourcing the management of less critical and standardized business platforms and applications to public cloud providers.
Private Cloud
“Cloud infrastructure provisioned for exclusive use by a single organization comprising multiple consumers, such as the business units within the organization. It may be owned, managed, and operated by the organization, a third party, or some combination of them, and it may exist on or off premises.”
Internal or External
Virtual Private Cloud (VPC)
An external cloud that offers a private, secure, computing environment in a shared public cloud.
Best of Both Worlds
Benefits of Private Clouds
Common Use Cases
Hybrid Cloud
Connects an organization on-premise private cloud and third-party public cloud.
It gives them:
Flexibility
Workloads move freely
Choice of security and regulation features
With proper integration and orchestration between the public and private clouds, you can leverage both clouds for the same workload. For example, you can leverage additional public cloud capacity to accommodate a spike in demand for a private cloud application also known as “cloud bursting”.
The Three Tenets
Types of Hybrid Clouds
Benefits
Security and compliance
Scalability and resilience
Resource optimization
Cost-saving
A hybrid cloud lets organizations deploy highly regulated or sensitive workloads in a private cloud while running the less-sensitive workloads on a public cloud.
Using a hybrid cloud, you can scale up quickly, inexpensively, and even automatically using the public cloud infrastructure, all without impacting the other workloads running on your private cloud.
Because you’re not locked-in with a specific vendor and also don’t have to make either-or- decisions between the different cloud models, you can make the most cost-efficient use of your infrastructure budget. You can maintain workloads where they are most efficient, spin-up environments using pay-as-you-go in the public cloud, and rapidly adopt new tools as you need them.
Hybrid Cloud Use Cases
SaaS integration
Data and AI integration
Enhancing legacy apps
VMware migration
Components of Cloud Computing
Overview of Cloud Infrastructure
After choosing the cloud service model and the cloud type offered by vendors, customers need to plan the infrastructure architecture. The infrastructure layer is the foundation of the cloud.
Region
It is a geographic area or location where a cloud provider’s infrastructure is clustered, and may have names like NA South or US East.
Availability Zones
Multiple Availability Zones (AZ)
Have their own power, cooling, networking resources
Isolation of zones improves the cloud’s fault tolerance, decrease latency, and more
very high bandwidth connectivity with other AZs, Data Centers and the internet
Computing Resources
Cloud providers offer several compute options:
Virtual Servers (VMs)
Bare Metal Servers
Serverless (Abstraction)
Storage
Virtual servers come with their default local storage, but the stored documents are lost as we destroy the servers. Other more persistent options are:
Traditional Data Centers:
Block Storage
File Storage
Often struggle with scale, performance and distributed characteristics of cloud.
The most common mode of storage
Object Storage
It is highly distributed and resilient
Networking
Networking infrastructure in a cloud datacenter include traditional networking hardware like:
routers
switches
For users of the Cloud, the Cloud providers have Software Defined Networking (SDN), which allows for easier networking:
provisioning
configuration
management
Networking interfaces in the cloud need:
IP address
Subnets
It is even more important to configure which network traffic and users can access your resources:
Security Groups
ACLs
VLANs
VPCs
VPNs
Some traditional hardware appliances:
firewalls
load balancers
gateways
traffic analyzers
Another networking capability provided by the Cloud Providers is:
CDNs
Types of Virtual Machines
Shared or Public Cloud VMs
Transient or Spot VMs
The Cloud provider can choose to de-provision them at any time and reclaim the resources
These VMs are great for:
Non-production
Testing and developing applications
Running stateless workloads, testing scalability
Running big data and HPC workloads at a low cost
Reserved virtual server instances
Reserve capacity and guarantee resources for future deployments
If you exceed your reserved capacity, complement it with hourly or monthly VMs
Note: Not all predefined VMs families or configuration may be available as reserved.
Dedicated Hosts
Single tenant isolation
Specify the data center and pod
This allows for maximum control over workload placement
Used for meeting compliance and regulatory requirements or licensing terms
Bare Metal Servers
A bare metal server is a single-tenant, dedicated physical server. In other words, it’s dedicated to a single customer.
Cloud Provider manages the server up to the OS.
The Customer is responsible for administering and managing everything else on the server.
Bare Metal Server Configuration
Preconfigured by the cloud provider
Custom-configured as per customer specifications
Processors
RAM
Hard drives
Specialized components
The OS
Add GPUs:
Accelerating scientific computation
Data analytics
Rendering professional grade virtualized graphics
Characteristics
Can take longer to provision
Minutes to hours
More expensive than VMs
Only offered by some cloud providers
Workloads
Fully customizable/ demanding environments
Dedicated or long-term usage
High Performance Computing
Highly secure / isolated environments
Bare-metal server vs. Virtual Servers
Bare Metal
Virtual Servers
Work best for: CPU and I/O intensive workloads
Rapidly provisioned
Excel with the highest performance and security
Satisfy strict compliance requirements
Provide an elastic and scalable environment
Offer complete flexibility, control, and transparency
Come with added management and operational over head
Low cost to use
Secure Networking in Cloud
Networking in Cloud vs. On Premise
To create a network in cloud:
Define the size of the Network using IP address range, e.g.,: 10.10.0.0/16
Direct Connectivity
Building a Cloud
It entails creating a set of logical constructs that deliver networking functionality akin to data center networks for securing environments and ensuring high performing business applications.
Containers
Containers are an executable unit of software in which application code is packaged, along with its libraries and dependencies, in common ways so that it can be run anywhere—desktops, traditional IT, or the cloud. Containers are lighter weight and consume fewer resources than Virtual Machines.
Containers streamline development and deployment of cloud native applications
Fast
Portable
Secure
Cloud Storage and Content Delivery Networks
Basics of Storage on the Cloud
Direct Attached/Local Storage
Within the same server or rack
Fast
Use for OS
Not suitable
Ephemeral (Temporary)
Not shared
Non-resilient
File Storage
Disadvantages
Slower
Advantages
Low cost
Attach to multiple servers
Block Storage
Advantages
Faster read/write speeds
Object Storage
Disadvantages
Slowest speed
Advantages
Least expensive
Infinite in size
Pay for what you use
File Storage
Like Direct attached:
Attached to a compute node to store data
Unlike Direct attached:
Less expensive
More resilient to failure
Less disk management and maintenance for user
Provision much larger amounts of Storage
File storage is mounted from remote storage appliances:
Resilient to failure
Offer Encryption
Managed by service provider
File storage is mounted on compute nodes via Ethernet networks:
Multiple Compute Nodes
File storage can be mounted onto more than one compute node
Common Workloads:
Departmental file share
‘Landing zone’ for incoming files
Repository of files
i.e., speed variance is not an issue
Low cost database storage
IOPS
Input/Output Operations Per Second – the speed at which disks can write and read data.
Higher IOPS value = faster speed of underlying disk
Higher IOPS = higher costs
Low IOPS value can become a bottleneck
Block Storage
What is Block Storage?
Block storage breaks files into chunks (or block) of data.
Stores each block separately under a unique address.
Must be attached to a compute node before it can be utilized.
Advantages:
Mounted from remote storage appliances
Extremely resilient to failure
Data is more secure
Mounted as a volume to compute nodes using a dedicated network of optical fibers:
Signals move at the speed of light
Higher price-point
Perfect for workloads that need low-latency
Consistent high speed
Databases and mail servers
Not suitable for shared storage between multiple servers
IOPS
For block storage, as it is for file storage, you need to take the IOPS capacity of the storage into account:
Specify IOPS characteristics
Adjust the IOPS as needed
Depending on requirements and usage behavior
Common Attributes of File and Block Storage
Block and File Storage is taken from appliances which are maintained by the service provider
Both are highly available and resilient
Often include data encryption at rest and in transit
Differences: File Storage vs. Block Storage
File Storage
Block Storage
Attached via Ethernet network
Attached via high-speed fiber network
Speeds vary, based on load
Only attach to one node at a time
Can attach to multiple computer nodes at once
Good for file share where:
1) Fast connectivity isn’t required
Good for applications that need:
2) Cost is a factor
1) Consistent fast access to disk
Remember: Consider workload IOPS requirements for both storage types.
Object Storage
Object storage can be used without connecting to a particular compute node to use it:
Object storage is less expensive than other cloud storage options
The most important thing to note about Object Storage is that it’s effectively infinite
- With Object Storage, you just consume the storage you need and pay per gigabyte cost for what you use.
When to use Object Storage:
Good for large amounts of unstructured data
Data is not stored in any kind of hierarchical folder or directory structure
Object Storage Buckets
Managed by Service Provider
Object Storage – Resilience Options
Object Storage – Use Cases
Any Data which is static and where fast read and write speeds are not necessary
Text files
Audio files
Video files
IoT Data
VM images
Backup files
Data Archives
Not suitable for operating systems, databases, changing content.
Object Storage – Tiers and APIs
Object Storage Tiers
Standard Tier
Store objects that are frequently accessed
Highest per gigabyte cost
Vault/Archive Tier
Store objects that are accessed once or twice a month
Low storage cost
Cold Vault Tier
Store data that is typically accessed once or twice a year
Costs just a fraction of a US cent per/GB/month
Automatic archiving rules
Automatic archiving rules for your data
Automatically be moved to a cheaper storage tier if object isn’t accessed for long
Object Storage – Speed
Doesn’t come with IOPS options
Slower than file or block storage
Data in ‘cold vault’ buckets, can take hours for retrieval
Object storage not suitable for fast access to files.
Object Storage – Costs
Object Storage is priced per/GB
Other costs related to retrieval of the data
e.g., Higher access costs for cold vault tiers
Ensure data is stored in correct tier based on frequency of access.
Application Programming Interface, or API
Object Storage – Backup solutions
Effective solution for Backup and Disaster Recovery
Replacement for offsite backups
Many backup solutions come with built-in options for Object Storage on Cloud
More efficient than tape backups for geographic redundancy
CDN – Content Delivery Network
Accelerates content delivery to users of the websites, by caching the content in data centers near their locations.
Makes websites faster.
Reduction in load on servers
Increase uptime
Security through obscurity
Hybrid Multi-Cloud, Microservices, and Serverless
Hybrid Multi-cloud
A computing environment that connects an organization’s on-premise private cloud and third-party public cloud into a single infrastructure for running the organization’s applications.
Hybrid Multicloud use cases
Cloud scaling
Composite cloud
Modernization
Data and AI
Prevent lock-in to a particular cloud vendor and having a flexibility to move to a new provider of choice
Microservices
Microservices architecture:
Single application
coupled and independently deployable smaller components or services
These services typically have their own stack running on their own containers.
They communicate with one another over a combination of:
APIs
Even streaming
Message brokers
What this means for businesses is:
Multiple developers working independently
Different stacks and runtime environments
Independent scaling
Serverless Computing
Offloads responsibility for common infrastructure management tasks such as:
Scaling
Scheduling
Patching
Provisioning
Key attributes
Attributes that distinguish serverless computing from other compute models:
No provisioning of servers and runtimes
Runs code on-demand, scaling as needed
Pay only when invoked and used
i.e., not when underlying computer resources are idle.
Serverless
Abstracts the infrastructure away from developers
Code executed as individual functions
No prior execution context is required
A Scenario
Serverless computing services
IBM Cloud Functions
AWS Lambda
Microsoft Azure Functions
Determining Fit with Serverless
Evaluate application characteristics
Ensure that the application is aligned to serverless architecture patterns
Applications that qualify for a serverless architecture include:
Short-running stateless functions
Seasonal workloads
Production volumetric data
Event-based processing
Stateless microservices
Use Cases
Serverless architecture are well-suited for use cases around:
Data and event processing
IoT
Microservices
Mobile backends
Serverless is well-suited to working with:
Text
Audio
Image
Video
Tasks:
Data enrichment
Transformation
Validation and cleansing
PDF processing
Audio normalization
Thumbnail generation
Video transcoding
Data search and processing
Genome processing
Data Streams:
Business
IoT sensor data
Log data
Financial market data
Challenges
Vendor Dependent Capabilities
Authentication
Scaling
Monitoring
Configuration management
Cloud Native Applications, DevOps, and Application Modernization
Cloud Native Applications
Developed to work only in the cloud environment
Refactored and reconfigured with cloud native principles
Development Principles
Whether creating a new cloud native application or modernizing an existing application:
Microservices Architecture
Rely on Containers
Adopt Agile Methods
Benefits
Innovation
Agility
Commoditization
DevOps on the Cloud
What is DevOps?
Dev Teams:
Design Software
Develop Software
Deliver Software
Run Software
Ops Teams
Monitoring
Predicting Failure
Managing Environment
Fixing Issues
A collaborative approach that allows multiple stakeholders to collaborate:
Business owners
Development
Operations
Quality assurance
The DevOps Approach
It applies agile and lean thinking principles to all stakeholders in an organization who develop, operate, or benefit from the business’s software systems, including customers, suppliers, partners. By extending lean principles across the software supply chain, DevOps capabilities improve productivity through accelerated customer feedback cycles, unified measurements and collaboration across an enterprise, and reduced overhead, duplication, and rework.
Using the DevOps approach:
Developers can produce software in short iterations
A continuous delivery schedule of new features and bug fixes in rapid cycles
Businesses can seize market opportunities
Accelerated customer feedback into products
DevOps Process
Continuous Delivery
Continuous Integration
Continuous Deployment
Continuous Monitoring
Delivery Pipeline
DevOps and Cloud
With its near limitless compute power and available data and application services, cloud computing platforms come with their own risks and challenges, which can be overcome by DevOps:
Tools
Practices
Processes
DevOps provides the following solutions to cloud’s complexities:
Automated provisioning and installation
Continuous integration and deployment pipelines
Define how people work together and collaborate
Test in low-cost, production-like environments
Recover from disasters by rebuilding systems quickly and reliably
Application Modernization
Enterprise Applications
Application Modernization
Architecture: Monoliths > SOA (Service Oriented Architecture) > Microservices
Infrastructure: Physical servers > VM > Cloud
Delivery: Waterfall > Agile > DevOps
Cloud Security, Monitoring, Case Studies, Jobs
What is Cloud Security
The security in context of cloud is a shared responsibility of:
User
Cloud Provider
Protect data
Manage access
SEC DevOps
Secure Design
Secure Build
Manage Security
Identity and Access Management
Biggest cloud security concerns are:
Data Loss and Leakage
Unauthorized Access
Insecure Interfaces and APIs
Identity and Access Management are:
First line of defense
Authenticate and authorize users
Provide user-specific access
Main types of users
A comprehensive security strategy needs to encompass the security needs of a wide audience:
Organizational users
Internet and social-based users
Third-party business partner organizations
Vendors
There are three main type of users:
Administrative users
Developer users
Application users
Administrative Users
Administrators | Operators | Mangers
roles that typically create, update, and delete application and instances, and also need insight into their team members’ activities.
It is used to combat identity theft by adding another level of authentication for application users.
Cloud Directory Services
They are used to securely manage user profiles and their associated credentials and password policy inside a cloud environment.
Applications hosted on the cloud do not need to use their own user repository
Reporting
It helps provide a user-centric view of access to resources or a resource-centric view of access by users:
which users can access which resources
changes in user access rights
access methods used by each user
Audit and Compliance
Critical service within identity and access management framework, both for cloud provider, and cloud consumer.
User and service access management
It enables cloud application/service owners to provision and de-provision:
Streamline access control based on:
Role
Organization
Access policies
Mitigating Risks
Some of the controls that can help secure these sensitive accounts include:
Provisioning users by specifying roles on resources for each user
Password policies that control the usage of special characters, minimum password lengths, and other similar settings
Multifactor authentication like time-based one-time passwords
Immediate provisioning of access when users leave or change roles
Access Groups
A group of users and service IDs created so that the same access can be assigned to all entities within the group with one or more access policies.
Access Policies
Access policies define how users, service IDs, and access groups in the account are given permission to access account resources.
Access Group Benefits
Streamline access assignment process vs. assigning individual user access
Reduce number of policies
Cloud Encryption
Encryption
It plays a key role on cloud, and is often referred to as the last line of defense, in a layered security model.
Encrypts Data
Data Access Control
Key management
Certificate management
Definition
Scrambling data in a way that makes it illegible.
Encryption Algorithm:
Defines rules by which data will be transformed
Decryption Key:
Defines how encrypted data will be transformed back to legible data.
It makes sure:
Only authorized users have access to sensitive data.
When accessed without authorization, data is unreadable and meaningless.
Cloud Encryption Services
Can be limited to encryption of data that is identified as sensitive, or
end-to-end encryption of all data uploaded to the cloud
Data Protection States
Encryption at Rest:
Protects stored data
Multiple encryption options:
Block and file storage
Built-in for object storage
Database encryption
Encryption in Transit:
Protects data while transmitting
Includes encrypting before transmission
Authenticates endpoints
Decrypts data on arrival
Secure Socket Layer (SSL)
Transport Layer Security (TSL)
Encryption in Use:
Protects data in use in memory
Allows computations to be performed on encrypted text without decryption
Client or Server-side Encryption
Cloud storage encryption could be server-side or client-side.
Server-side:
Create and manage your own encryption keys, or
Generate and manage keys on cloud
Client-side:
Occurs before data is sent to cloud
Cloud providers cannot decrypt hosted data
There is a need to implement a singular data protection strategy across an enterprise’s on-premise, hybrid, and multi-cloud deployments.
Multi-Cloud Data Encryption
Features:
Data access management
Integrated key management
Sophisticated encryption
Multi-cloud encryption console:
Define and manage access policies
Create, rotate, and manage keys
Aggregate access logs
Key Management
Encryption doesn’t eliminate security risk.
It separates the security risk from the data itself.
Keys need to be managed and protected against threats.
Key Management Services
They enable customers to:
Encrypt sensitive data at rest
Easily create and manage the entire lifecycle of cryptographic keys
Protect data from cloud service providers
Key Management Best Practices
Storing encryption keys separately from the encrypted data
Taking key backups offsite and auditing them regularly
Refreshing the keys periodically
Implementing multifactor authentication for both the master and recovery keys
Cloud Monitoring Basics and Benefits
Cloud Monitoring Solutions
Monitoring performance across an entire stack of applications and services can be time-consuming and draining on internal resources.
Cloud Monitoring Assessment
Cloud Monitoring Features
Cloud monitoring includes:
Strategies
Practices
Processes
Used for:
Analyzing
Tracking
Managing services and apps
It also serves to provide actionable insights that can help improve availability and user experience.
Cloud Monitoring Helps to:
Accelerate the diagnosis and resolution of performance incidents
Control the cost of your monitoring infrastructure
Mitigate the impact of abnormal situations with proactive notifications
Get critical Kubernetes and container insights for dynamic microservice monitoring
Troubleshoot your applications and infrastructure
Cloud Monitoring Solutions Provide:
Data in real-time with round the clock monitoring of VMs, services, databases, apps
Multilayer visibility into application, user, and file access behavior across all apps
Advanced reporting and auditing capabilities for ensuring regulatory standards
Large-scale performance monitoring integrations across multicloud and hybrid cloud
Cloud Monitoring Categories
Infrastructure
Help identify minor and large-scale failures
So that developers can take corrective action
Database
Help track processes, queries, and availability of services
To ensure accuracy and reliability
Application Performance and Monitoring
Help improve user experience
Meet app and user SLAs
Minimize downtime and lower operational costs
Cloud Monitoring Best Practices
To get the most benefit from your cloud-based deployments, you can follow some standard cloud monitoring best practices.
Leverage end-user experience monitoring solutions
Move all aspects of infrastructure under one monitoring platform
Use monitoring tools that help track usage and cost
Increase cloud monitoring automation
Simulate outages and breach scenarios
Cloud monitoring needs to be a priority for organizations looking to leverage the benefits of cloud technologies.
Case Studies and Jobs
Case Studies in Different Industry Verticals
The Weather Company migrating to the cloud to reliably deliver critical weather data at high speed, especially during major weather events such as hurricanes and tornadoes
American Airlines, using the cloud platform and technologies to deliver digital self-service tools and customer value more rapidly across its enterprise
Cementos Pacasmayo, achieving operational excellence and insight to help drive strategic transformation and reach new markets using cloud services
Welch choosing cloud storage to drive business value from hybrid cloud
Liquid Power using cloud-based SAP applications to fuel business growth
Career Opportunities and Job Roles in Cloud Computing
Cloud Developers
Cloud Integration Specialists
Cloud Data Engineer
Cloud Security Engineers
Cloud DevOps Engineers
Cloud Solutions Architects
Cybersecurity & Networks
IBM Cybersecurity Analyst Professional Certificate
IBM Cybersecurity Analyst Professional Certificate is a specialization course, which is led by industry experts. The specialization focuses on intermediary skills related to cybersecurity
This specialization has 6 courses and a Capstone.
1. Introduction to Cybersecurity Tools and Cyberattacks
It teaches:
History of major cyber attacks throughout the modern history
Types of Threat actors (APT, hacktivist etc), and their motives
Cybersecurity Specialization is an advanced course offered by University of Maryland. It dives deep into the core topics related to software security, cryptography, hardware etc.
Info
My progress in this specialization came to a halt after completing the first course, primarily because the subsequent courses were highly advanced and required background knowledge that I lacked. I will resume my journey once I feel confident in possessing the necessary expertise to tackle those courses.
1. Usable Security
This course is all about principles of Human Computer Interaction, designing secure systems, doing usability studies to evaluate the most efficient security model and much more…
IBM Cybersecurity Analyst Professional Certificate
IBM Cybersecurity Analyst Professional Certificate is a specialization course, which is led by industry experts. The specialization focuses on intermediary skills related to cybersecurity
This specialization has 6 courses and a Capstone.
1. Introduction to Cybersecurity Tools and Cyberattacks
It teaches:
History of major cyber attacks throughout the modern history
Types of Threat actors (APT, hacktivist etc), and their motives
Subsections of Cybersecurity Tools and Cyberattacks
History of Cybersecurity
Introduction to Cybersecurity Tools & Cyberattacks
Today’s Cybersecurity Challenge
Threats > ⇾ Alerts > ⇾ Available Analyst < -⇾ Needed Knowledge > ⇾ Available Time <
By 2022, there will be 1.8 millions unfulfilled cybersecurity jobs.
SOC(Security Operation Center) Analyst Tasks
Review security incidents in SIEM (security information and even management)
Review the data that comprise the incident (events/flows)
Pivot the data multiple ways to find outliers (such as unusual domains, IPs,
file access)
Expand your search to capture more data around that incident
Decide which incident to focus on next
Identify the name of the malware
Take these newly found IOCs (indicators of compromise) from the internet and search them back in SIEM
Find other internal IPs which are potentially infected with the same malware
Search Threat Feeds, Search Engine, Virus Total and your favorite tools for these outliers/indicators; Find new malware is at play
Start another investigation around each of these IPs
Review the payload outlying events for anything interesting (domains, MD5s, etc.)
Search more websites for IOC information for that malware from the internet
From Ronald Reagan/War Games to where we are Today
He was a Hollywood actor as well as US-president
He saw a movie War Games, where a teenager hacker hacked into the Pentagon artificial intelligent computer to play a game of thermonuclear war using a dial-up connection, which was actually played using real missiles due to miss-configuration
Impact of 9/11 on Cybersecurity
What happens if 9/11 in tech-space? Like hack and destruction of SCADA system used in dams and industrial automation systems etc.
Nice early operations
Clipper Chip: (NSA operation for tapping landline phones using some kind of chip)
↔
Moonlight Maze: (in the 2000s, process to dump passwords of Unix/Linux servers investigated by NSA/DOD affected many US institutions)
↔
Solar Sunrise: (series of attack on DOD computers on FEB 1998, exploited known vulnerability of operating system, attack two teenagers in California, one of whom was an Israeli)
↔
Buckshot Yankee: (series of compromises in year 2008, everything starts with USB inserted in Middle East military base computer, remained on the network for 14 months, Trojan used was agent.BTZ)
↔
Desert Storm: (early 90s, some radars used to alert military forces about airplanes are tampered by feeding fake information of Saddam’s regime)
↔
Bosnia: (Bosnia war, fake news to military field operations etc.)
Cybersecurity Introduction
Every minute, thousands of tweets are sent, and millions of videos are watched.
Due to IOT (Internet of Things) and mobile tech, we have a lot to protect.
We have multiple vendors now, which become complicated to track for security vulnerabilities.
Things to Consider when starting a Cybersecurity Program
How and where to start?
Security Program: Evaluate, create teams, baseline, identify and model threats, use cases, risk, monitoring, and control.
Admin Controls: Policies, procedures, standards, user education, incident response, disaster recovery, compliance and physical security.
Asset Management: Classifications, implementation steps, asset control, and documents.
Cybersecurity – A Security Architect’s Perspective
What is Security?
A message is considered secure when it meets the following criteria of CIA triad.
Confidentiality ↔ Authentication ↔ Integrity
Computer Security, NIST (National Institute of Standards and Technology) defined.
“The protection afforded to an automated information system in order to attain the applicable objectives to preserving the integrity, availability, and Confidentiality of information system resources. Includes hardware, software, firmware, information/data, and telecommunications.”
Additional Security Challenges
Security not as simple as it seems
Easy requirements, tough solution
Solutions can be attacked themselves
Security Policy Enforcement structure can complicate solutions
Protection of enforcement structure can complicate solutions
Solution itself can be easy but complicated by protection
Protectors have to be right all the time, attackers just once
No one likes security until it’s needed, seat belt philosophy.
Security Architecture require constant effort
Security is viewed as in the way
What is Critical Thinking?
Beyond Technology: Critical Thinking in Cybersecurity
“The adaption of the processes and values of scientific inquiry to the special circumstances of strategic intelligence.”
Cybersecurity is a diverse, multi faced field
Constantly changing environment
Fast-paced
Multiple stakeholders
Adversary presence
Critical thinking forces you to think and act in situations where there are no clear answers nor specific procedures.
Part Art, Part Science: This is subjective and impossible to measure.
Critical Thinking: A Model
Hundreds of tools updating always with different working models, so critical thinking is more important than ever to approach problems in more pragmatic way.
Interpersonal skills for working with other people and sharing information.
Critical Thinking – 5 Key Skills
1) Challenge Assumption
question your Assumption
Explicitly list all Assumptions ↔ Examine each with key Q’s ↔ Categorize based on evidence ↔ refine and remove ↔ Identify additional data needs
2) Consider alternatives
Brainstorm ↔ The 6 W’s (who/what/when/where/why/how) ↔ Null hypothesis
3) Evaluate data
Know your DATA
Establish a baseline for what’s normal
be on the lookout for inconsistent data
proactive
4) Identify key drivers
Technology
Regulatory
Society
Supply Chain
Employee
Threat Actors
5) Understand context
Operational environment you’re working in. Put yourself in other’s shoe, reframe the issue.
Key components
Factors at play
Relationships
similarities/differences
redefine
A Brief Overview of Types of Threat Actors and their Motives
Internal Users
Hackers (Paid or not)
Hacktivism
Governments
Motivation Factors
Just to play
Political action and movements
Gain money
Hire me! (To demonstrate what can I do for somebody to hire me or use my services)
Hacking organizations
Fancy Bears (US election hack)
Syrian Electronic Army
Guardians of the peace (Leaked Sony Data about film regarding Kim Jong-un to prevent its release)
Nation States
NSA
Tailored Access Operations (USA)
GCHQ (UK)
Unit 61398 (China)
Unit 8200 (Israel)
Major different types of cyberattacks
Sony Hack
Play-station Hack by a Hacktivist group called Lutz (2011).
Singapore cyberattack
Anonymous attacked multiple websites in Singapore as a protest (2013).
Target Hack
More than 100 million of credit cards were leaked (2015).
Malware and attacks
SeaDaddy and SeaDuke (CyberBears US Election)
BlackEnergy 3.0 (Russian Hackers)
Shamoon (Iran Hackers)
Duqu and Flame (Olympic Games US and Israel)
DarkSeoul (Lazarous and North Korea)
WannaCry (Lazarous and North Korea)
An Architect’s perspective on attack classifications
Security Attack Definition
Two main classifications
Passive attacks
Essentially an eavesdropping styles of attacks
Second class is traffic analysis
Hard to detect the passive nature of attack as just traffic is monitored not tampered
Active Attacks
Explicit interception and modification
Several classes of these attack exist
Examples
Masquerade (Intercepting packets as someone else)
Replay
Modification
DDoS
Security Services
“A process or communication service that is provided by a system, to give a specific kind of protection to a system resource.”
Security services implement security policies. And are implemented by security mechanisms
X.800 definition:
“a service provided by a protocol layer of communicating open systems, which ensures adequate security of the systems or of data transfers”
RFC 2828:
“a processing or communication service provided by a system to give a specific kind of protection to system resources”
Security Service Purpose
Enhance security of data processing systems and information transfers of an organization
Intended to counter security attacks
Using one or more security mechanisms
Often replicates functions normally associated with physical documents
which, for example, have signatures, dates; need protection from disclosure, tampering, or destruction, be notarized or witnessed; be recorded or licensed
Security Services, X.800 style
Authentication
Access control
Data confidentiality
Data integrity
Non-repudiation (protection against denial by one of the parties in a communication)
Availability
Security Mechanisms
Combination of hardware, software, and processes
That implement a specific security policy
Protocol suppression, ID and Authentication, for example
Mechanisms use security services to enforce security policy
Specific security mechanisms:
Cryptography, digital signatures, access controls, data integrity, authentication exchange, traffic padding, routing control, notarization
Security: It is used in the sense of minimizing the vulnerabilities of assets and resources.
An asset is anything of value
A vulnerability is any weakness that could be exploited to violate a system or the information it contains
A threat is a potential violation of security
Security Architecture and Motivation
The motivation for security in open systems
- a) Society’s increasing dependence on computers that are accessed by, or linked by, data communications and which require protection against various threats;
- b) The appearance in several countries of “data protection” which obliges suppliers to demonstrate system integrity and privacy;
- c) The wish of various organizations to use OSI recommendations, enhanced as needed, for existing and future secure systems
Security Architecture – Protection
What is to be protected?
- a) Information or data;
- b) communication and data processing services; and
- c) equipment and facilities
Organizational Threats
The threats to a data communication system include the following
a) destruction of information and/or other resources
b) corruption or modification of information
c) theft, removal, or loss of information and/or other resources
d) disclosure of information; and
e) interruption of services
Types of Threats
Accidental threats do not involve malicious intent
Intentional threats require a human with intent to violate security.
If an intentional threat results in action, it becomes an attack.
Passive threats do not involve any (non-trivial) change to a system.
Active threats involve some significant change to a system.
Attacks
“An attack is an action by a human with intent to violate security.”
It doesn’t matter if the attack succeeds. It is still considered an attack even if it fails.
Passive Attacks
Two more forms:
Disclosure (release of message content)
This attacks on the confidentiality of a message.
Traffic analysis (or traffic flow analysis)
also attacks the confidentiality
Active Attacks
Fours forms:
I) Masquerade: impersonification of a known or authorized system or person
II)Replay: a copy of a legitimate message is captured by an intruder and re-transmitted
III) Modification
IV) Denial of Service: The opponent prevents authorized users from accessing a system.
Security Architecture – Attacks models
Passive Attacks
Active Attacks
Malware and an Introduction to Threat Protection
Malware and Ransomware
Malware: Short for malicious software, is any software used to disrupt computer or mobile operations, gather sensitive information, gain access to private computer systems, or display unwanted advertising. Before the term malware was coined by Yisrael Radai in 1990. Malicious software was referred to as computer viruses.
Types of Malware
Viruses
Worms
Trojans Horses
Spyware
Adware
RATs
Rootkit
Ransomware: A type of code which restricts the user’s access to the system resources and files.
Other Attack Vectors
Botnets
Keyloggers
Logic Bombs (triggered when certain condition is met, to cripple the system in different ways)
APTs (Advanced Persistent Threats: main goal is to get access and monitor the network to steal information)
Some Known Threat Actors
Fancy Bears: Russia
Lazarous Groups: North Korea
Periscope Group: China
Threat Protection
Technical Control
Antivirus (AV)
IDS (Intrusion Detection System)
IPS (Intrusion Protection System)
UTM (Unified Threat Management)
Software Updates
Administrative Control
Policies
Trainings (social engineering awareness training etc.)
Revision and tracking (The steps mentioned should remain up-to-date)
Additional Attack Vectors Today
Internet Security Threats – Mapping
Mapping
before attacking; “case the joint" – find out what services are implemented on network
Use ping to determine what hosts have addresses on network
Post scanning: try to establish TCP connection to each port in sequence (see what happens)
NMap Mapper: network exploration and security auditing
Mapping: Countermeasures
record traffic entering the network
look for suspicious activity (IP addresses, ports being scanned sequentially)
use a host scanner and keep a good inventory of hosts on the network
Red lights and sirens should go off when an unexpected ‘computer’ appears on the network
Internet Security Threats – Packet Sniffing
Packet Sniffing
broadcast media
promiscuous NIC reads all packets passing by
can read all unencrypted data
Packet Sniffing – Countermeasures
All hosts in the organization run software that checks periodically if host interface in promiscuous mode.
One host per segment of broadcast media.
Internet Security Threats – IP Spoofing
IP Spoofing
can generate ‘raw’ IP packets directly from application, putting any value into IP source address field
receiver can’t tell if source is spoofed
IP Spoofing: ingress filtering
Routers should not forward out-going packets with invalid source addresses (e.g., data-gram source address not in router’s network)
Great, but ingress can not be mandated for all networks
Internet Security Threats – Denial of Service
Denial of service
flood of maliciously generated packets ‘swamp’ receiver
filter out flooded (e.g., SYN) before reaching host: throw out good with bad
trace-back to source of floods (most likely an innocent, compromised machine)
Internet Security Threats – Host insertions
Host insertions
generally an insider threat, a computer ‘host’ with malicious intent is inserted in sleeper mode on the network
Host insertions – Countermeasures
Maintain an accurate inventory of computer hosts by MAC addresses
Use a host scanning capability to match discoverable hosts again known inventory
Missing hosts are OK
New hosts are not OK (red lights and sirens)
Attacks and Cyber Crime Resources
The Cyber Kill Chain
Reconnaissance: Research, identification and selection of targets
Weaponizations: Pairing remote access malware with exploit into a deliverable payload (e.g., adobe PDF and Microsoft Office files)
Delivery: Transmission of weapon to target (e.g., via email attachments, websites, or USB sticks)
Exploitation: Once delivered, the weapon’s code is triggered, exploiting vulnerable application or systems
Installation: The weapon installs a backdoor on a target’s system allowing persistent access
Command & Control: Outside server communicates with the weapons providing ‘hands on keyboard access’ inside the target’s network.
Actions on Objectives: the attacker works to achieve the objective of the intrusion, which can include ex-filtration or destruction of data, or intrusion of another target.
What is Social Engineering?
“The use of humans for cyber purposes”
Tool: The Social-Engineer Toolkit (SET)
Phishing
“To send fake emails, URLs or HTML etc.”
Tool: Gopish
Vishing
“Social Engineering via Voice and Text.”
Cyber warfare
Nation Actors
Hacktivist
Cyber Criminals
An Overview of Key Security Concepts
CIA Triad
CIA Triad – Confidentiality
“To prevent any disclosure of data without prior authorization by the owner.”
We can force Confidentiality with encryption
Elements such as authentication, access controls, physical security and permissions are normally used to enforce Confidentiality.
CIA Triad – Integrity
Normally implemented to verify and validate if the information that we sent or received has not been modified by an unauthorized person of the system.
We can implement technical controls such as algorithms or hashes (MD5, SHA1, etc.)
CIA Triad – Availability
The basic principle of this term is to be sure that the information and data is always available when needed.
Technical Implementations
RAIDs
Clusters (Different set of servers working as one)
ISP Redundancy
Back-Ups
Non-Repudiation – How does it apply to CIA?
“Valid proof of the identity of the data sender or receiver”
Technical Implementations:
Digital signatures
Logs
Access Management
Access criteria
Groups
Time frame and specific dates
Physical location
Transaction type
“Needed to Know” Just access information needed for the role
Single Sign-on (SSO)
Incident Response
“Computer security incident management involves the monitoring and detection of security events on a computer or a computer network and the execution of proper resources to those events. Means the information security or the incident management team will regularly check and monitor the security events occurring on a computer or in our network.”
Incident Management
Events
Incident
Response team: Computer Security Incident Response Team (CSIRT)
Investigation
Key Concepts – Incident Response
E-Discovery
Data inventory, helps to understand the current tech status, data classification, data management, we could use automated systems. Understand how you control data retention and backup.
Automated Systems
Using SIEM, SOA, UBA, Big data analysis, honeypots/honey-tokens. Artificial Intelligence or other technologies, we could enhance the mechanism to detect and control incidents that could compromise the tech environment.
Understand the company in order to prepare the BCP. A BIA, it’s good to have a clear understanding of the critical business areas. Also indicate if a security incident will trigger the BCP or the Disaster Recovery.
Post Incident
Root-Cause analysis, understand the difference between error, problem and isolated incident. Lessons learned and reports are a key.
Incident Response Process
Prepare
Respond
Follow up
Introduction to Frameworks and Best Practices
Best Practices, baseline, and frameworks
Used to improve the controls, methodologies, and governance for the IT departments or the global behavior of the organization.
Seeks to improve performance, controls, and metrics.
Helps to translate the business needs into technical or operational needs.
Normative and compliance
Rules to follow for a specific industry.
Enforcement for the government, industry, or clients.
Event if the company or the organization do not want to implement those controls, for compliance.
Best practices, frameworks, and others
COBIT
ITIL
ISOs
COSO
Project manager methodologies
Industry best practices
Developer recommendations
others
IT Governance Process
Security Policies, procedures, and other
Strategic and Tactic plans
Procedures
Policies
Governance
Others
Cybersecurity Compliance and Audit Overview
Compliance;
SOX
HIPAA
GLBA
PCI/DSS
Audit
Define audit scope and limitations
Look for information, gathering information
Do the audit (different methods)
Feedback based on the findings
Deliver a report
Discuss the results
Pentest Process and Mile 2 CPTE Training
Pentest – Ethical Hacking
A method of evaluating computer and network security by simulating an attack on a computer system or network from external and internal threats.
An Overview of Key Security Tools
Introduction to Firewalls
Firewalls
“Isolates the organization’s internal net from the larger Internet, allowing some packets to pass, while blocking the others.”
Firewalls – Why?
Prevent denial-of-service attacks;
SYN flooding: attacker establishes many bogus TCP connections, no resources left for “real” connections.
Prevent illegal modification/access of internal data.
e.g., attacker replaces CIA’s homepage with something else.
Allow only authorized access to inside network (set of authenticated users/hosts)
Two types of Firewalls
Application level
Packet filtering
Firewalls – Packet Filtering
Internal network connected to internet via router firewall
router filters packet-by-packet, decision to forward/drop packet based on;
source IP address, destination IP address
TCP/UDP source and destination port numbers
ICMP message type
TCP SYNC and ACK bits
Firewalls – Application Gateway
Filters packets on application data as well as on IP/TCP/UDP fields.
Allow select internal users to telnet outside:
Require all telnet users to telnet through gateway.
For authorized users, the gateway sets up a telnet connection to the destination host. The gateway relays data between 2 connections.
Router filter blocks all telnet connections not originating from gateway.
Limitations of firewalls and gateways
IP spoofing: router can’t know if data “really” comes from a claimed source.
If multiple app’s need special treatment, each has the own app gateway.
Client software must know how to contact gateway.
e.g., must set IP address of proxy in Web Browser.
Filters often use all or nothing for UDP.
Trade-off: Degree of communication with outside world, level of security
Many highly protected sites still suffer from attacks.
Firewalls – XML Gateway
XML traffic passes through a conventional firewall without inspection;
All across normal ‘web’ ports
An XML gateway examines the payload of the XML message;
Well formed (meaning to specific) payload
No executable code
Target IP address makes sense
Source IP is known
Firewalls – Stateless and Stateful
Stateless Firewalls
No concept of “state”.
Also called Packet Filter.
Filter packets based on layer 3 and layer 4 information (IP and port).
Lack of state makes it less secure.
Stateful Firewalls
Have state tables that allow the firewall to compare current packets with previous packets.
Could be slower than packet filters but far more secure.
Application Firewalls can make decisions based on Layer 7 information.
Proxy Firewalls
Acts as an intermediary server.
Proxies terminate connections and initiate new ones, like a MITM.
There are two 3-way handshakes between two devices.
Antivirus/Anti-malware
Specialized software that can detect, prevent and even destroy a computer virus or malware.
Uses malware definitions.
Scans the system and search for matches against the malware definitions.
These definitions get constantly updated by vendors.
An Introduction of Cryptography
Cryptography is secret writing.
Secure communication that may be understood by the intended recipient only.
There is data in motion and data at rest. Both need to be secured.
Not new, it has been used for thousands of years.
Egyptians hieroglyphics, Spartan Scytale, Caesar Cipher, are examples of ancient Cryptography.
Cryptography – Key Concepts
Confidentiality
Integrity
Authentication
Non-repudiation
Crypto-analysis
Cipher
Plaintext
Ciphertext
Encryption
Decryption
Cryptographic Strength
Relies on math, not secrecy.
Ciphers that have stood the test of time are public algorithms.
Mono-alphabetic < Poly-alphabetic Ciphers
Modern ciphers use Modular math
Exclusive OR(XOR) is the “secret sauce” behind modern encryption.
Types of Cipher
Stream Cipher: Encrypt or decrypt, a bit per bit.
Block Cipher: Encrypt or decrypt in blocks or several sizes, depending on the algorithms.
Types of Cryptography
Three main types;
Symmetric Encryption
Asymmetric Encryption
Hash
Symmetric Encryption
Use the same key to encrypt and decrypt.
Security depends on keeping the key secret at all times.
Strengths include speed and Cryptographic strength per a bit of key.
The bigger the key, the stronger the algorithm.
Key need to be shared using a secure, out-of-band method.
DES, Triples DES, AES are examples of Symmetric Encryption.
Asymmetric Encryption
Whitefield Diffie and Martin Hellman, who created the Diffie-Hellman. Pioneers of Asymmetric Encryption.
Uses two keys.
One key ban be made public, called public key. The other one needs to be kept private, called Private Key.
One for encryption and one for decryption.
Used in digital certificates.
Public Key Infrastructure – PKI
It uses “one-way” algorithms to generate the two keys. Like factoring prime numbers and discrete logarithm.
Slower than Symmetric Encryption.
Hash Functions
A hash function provides encryption using an algorithm and no key.
A variable-length plaintext is “hashed” into a fixed-length hash value, often called a “message digest” or simply a “hash”.
If the hash of a plaintext changes, the plaintext itself has changed.
This provides integrity verification.
SHA-1, MD5, older algorithms prone to collisions.
SHA-2 is the newer and recommended alternative.
Cryptographic Attacks
Brute force
Rainbow tables
Social Engineering
Known Plaintext
Known ciphertext
DES: Data Encryption Standard
US encryption Standard (NIST, 1993)
56-bit Symmetric key, 64-bit plaintext input
How secure is DES?
DES Challenge: 56-bit-key-encrypted phrase (“Strong Cryptography makes the world a safer place”) decrypted (brute-force) in 4 months
No known “back-doors” decryption approach.
Making DES more secure
Use three keys sequentially (3-DES) on each datum.
Use cipher-block chaining.
AES: Advanced Encryption Standard
New (Nov. 2001) symmetric-key NIST standard, replacing DES.
Processes data in 128-bit blocks.
128, 192, or 256-bit keys.
Brute-force decryption (try each key) taking 1 sec on DES, takes 149 trillion years for AES.
First look at Penetration Testing and Digital Forensics
Penetration Testing – Introduction
Also called Pentest, pen testing, ethical hacking.
The practice of testing a computer system, network, or application to find security vulnerabilities that an attacker could exploit.
Hackers
White Hat
Grey Hat
Black Hat
Threat Actors
“An entity that is partially or wholly responsible for an incident that affects or potentially affects an organization’s security. Also referred to as malicious actor.”
There are different types;
Script kiddies
Hacktivists
Organized Crime
Insiders
Competitors
Nation State
Fancy Bear (APT28)
Lazarous Group
Scarcruft (Group 123)
APT29
Pen-test Methodologies
Vulnerability Tests
What is Digital Forensics?
Branch of Forensics science.
Includes the identification, recovery, investigation, validation, and presentation of facts regarding digital evidence found on the computers or similar digital storage media devices.
Locard’s Exchange Principle
DR. Edmond Locard;
“A pioneer in Forensics science who became known as the Sherlock Holmes of France.”
The perpetrator of a crime will bring something into the crime scene and leave with something from it, and that both can be used as Forensic evidence.
Chain of Custody
Refers to the chronological documentation or paper trail that records the sequence of custody, control, transfer, analysis, and disposition of physical or electronic evidence.
It is often a process that has been required for evidence to be shown legally in court.
Tools
Hardware
Faraday cage
Forensic laptops and power supplies, tool sets, digital camera, case folder, blank forms, evidence collection and packaging supplies, empty hard drives, hardware write blockers.
Software
Volatility
FTK (Paid)
EnCase (Paid)
dd
Autopsy (The Sleuth Kit)
Bulk Extractor, and many more.
Cybersecurity Roles, Processes and Operating System Security
Subsections of Cybersecurity Roles, Proces and OS Security
People Processes and Technology
Frameworks and their Purpose
Best practices, baseline, and frameworks
Used to improve the controls, methodologies, and governance for the IT departments or the global behavior of the organization.
Seeks to improve performance, controls, and metrics.
Helps to translate the business needs into technical or operational needs.
Normative and Compliance
Rules to follow for a specific industry.
Enforcement for the government, industry, or clients.
Event if the company or the organization do not want to implement those controls for compliance.
Best practices, frameworks & others
Frameworks
COBIT (Control Objective for Information and Related Technologies)
COBIT is a framework created by ISACA for IT management and IT governance. The framework is business focused and defines a set of generic processes for the management of IT, with each process defined together.
ITIL (The Information Technology Infrastructure Library)
ITIL is a set of detailed practices for IT activities such as IT service management (ITSM) and IT asset management (ITAM) that focus on aligning IT services with the needs of business.
ISOs (International Organization for Standardization)
COSO (Committee of Sponsoring Organization of the Tread way Commission)
COSO is a joint initiative to combat corporate fraud.
Project manager methodologies
Industry best practices
Developer recommendations
Others
Roles in Security
CISO (Chief Information Security Officer)
The CISO is a high-level management position responsible for the entire computer security department and staff.
Information Security Architect
Information Security Consultant/Specialist
Information Security Analyst
This position conducts Information security assessments for organizations and analyzes the events, alerts, alarms and any Information that could be useful to identify any threat that could compromise the organization.
Information Security Auditor
This position is in charge of testing the effectiveness of computer information systems, including the security of the systems, and reports their findings.
Security Software Developer
Penetration Tester / Ethical Hacker
Vulnerability Assessor
etc.
Business Process Management (BPM) and IT Infrastructure Library (ITIL) Basics
Introduction to Process
Processes and tools should work in harmony
Security Operations Centers (SOC) need to have the current key skills, tools, and processes to be able to detect, investigate and stop threats before they become costly data breaches.
As volumes of security alerts and false positives grow, more burden is placed upon Security Analyst and Incident Response Teams.
Business Process Management (BPM) Overview
“A set of defined repeatable steps that take inputs, add value, and produce outputs that satisfy a customer’s requirements.”
Attributes of a Process
Inputs:
Information or materials that are required by the process to get started.
Outputs:
Services, or products that satisfy customer requirements.
Bounds/Scope:
The process starts when and end when.
Tasks/Steps:
Actions that are repeatable.
Documentation:
For audit, compliance, and reference purposes.
Standard Process Roles
What makes a Process Successful?
Charter
Clear Objectives
Governance/Ownership
Repeatability (reduced variation)
Automation
Established Performance indicators (metrics)
Process Performance Metrics
“It is critical that we measure our processing, so understand if they are performing to specifications and producing the desired outcome every time; and within financial expectations.”
Typical Categories
Cycle Time
Cost
Quality (Defect Rate)
Rework
Continual Process Improvement
Information Technology Infrastructure Library (ITIL) Overview
ITIL is a best practice framework that has been drawn from both the public and private sectors internationally.
It describes how IT resources should be organized to deliver Business value.
It models how to document processes and functions, in the roles of IT Service Management (ITSM).
ITIL Life-cycle – Service Phases
Service Strategy
Service Design
Service Transition
Service Operations
Service Improvements
ITIL Life-cycle – Service Strategy
Service Portfolio Management
Financial Management
Demand Management
Business Relationship Management
ITIL Life-cycle – Service Design
Service Catalog Management
Service Level Management
Information Security Management
Supplier Management
ITIL Life-cycle – Service Transition
Change Management
Project Management
Release & Deployment Management
Service validation & Testing
Knowledge Management
ITIL Life-cycle – Service Operations
Event Management
Incident Management
Problem Management
ITIL Life-cycle – Continual Service Improvement (CSI)
Review Metrics
Identify Opportunities
Test & Prioritize
Implement Improvements
Key ITIL Processes
Problem Management
The process responsible for managing the Life-cycle of all problems.
ITIL defines a ‘problem’ as ‘an unknown cause of one or more incidents.’
Change Management
Manage changes to baseline service assets and configuration items across the ITIL Life-cycle.
Incident Management
An incident is an unplanned interruption to an IT Service, a reduction in the quality of an IT Service, and/ or a failure of a configuration item.
Events are any detectable or discernible occurrence that has significance for the management of IT Infrastructure, or the delivery of an IT service.
Service Level Management
This involves the planning coordinating, drafting, monitoring, and reporting on Service Level Agreements (SLAs). It is the ongoing review of service achievements to ensure that the required service quality is maintained and gradually improved.
Information Security Management
This deals with having and maintaining an information security policy (ISP) and specific security Policies that address each aspect of strategy, Objectives, and regulations.
Difference between ITSM and ITIL
Information Technology Service Management (ITSM)
“ITSM is a concept that enables an organization to maximize business value from the use of information Technology.”
IT Infrastructure Library (ITIL)
“ITIL is a best practice framework that gives guidance on how ITSM can be delivered.”
Further discussion of confidentiality, integrity, and availability
Who are Alice, Bob, and Trudy?
Well known in network security world.
Bob, Alice (friends) want to communicate “securely”.
Trudy (intruder) may intercept, delete, add messages.
Confidentiality, Integrity, and Availability
Main components of network security.
Confidentiality
Preserving authorized restrictions on information access and disclosure, including means for protecting personal privacy and proprietary information.
Loss of confidentiality is the unauthorized disclosure of information.
Integrity
Guarding against improper information modification or destruction.
Including ensuring information non-repudiation and authenticity.
Integrity loss is the unauthorized modification or destruction of information.
Availability
Timely and reliable access to information.
Loss of availability is the disruption of access to an information system.
Authenticity and Accountability
Authenticity: property of being genuine and verifiable.
“Only who has the rights to access or utilize the resources can use them.”
Access control models
MAC – Mandatory Access Control
Use labels to regulate the access
Military use
DAC – Discretionary Access Control
Each object (folder or file) has an owner and the owner defines the rights and privilege
Role Based Access Control
The rights are configured based on the user roles. For instance, sales group, management group, etc.
Other methods
Centralized
SSO (Single Sing On)
Provide the 3 As
Decentralized
Independent access control methods
Local power
Normally the military forces use these methods on the battlefields
Best practices for the access control field
These concepts are deeply integrated with the access control methodologies and must be followed by the organization in order of the policies and procedures.
Least privilege
Information access limit
Separation of duties
Verify employee activity
Rotation of duties
Tracking and control
Access Control – Physical and Logical
Physical access control methods
Perimetral
Building
Work areas
Servers and network
Technical uses of Physical security controls
ID badges
List and logs
Door access control systems
Tokens
Proximity sensors
Tramps
Physical block
Cameras
Logical access control methods
ACL (Routers)
GPO’S
Password policies
Device policies
Day and time restrictions
Accounts
Centralized
Decentralized
Expiration
BYOD, BYOC … BYO Everything…
Popular concepts for moderns times. Each collaborator has the opportunity to bring their own device to the work environment.
Some controls to follow:
Strict policy and understanding
Use of technical control MDM
Training
Strong perimetral controls
Monitoring the access control process
IDS/IPs
HOST IDS and IPS
Honeypot
Sniffers
Operating System Security Basics
User and Kernel Modes
MS Windows Components
User Mode and Kernel Mode
Drivers call routines that are exported by various kernel components.
Drivers must respond to specific calls from the OS and can respond to other system calls.
User Mode
When you start a user-mode application, Windows creates a process for the application.
Private virtual address space
Private handle table
Each application runs in isolation and if an application crashes, the crash is limited to that one application.
Kernel Mode
All code that runs in kernel mode shares a single virtual address space.
If a kernel-mode driver accidentally writes to the wrong virtual address, data that belongs to the OS or another driver could be compromised.
If a kernel-mode driver crashes, the entire OS crashes.
File System
Types of File Systems
NTS (New Technology File System)
Introduced in 1993
Most common file system for Windows end user systems
Most Windows servers use NTFS as well
FATxx (File Allocation Table)
Simple File system used since the 80s
Numbers preceding FAT refer to the number of bits used to enumerate a file system block. Ex FAT16, FAT32
Now mainly used for removable devices under 32 GB capacity.
(NOTE: FAT32 actually support upto ≤2TB storage size).
Directory Structure
Typical Windows Directory Structure
Shortcuts and Commands
Windows Shortcuts
Common tasks that can be accessed using the Windows or Ctrl Key and another Key.
Time saving and helpful for tasks done regularly.
Additional Shortcuts
F2: Rename
F5: Refresh
Win+L: Lock your computer
Win+I: Open Settings
Win+S: Search Windows
Win+PrtScn: Save a screenshot
Ctrl+Shift+Esc: Open the Task Manager
Win+C: Start talking to Cortana
Win+Ctrl+D: Add a new virtual desktop
Win+X: Open the hidden Menu
Linux Key Components
Key Components
Linux has two major components:
The Kernel
- It is the core of the OS. It interacts directly with the hardware.
- It manages system and user input/output. Processes, files, memory, and devices.
1) The Shell
- It is used to interact with the kernel.
- Users input commands through the shell and the kernel performs the commands.
Linux File Systems
File Systems
- represents file in CLI
d represents directory in CLI
Run Levels
Linux Basic Commands
cd: change directory
cp: copy files or dirs
mv: move file or dirs
ls: lists info related to files and dirs
df: display file system disk space
kill: stop an executing process
rm: delete file and dirs
rmdir: remove en empty dir
cat: to see the file contents, or concatenate multiple files together
mkdir: creates new dir
ifconfig: view or configure network interfaces
locate: quickly searches for the location of files. It uses an internal database that is updated using updatedb command.
tail: View the end of a text file, by default the last 10 lines
less: Very efficient while viewing huge log files as it doesn’t need to load the full file while opening
more: Displays text, one screen at a time
nano: a basic text editor
chmod: changes privileges for a file or dir
Permissions and Owners
File and directory permission
There are three groups that can ‘own’ a file.
User
group
everybody
For each group there are also three types of permissions: Read, Write, and Execute.
Read: 4(100), Write: 2(010), Execute: 1(001)
Change Permissions
You can use the chmod command to change the permissions of a file or dir:
chmod <permissions><filename>
chmod 755<filename>
chmod u=rw,g=r,o=r<filename>
Change owner
You can change the owner and group owner of a file with the chown command:
chown <user>:<group><filename>
macOS Security Overview
macOS Auditing
About My mac menu, contains information about
OS
Displays
Storage
Support
Service
Logs, etc.
Activity Monitor real-time view of system resource usage and relevant actions
Console, contains
Crash reports
Spin reports
Log reports
Diagnostic reports
Mac Analysis Data
System.log
macOS Security Settings
Various Security settings for macOS can be found in System Preferences app.
Genral Tab offers GateKeeper settings for installing apps from other AppStore, and few other settings.
FileVault Tab contains information about system and file encryption.
FireWall Tab for system level software firewall settings with basic and to advanced options.
Privacy Tab contains location services and other privacy related info and settings.
macOS Recovery
macOS comes with a hidden partition installed called macOS Recovery, it essentially replaces the installation discs that comes with new computers.
Access it by restarting your Mac while holding the R key.
It offers following tools/options:
Restore from the Time Machine Backup
Reinstall macOS
Get Help Online
Disk Utility
Virtualization Basics and Cloud Computing
An Overview of Virtualization
Allows you to create multiple simulated environments or dedicated resources from a single, physical hardware system.
Hypervisor/Host
Virtual Machine/Guest
Hypervisor
Separate the physical resources from the virtual environments
Hypervisors can sit on top of an OS (end user) or be installed directly onto hardware (enterprise).
Virtual Machine
The virtual machine functions as a single data file.
The hypervisor relays requests from the VM to the actual hardware, is necessary.
VMs doesn’t interact directly with the host machine.
Physical hardware is assigned to VMs.
Virtualization to Cloud
Cloud Deployments
Cloud Computing Reference Model
Cybersecurity Compliance Frameworks and System Administration
What Cybersecurity Challenges do Organizations Face?
Event, attacks, and incidents defied
Security Event
An event on a system or network detected by a security device or application.
Security attack
A security event that has been identified by correlation and analytics tools as malicious activity that attempting to collect, disrupt, deny, degrade, or destroy information system resources or the information itself.
Security Incident
An attack or security event that has been reviewed by security analysts and deemed worthy of deeper investigation.
Security – How to stop “bad guys”
Outsider
They want to “get-in” – steal data, steal compute time, disrupt legitimate use
Security baseline ensures we design secure offerings but setting implementation standards
E.g. Logging, encryption, development, practices, etc.
Validated through baseline reviews, threat models, penetration testing, etc.
Inadvertent Actor
They are “in” – but are human and make mistakes
Automate procedures to reduce error-technical controls
Operational/procedural manual process safeguards
Review logs/reports to find/fix errors. Test automation regularly for accuracy.
Malicious Insiders
They are “in” – but are deliberately behaving badly
Separation of duties – no shared IDs, limit privileged IDs
Designed protection from theft or damage, disruption or misdirection
Physical controls – for the servers in the data centers
Technical controls
Features and functions of the service (e.g., encryption)
What log data is collected?
Operational controls
How a server is configured, updated, monitored, and patched?
How staff are trained and what activities they perform?
Privacy
How information is used, who that information is shared with, or if the information is used to track users?
Compliance
Tests that security measures are in place.
Which and how many depend on the specific compliance.
It Will Often cover additional non-security requirements such as business practices, vendor agreements, organized controls etc.
Compliance: Specific Checklist of Security Controls, Validated
Compliance Basics
Foundational
General specifications, (not specific to any industry) important, but generally not legally required.
Ex: SOC, ISO.
Industry
Specific to an industry, or dealing with a specific type of data. Often legal requirements.
Ex: HIPAA, PCI DSS
Any typical compliance process
General process for any compliance/audit process
Scoping
“Controls” are based on the goal/compliance – 50–500.
Ensure all components in scope are compliant to technical controls.
Ensure all processes are compliant to operation controls.
Testing and auditing may be:
Internal/Self assessments
External Audit
Audit recertification schedules can be quarterly, bi-quarterly, annually, etc.
Overview of US Cybersecurity Federal Law
Computer Fraud and Abuse Act (CFAA)
Enacted in 1984
US Federal Laws
Federal Information Security Management Act of 2002 (FISMA)
Federal Information Security Modernization Act of 2014 (FISMA 2014)
FISMA assigns specific responsibilities to federal agencies, the National Institute of Standards and Technology (NIST) and the Office of Management and Budget (OMB) in order to strengthen information security systems.
National Institute of Standards and Technology (NIST) Overview
Cybersecurity and Privacy
NIST’s cybersecurity and privacy activities strengthen the security digital environment. NIST’s sustained outreach efforts support the effective application of standards and best practices, enabling the adoption of practical cybersecurity and privacy.
General Data Protection Regulation (GDPR) Overview
This is simply a standard for EU residence:
Compliance
Data Protection
Personal Data:
The GDPR cam into effect on 25 May 2018 and represents the biggest change in data privacy in two decades. The legislation aims to give control back to individuals located in EU over their Personal Data and simplify the regulatory environment for internation businesses.
5 Key GDPR Obligations:
Rights of EU Data subjects
Security of Personal Data
Consent
Accountability of Compliance
Data Protection by Design and by Default
Key terms for understanding
Internation Organization for Standardization (ISO) 2700x
The ISO 2700 family of standards help organization keep information assets secure.
ISO/IEC 27001 is the best-known standard in the family providing requirements for an information security management systems (ISMS).
The standard provides requirements for establishing, implementing, maintaining and continually improving an information security management system.
Also becoming more common,
ISO 270018 – Privacy
Other based on industry/application, e.g.,
ISO 270017 – Cloud Security
ISO 27001 Certification can provide credibility to a client of an organization.
For some industries, certification is a legal or contractual requirement.
ISO develops the standards but does not issue certifications.
Organizations that meet the requirements may be certified by an accredited certification body following successful completion of an audit.
System and Organization Controls Report (SOC) Overview
SOC Reports
Why SOC reports?
Some industry/jurisdictions require SOC2 or local compliance audit.
Many organizations who know compliance, know SOC Type 2 consider it a stronger statement of operational effectiveness than ISO 27001 (continuous testing).
Many organization’s clients will accept SOC2 in lieu of the right-to-audit.
Compared with ISO 27001
SOC1 vs SOC2 vs SOC3
SOC1
Used for situations where the systems are being used for financial reporting.
Also referenced as Statement on Standards for Attestation Engagements (SSAE)18 AT-C 320 (formerly SSAE 16 or AT 801).
SOC2
Addresses a service organization’s controls that are relevant to their operations and compliance, more generally than SOC1.
Restricted use report contains substantial detail on the system, security practices, testing methodology and results.
Also, SSAE 18 standards, sections AT-C 105 and AT-C 205.
SOC3
General use report to provide interested parties with a CPA’s opinion about same controls in SOC2.
Type 1 vs Type 2
Type 1 Report
Consider this the starting line.
The service auditor expresses an opinion on whether the description of the service organization’s systems is fairly presented and whether the controls included in the description are suitably designed to meet the applicable Trust Service criteria as of a point in time.
Type 2 Report
Proof you’re maintaining the effectiveness over time
Typically 6 month, renewed either every 6 months or yearly.
The service auditor’s report contains the same opinions expressed in a Type 1 report, but also includes an opinion on the operating effectiveness of the service organization’s controls for a period of time. Includes description of the service auditor’s tests of operation effectiveness and test results.
Selecting the appropriate report type
A type 1 is generally only issued if the service organization’s system has not been in operation for a significant period of time, has recently made significant system or control changes. Or if it is the first year of issuing the report.
SOC1 and SOC2, each available as Type 1 or Type 2.
Scoping Considerations – SOC 2 Principles
Report scope is defined based on the Trust Service Principles and can be expanded to additional subject.
SOC Reports – Auditor Process Overview
What are auditors looking for:
1)Accuracy → are controls results being assessed for pass/fail.
2)Completeness → do controls implementation cover the entire offering: e.g., no gaps in inventory, personnel, etc.
3)Timeliness → are controls performed on time (or early) with no gaps in coverage.
- If a control cannot be performed on time, are there appropriate assessment (risk) approvals BEFORE the control is considered ‘late’.
4)With Resilience notice → are there checks/balances in place such that if a control does fail, would you be able to correct at all? Within a reasonable timeframe?
5)Consistency → Shifting control implementation raises concerns about above, plus increases testing.
What does SOC1/SOC2 Test
General Controls:
Inventory listing
HR Employee Listing
Access group listing
Access transaction log
A: Organization and Management
Organizational Chart
Vendor Assessments
B: Communications
Customer Contracts
System Description
Policies and Technical Specifications
C: Risk Management and Design/Implementation of Controls
IT Risk Assessment
D: Monitoring of Controls
Compliance Testing
Firewall Monitoring
Intrusion Detection
Vulnerability Management
Access Monitoring
E: Logical and Physical Access Controls
Employment Verification
Continuous Business Need
F: System Operations
Incident Management
Security Incident Management
Customer Security Incident Management
Customer Security Incident Reporting
G: Change Management
Change Management
Communication of Changes
H: Availability
Capacity Management
Business Continuity
Backup or equivalent
Continuous Monitoring – Between audits
Purpose:
Ensure controls are operating as designed.
Identify control weaknesses and failure outside an audit setting.
Communicate results to appropriate stakeholders.
Scope:
All production devices
Controls will be tested for operating effectiveness over time, focusing on:
Execution against the defined security policies.
Execution evidence maintenance/availability
Timely deviation from policy documentation.
Timely temporary failures of a control or loss of evidence documentation and communication.
Industry Standards
Health Insurance Portability and Accountability Act (HIPAA)
Healthcare organizations use cloud services to achieve more than saving and scalability:
Foster virtual collaboration across care environments
Leverage full potential of existing patient data
Address challenges in analyzing patient needs
Provide platforms for care innovation
Expand delivery network
Reduce response time in the case of emergencies
Integrate data silos and optimizes information flow
Increase resource utilization
Simplify processes, reducing administration cost
What is HIPAA-HITECH
The US Federal laws and regulations that define the control of most personal healthcare information (PHI) for companies responsible for managing such data are:
Health insurance Portability and Accountability Act (HIPAA)
Health Information Technology for Economic Clinical Health Act (HITECH)
The HIPAA Privacy Rule establishes standards to protect individuals’ medical records and other personal health information and applies to health plans, health care clearinghouses, and those health care providers who conduct certain health care transactions electronically.
The HIPAA Security Rule establishes a set of security standards for protecting certain health information that is held or transferred in electronic form. The Security Rule operationalizes the protections contained in the Privacy Rule by addressing the technical and non-technical safeguards that must be put in place to secure individuals’ “electronic protected health information” (e-PHI)
HIPAA Definitions
U.S. Department of Health and Human Services (HHS) Office of Civil Rights (OCR):
Governing entity for HIPAA.
Covered Entity:
HHS-OCR define companies that manage healthcare data for their customers as a Covered Entity.
Business Associate:
Any vendor company that supports the Covered Entity.
Protected Health Information (PHI):
Any information about health status, provision of health care, or payment for health care that is maintained by a Covered Entity (or a Business Associate of a Covered Entity), and can be linked to a specific individual.
HHS-OCR “Wall of Shame”:
Breach Portal: Notice to the Secretary of HHS Breach of Unsecured Protected Health Information.
Why is Compliance Essential?
U.S. Law states that all individuals have the right to expect that their private health information be kept private and only be used to help assure their health.
There are significant enforcement penalties if a Covered Entity / Business Associate is found in violation.
HHS-OCR can do unannounced audits on the (CE+BA) or just the BA.
HIPAA is a U.S. Regulation, so be aware…
Other countries have similar regulations / laws:
Canada – Personal Information Protection and Electronic Documents Act
European Union (EU) Data Protection Directive (GDPR)
Many US states address patient privacy issues and are stricter than those set forth in HIPAA and therefore supersedes the US regulations.
Some international companies will require HIPAA compliance for an either a measure of confidence, or because they intend to do business with US data.
HIPAA Security Rule
The Security Rule requires, covered entities to maintain reasonable and appropriate administrative, technical, and physical safeguards for protecting “electronic protected health information” (e-PHI).
Specifically, covered entities must:
Ensure the confidentiality, integrity, and availability of all e-PHI they create, receive, maintain or transmit.
Identify and protect against reasonably anticipated threats to the security or integrity of the information.
Protect against reasonably anticipated, impermissible uses or disclosures; and
ensure compliance by their workforce.
Administrative Safeguards
The Administrative Safeguards provision in the Security Rule require covered entities to perform risk analysis as part of their security management processes.
Administrative Safeguards include:
Security Management Process
Security Personnel
Information Access Management
Workforce Training and Management
Evaluation
Technical Safeguards
Technical Safeguards include:
Access Control
Audit Controls
Integrity Controls
Transmission Security
Physical Safeguards
Physical Safeguards include:
Facility Access and Control
Workstation and Device Security
Payment Card Industry Data Security Standard (PCI DSS)
The PCI Data Security Standard
The PCI DSS was introduced in 2004, by American Express, Discover, MasterCard and Visa in response to security breaches and financial losses within the credit card industry.
Since 2006 the standard has been evolved and maintained by the PCI Security Standards Council, a “global organization, (it) maintains, evolves and promotes Payment Card Industry Standards for the safety of cardholder data across the globe.”
The PCI Security Standards Council is now comprised of American Express, Discover, JCB International MasterCard and Visa Inc.
Applies to all entities that store, process, and/or transmit cardholder data.
Covers technical and operational practices for system components included in or connected to environments with cardholder data.
PCI DSS 3.2 includes a total of 264 requirements grouped under 12 main requirements.
Goals and Requirements
PCI DSS 3.2 includes a total of 264 requirements grouped under 12 main requirements:
Scope
The Cardholder Data Environment (CDE): People, processes and technology that store, process or transmit cardholder data or sensitive authentication data.
Cardholder Data:
Primary Account Number (PAN)
PAN plus any of the following:
Cardholder name
expiration date and/or service mode.
Sensitive Authentication Data:
Security-related information (including but not limited to card validation codes/values, full track data (from the magnetic stripe or equivalent on a chip), PINs, and PIN blocks) used to authenticate cardholder and/or authorize payment card transactions.
Sensitive Areas:
Anything that accepts, processes, transmits or stores cardholder data.
Anything that houses systems that contain cardholder data.
Determining Scope
People
Processes
Technologies
Compliance Personnel
IT Governance
Internal Network Segmentation
Human Resources
Audit Logging
Cloud Application platform containers
IT Personnel
File Integrity Monitoring
Developers
Access Management
Virtual LAN
System Admins and Architecture
Patching
Network Admins
Network Device Management
Security Personnel
Security Assessments
Anti-Virus
PCI Requirements
Highlight New and Key requirements:
Approved Scanning Vendor (ASV) scans (quarterly, external, third party).
Use PCI scan policy in Nessus for internal vulnerability scans.
File Integrity Monitoring (FIM)
Firewall review frequency every 6 months
Automated logoff of idle session after 15 minutes
Responsibility Matrix
Critical Security Controls
Center for Internet Security (CIS) Critical Security Controls
CIS Critical Security Controls
The CIS ControlsTM are a prioritized set of actions that collectively form a defense-in-depth set of best practices that mitigate the most common attacks against systems and networks.
The CIS ControlsTM are developed by a community of IT experts who apply their first-hand experience as cyber defenders to create these globally accepted security best practices.
The experts who develop the CIS Controls come from a wide range of sectors including retail, manufacturing, healthcare, education, government, defense, and others.
CIS ControlTM 7
CIS ControlTM 7.1 Implementation Groups
Structure of the CIS ControlTM 7.1
The presentation of each Control in this document includes the following elements:
A description of the importance of the CIS Control (Why is this control critical?) in blocking or identifying the presence of attacks, and an explanation of how attackers actively exploit the absence of this Control.
A table of the specific actions (“Sub-Controls”) that organizations should take to implement the Control.
Procedures and Tools that enable implementation and automation.
Sample Entity Relationship Diagrams that show components of implementation.
Compliance Summary
Client System Administration Endpoint Protection and Patching
Client System Administration
“The client-server model describes how a server provides resources and services to one or more clients. Examples of servers include web servers, mail servers, and file servers. Each of these servers provide resources to client devices, such as desktop computers, laptops, tablets, and smartphones. Most servers have a one-to-many relationship with clients, meaning a single server can provide resources to multiple clients at one time.”
Client System Administration
Cloud and Mobile computing
New Devices, new applications and new services.
Endpoint devices are the front line of attack.
Common type of Endpoint Attacks
Spear Phishing/Whale Hunting – An email imitating a trusted source designed to target a specific person or department.
Watering Hole – Malware placed on a site frequently visited by an employee or group of employees.
**Ad Network Attacks – Using ad networks to place malware on a machine through ad software.
Island Hopping – Supply chain infiltration.
Endpoint Protection
Basics of Endpoint Protection
Endpoint protection management is a policy-based approach to network security that requires endpoint devices to comply with specific criteria before they are granted access to network resources.
Endpoint security management systems, which can be purchased as software or as a dedicated appliance, discover, manage and control computing devices that request access to the corporate network.
Endpoint security systems work on a client/server model in which a centrally managed server or gateway hosts the security program and an accompanying client program is installed on each network devices.
Unified Endpoint Management
A UEM platform is one that converges client-based management techniques with Mobile device management (MDM) application programming interfaces (APIs).
Endpoint Detection and Response
Key mitigation capabilities for endpoints
Deployment of devices with network configurations
Automatic quarantine/blocking of non-compliant endpoints
Ability to patch thousands of endpoints at once
Endpoint Detection and Response
Automatic policy creation for endpoints
Zero-day OS updates
Continuous monitoring, patching, and enforcement of security policies across endpoints.
Examining an Endpoint Security Solution
Three key factors to consider:
Threat hunting
Detection response
User education
An Example of Endpoint Protection
Unified Endpoint Management
UEM is the first step to enable today’s enterprise ecosystem:
Devices and things
Apps and content
People and identity
What is management without insight?
IT and security needs to understand:
What happened
What can happen
What should be done
… in the context of their environment
Take a new approach to UEM
UEM with AI
Traditional Client Management Systems
Involves an agent-based approach
Great for maintenance and support
Standardized rinse and repeat process
Applicable for some OS & servers
Mobile Device Management
API-based management techniques
Security and management of corporate mobile assets
Specialized for over-the-air configuration
Purpose-built for smartphones and tablets
Modern Unified Endpoint Management
IT Teams are also converging:
Overview of Patching
All OS require some type of patching.
Patching is the fundamental and most important thing an organization can do to prevent malicious attacks.
What is a patch?
A patch is a set of changes to a computer program or its supporting data designed to update, fix, or improve it. This includes fixing security vulnerabilities and other bugs, with such patches usually being called bugfixes, or bug fixes, and improving the functionality, usability or performance.
Windows Patching
Windows Updates allow for fixes to known flaws in Microsoft products and OS. The fixes, known as patches, are modification to software and hardware to help improve performance, reliability, and security.
Microsoft releases patches in a monthly cycle, commonly referred to as “Patch Tuesday”, the second Tuesday of every month.
Four types of Updates for Windows OSes
Security Updates: Security updates for Windows work to protect against new and ongoing threats. They are classified as Critical, Important, Moderate, Low, or non-rated.
590344 These are high priority updates. When these are released, they need to updated asap. It is recommended to have these set as automatic.
Software Updates: Software updates are not critical. They often expand features and improve the reliability of the software.
Service Packs: These are roll-ups, or a compilation, of all previous updates to ensure that you are up-to-date on all the patches since the release of the product up to a particular data. If your system is behind on updates, then service packs bring your system up-to-update.
Windows Application Patching
Why patch 3rd party applications in addition to Windows OS?
Unpatched software, especially if a widely used app like Adobe Flash or Browser, can be a magnet for malware and viruses.
87% of the vulnerabilities found in the top 50 programs affected third-party programs such as Adobe Flash and Reader, Java, Skype, Various Media Players, and others outside the Microsoft Ecosystem. That means the remaining 13 percent “stem from OSes and Microsoft Programs,” according to Secunia’s Vulnerability Review report.
Patching Process
Server and User Administration
Introduction to Windows Administration
User and Kernel Modes
MS Windows Components:
User Mode
Private Virtual address space
Private handle table
Application isolation
Kernel Mode
Single Virtual Address, shared by other kernel processes
File Systems
Types of file systems in Windows
NTFS (New Technology File system)
FATxx (File Allocation Table)
FAT16, FAT32
Typical Windows Directory Structure
Role-Based Access Control and Permissions
Access Control Lists (ACLs)
Principle of the least privileges
Privileged Accounts
Privileged accounts like admins of Windows services have direct or indirect access to most or all assets in an IT organization.
Admins will configure Windows to manage access control to provide security for multiple roles and uses.
Access Control
Key concepts that make up access control are:
Permissions
Ownership of objects
Inheritance of permissions
User rights
Object auditing
Local User Accounts
Default local user accounts:
Administrator account
Guest account
HelpAssistant account
DefaultAccount
Default local system accounts:
SYSTEM
Network Service
Local Service
Management of Local Users accounts and Security Considerations
Restrict and protect local accounts with administrative rights
Enforce local account restrictions for remote access
Deny network logon to all local Administrator accounts
Create unique passwords for local accounts with administrative rights
What is AD?
Active Directory Domain Services (AD DS) stores information about objects on the network and makes this information easy for administrators and users to find and use.
Servers
Volumes
Printers
Network user and computer accounts
Security is integrated with AD through authentication and access control to objects in the directory via policy-based administration.
Features of AD DS
A set of rules, the schema
A global catalog
A query and index mechanism
A replication service
Active Directory Accounts and Security Considerations
AD Accounts
Default local accounts in AD:
Administrator account
Guest Account
HelpAssistant Account
KRBTGT account (system account)
Settings for default local accounts in AD
Manage default local accounts in AD
Secure and Manage domain controllers
Restrict and Protect sensitive domain accounts
Separate admin accounts from user accounts
Privileged accounts: Allocate admin accounts to perform the following
Minimum: Create separate accounts for domain admins, enterprise admins, or the equivalent with appropriate admin.
Better: Create separate accounts for admins that have reduced admin rights, such as accounts for workstation admins, account with user rights over designated AD organizational units (OUs)
Ideal: Create multiples, separate accounts for an administrator who has a variety of job responsibilities that require different trust levels
Standard User account: Grant standard user rights for standard user tasks, such as email, web browsing, and using line-of-business (LOB) applications.
Create dedicated workstation hosts without Internet and email access
Admins need to manage job responsibilities that require sensitive admin rights from a dedicated workstation because they don’t have easy physical access to the servers.
Minimum: Build dedicated admin workstations and block Internet Access on those workstations, including web browsing and email.
Better: Don’t grant admins membership in the local admin group on the computer in order to restrict the admin from bypassing these protections.
Ideal: Restrict workstations from having any network connectivity, except for the domain controllers and servers that the administrator accounts are used to manage.
Restrict administrator logon access to servers and workstations
It is a best practice to restrict admins from using sensitive admin accounts to sign-in to lower-trust servers and workstations.
Restrict logon access to lower-trust servers and workstations by using the following guidelines:
Minimum: Restrict domain admins from having logon access to servers and workstations. Before starting this procedure, identify all OUs in the domain that contain workstations and servers. Any computers in OUs that are not identified will not restrict admins with sensitive accounts from signing in to them.
Better: Restrict domain admins from non-domain controller servers and workstations.
Ideal: Restrict server admins from signing in to workstations, in addition to domain admins.
Disable the account delegation right for administrator accounts
Although user accounts are not marked for delegation by default, accounts in an AD domain can be trusted for delegation. This means that a service or a computer that is trusted for delegation can impersonate an account that authenticates to the to access other resources across the network.
It is a best practice to configure the user objects for all sensitive accounts in AD by selecting the Account is sensitive and cannot be delegated check box under Account options to prevent accounts from being delegated.
Overview of Server Management with Windows Admin Center
Active Directory Groups
Security groups are used to collect user accounts, computer accounts, and other groups into manageable units.
For AD, there are two types of admin responsibilities:
Server Admins
Data Admins
There are two types of groups in AD:
Distribution groups: Used to create email distribution lists.
Security groups: Used to assign permissions to shared resources.
Groups scope
Groups are characterized by a scope that identifies the extent to which the group is applied in the domain tree or forest.
The following three group scopes are defined by AD:
Universal
Global
Domain Local
Default groups, such as the Domain Admins group, are security groups that are created automatically when you create an AD domain. You can use these predefined groups to help control access to shared resources and to delegate specific domain-wide admin roles.
What is Windows Admin Center?
Windows Admin Center is a new, locally-deployed, browser-based management tool set that lets you manage your Windows Servers with no cloud dependency.
Windows Admin Center gives you full control over all aspects of your server infrastructure and is useful for managing servers on private networks that not connected to the Internet.
Kerberos Authentication and Logs
Kerberos Authentication
Kerberos is an authentication protocol that is used to verify the identity of a user or host.
The Kerberos Key Distribution Center (KDC) is integrated with other Windows Server security services and uses the domain’s AD DS database.
The key Benefits of using Kerberos include:
Delegated authentication
Single sign on
Interoperability
More efficient authentication to servers
Mutual authentication
Windows Server Logs
Windows Event Log, the most common location for logs on Windows.
Windows displays its event logs in the Windows Event Viewer. This application lets you view and navigate the Windows Event Log, search, and filter on particular types of logs, export them for analysis, and more.
Windows Auditing Overview
Audit Policy
Establishing audit policy is an important facet of security. Monitoring the creation o modification of objects gives you a way to track potential security problems, helps to ensure user accountability, and provides evidence in the event of a security breach.
There are nine different kinds of events you can audit. If you audit any of those kinds of events, Windows records the events in the Security log, which you can find in the Event Viewer.
Account logon Events
Account Management
Directory service Access
Logon Events
Object access
Policy change
Privilege use
Process tracking
System events
Linux Components: Common Shells
Bash:
The GNU Bourne Again Shell (BASH) is based on the earlier Bourne Again shell for UNIX. On Linux, bash is the most common default shell for user accounts.
Sh:
The Bourne Shell upon which bash is based goes by the name sh. It’s not often used on Linux, often a pointer to the bash shell or other shells.
Tcsh:
This shell is based on the earlier C shell (CSH). Fairly popular, but no major Linux distributions make it the default shell. You don’t assign environment variables the same way in TCSH as in bash.
CSH:
The original C shell isn’t used much on Linux, but if a user is familiar with CSH, TCSh makes a good substitute.
Ksh:
The Korn shell (ksh) was designed to take the best features of the Bourne shell and the C shell and extend them. It has a small but dedicated following among Linux users.
ZSH:
The Z shell (zsh) takes shell evolution further than the Korn shell, incorporating features from earlier shells and adding still more.
Linux Internal and External Commands
Internal Commands:
Built into the shell program and are shell dependent. Also called built-in commands.
Determine if a command is a built-in command by using the type command.
External commands:
Commands that the system offers, are totally shell-independent and usually can be found in any Linux distribution
They mostly reside in /bin and /usr/bin.
Shell command Tricks:
Command completion: Type part of a command or a filename (as an option to the command), and then press TAB key.
Use Ctrl+A or Ctrl+E: To move the cursor to the start or end of the line, respectively.
Samba
Samba is an Open Source/Free software suite that provides seamless file and print services. It uses the TCP/IP protocol that is installed on the host server.
When correctly configured, it allows that host to interact with an MS Windows client or server as if it is a Windows file and print server, so it allows for interoperability between Linux/Unix servers and Windows-based clients.
Cryptography and Compliance Pitfalls
Cryptography Terminology
Encryption only provides confidentiality, but no integrity.
Data can be encrypted
At rest
In use
In transit
Common types of encryption algorithms
Symmetric Key (AES, DES, IDEA, …)
Public key (RSA, Elliptic Curve, DH, …)
Hash Function
Maps data of arbitrary size to data of a fixed size.
Provides integrity, but not confidentiality
MD5, SHA-1, SHA-2, SHA-3, and others
Original data deliberately hard to reconstruct
Used for integrity checking and sensitive data storage (e.g., passwords)
Digital Signature
“A mathematical scheme for verifying the authenticity of digital messages and documents.”
Uses hashing and public key encryption
ensures authentication, non-repudiation, and integrity.
Common Cryptography Pitfalls
Pitfall: Missing Encryption of Data and Communication
Products handle sensitive business and personal data.
Data is often the most valuable asset that the business has.
When you store or transmit it in clear text, it can be easily leaked or stolen.
In this day and age, there is no excuse for not encrypting data that’s stored or transmitted.
We have the cryptographic technology that is mature, tested, and is available for all environments and programming languages.
Encrypt all sensitive data you are handling (and also ensure its integrity).
Pitfall: Missing Encryption of Data and Communication
Some products owners that we talk to don’t encrypt stored data because “users don’t have access to the file system.”
There are plenty of vulnerabilities out there that may allow exposure of files stored on the file system.
The physical machine running the application maybe stolen, the hard disk can be then accessed directly.
You have to assume that the files containing sensitive information may be exposed and analyzed.
Pitfall: Implementing Your Own Crypto
Often developers use Base64 encoding, simple xor encoding, and similar obfuscation schemes.
Also, occasionally we see products implement their own cryptographic algorithms.
Please don’t do that!
Schneier’s Law:
Anyone, from the most clueless amateur to the best cryptographer, can create an algorithm that he himself can’t break. It’s not even hard. What is hard is creating an algorithm that no one else can break, even after years of analysis.
Rely on proven cryptography, that was scrutinized by thousands of mathematicians and cryptographers.
Follow recommendations of NIST.
Pitfall: Relying on Algorithms Being Secret
We sometimes hear dev teams tell us that “the attacker will never know our internal algorithms.”
Bad news – they can and will be discovered; it’s only a question of motivation.
A whole branch of hacking – Reverse Engineering – is devoted to discovering hidden algorithms and data.
Even if your application is shipped only in compiled form, it can be “decompiled”.
Attackers may analyze trial/free versions of the product, or get copies on the Dark Web.
“Security by obscurity” is not a good defense mechanism.
The contrary is proven true all the time.
All algorithms that keep us safe today are open source and very well-studied: AES, RSA, SHA*, ….
Always assume that your algorithms will be known to the adversary.
A great guiding rule is Kerckhoffs’s Principle:
A cryptosystem should be secure even if everything about the system, except the key, is public knowledge.
Pitfall: Using Hard-coded/Predictable/Weak Keys
Not safeguarding your keys renders crypto mechanisms useless.
When the passwords and keys are hard-coded in the product or stored in plaintext in the config file, they can easily be discovered by an attacker.
An easily guessed key can be found by trying commonly used passwords.
When keys are generated randomly, they have to be generated from a cryptographically-secure source of randomness, not the regular RNG.
Rely on hard to guess, randomly generated keys and passwords that are stored securely.
Calls encryption algorithms in another library or component.
Directs encryption functionality in another product.
… must be classified for export before being released.
Data Encryption
Encryption Data at rest
The rule of thumb is to encrypt all sensitive data at rest: in files, config files, databases, backups.
Symmetric key encryption is most commonly used.
Follow NIST Guidelines for selecting an appropriate algorithm – currently it’s AES (with CBC mode) and Triple DES.
Pitfalls and Recommendations
Some algorithms are outdated and no longer considered secure – phase them out
examples include DES, RC4, and others.
Using hard-coded/easily guessed/insufficiently random keys – Select cryptographically-random keys, don’t reuse keys for different installations.
Storing keys in clear text in proximity to data they protect (“key under the doormat”)
stores keys in secure key stores.
Using initialization vectors (IVs) incorrectly.
Use a new random IV every time.
Preferable to select the biggest key size you can handle (but watch out for export restrictions).
Encryption Data in Use
Unfortunately, a rarely-followed practice.
Important, nonetheless, memory could be leaked by an attacker.
A famous 2014 Heartbleed defect leaked memory of processes that used OpenSSL.
The idea is to keep data encrypted up until it must be used.
Decrypt data as needed, and then promptly erase it in memory after use.
Keep all sensitive data (data, keys, passwords) encrypted except a brief moment of use.
Consider Homomorphic encryption if it can be applied to your application.
Encryption Data in Transit
In this day and age, there is no excuse for communicating in cleartext.
There is an industry consensus about it; Firefox and Chrome now mark HTTP sites as insecure.
Attackers can easily snoop on unprotected communication.
All communications (not just HTTP) should be encrypted, including: RPCs, database connections, and others.
TLS/SSL is the most commonly used protocol.
Public key crypto (e.g., RSA, DH) for authentication and key exchange; Symmetric Key crypto to encrypt the data.
Server Digital Certificate references certificate authority (CA) and the public key.
Sometimes just symmetric key encryption is employed (but requires pre-sharing of keys).
Pitfalls
Using self-signed certificates
Less problematic for internal communications, but still dangerous.
Use properly generated certificates verified by established CA.
Accepting arbitrary certificates
Attacker can issue their own certificate and snoop on communications (MitM attacks).
Don’t accept arbitrary certificates without verification.
Not using certificate pinning
Attacker may present a properly generated certificate and still snoop on communications.
Certificate pinning can help – a presented certificate is checked against a set of expected certificates.
Using outdated versions of the protocol or insecure cipher suites
Old versions of SSL/TLS are vulnerable. (DROWN, POODLE, BEAST, CRIME, BREACH, and other attacks)
TLS v1.1-v1.3 are safe to use (v1.2 is recommended, with v1.3 coming)
Review your TLS support; there are tools that can help you:
Nessus, Qualys SSL Server Test (external only), sslscan, sslyze.
Allowing TLS downgrade to insecure versions, or even to HTTP
Lock down the versions of TLS that you support and don’t allow downgrade; disable HTTP support altogether.
Not safeguarding private keys
Don’t share private keys between different customers, store them in secure key stores.
Consider implementing Forward Secrecy
Some cipher suites protect past sessions against future compromises of secret keys or passwords.
Don’t use compression under TLS
CRIME/BREACH attacks showed that using compression with TLS for changing resources may lead to sensitive data exposure.
Implement HTTP Strict Transport Security (HSTS)
Implement Strict-Transport-Security header on all communications.
Stay informed of latest security news
A protocol or cipher suite that is secure today may be broken in the future.
Hashing Considerations
Hashing
Hashing is used for a variety of purposes:
Validating passwords (salted hashes)
Verifying data/code integrity (messages authentication codes and keyed hashes)
Verifying data/code integrity and authenticity (digital signatures)
Use secure hash functions (follow NIST recommendations):
SHA-2 (SHA-256, SHA-384, SHA-512, etc.) and SHA-3
Pitfalls: Using Weak or Obsolete Functions
There are obsolete and broken functions that we still frequently see in the code – phase them out.
Hash functions for which it is practical to generate collisions (two or more different inputs that correspond to the same hash value) are not considered robust.
MD5 has been known to be broken for more than 10 years, collisions are fairly easily generated.
SHA-1 was recently proven to be unreliable.
Using predictable plaintext
Not quite a cryptography problem, but when the plaintext is predictable it can be discovered through brute forcing.
Using unsalted hashes when validating passwords
Even for large issue spaces, rainbow tables can be used to crack hashes.
When salt is added to the plaintext, the resulting hash is completely different, and rainbow tables will no longer help.
Additional Considerations
Use key stretching functions (e.g., PBKDF2) with numerous iterations.
Key stretching functions are deliberately slow (controlled by number of iterations) in order to make brute forcing attacks impractical, both online and offline (aim 750ms to complete the operation).
Future-proof your hashes – include an algorithm identifier, so you can seamlessly upgrade in the future if the current algorithm becomes obsolete.
Message Authentication Codes (MACs)
MACs confirm that the data block came from the stated sender and hasn’t been changed.
Hash-based MACs (HMACs) are based on crypto hash functions (e.g., HMAC-SHA256 or HMAC-SHA3).
They generate a hash of the message with the help of the secret key.
If the key isn’t known, the attacker can’t alter the message and be able to generate another valid HMAC.
HMACs help when data may be maliciously altered while under temporary attacker’s control (e.g., cookies, or transmitted messages).
Even encrypted data should be protected by HMACs (to avoid bit-flipping attacks).
Digital Signatures
Digital signatures ensure that messages and documents come from an authentic source and were not maliciously modified in transit.
Some recommended uses of digital signatures include verifying integrity of:
Data exchanged between nodes in the product.
Code transmitted over network for execution at client side (e.g., JavaScript).
Service and fix packs installed by customer.
Data temporarily saved to customer machine (e.g., backups).
Digital signatures must be verified to be useful.
Safeguarding Encryption Keys
Encryption is futile if the encryption keys aren’t safeguarded.
Don’t store them in your code, in plaintext config files, in databases.
Proper way to store keys and certificates is in secure cryptographic storage, e.g, keystores
For examples, in Java you can use Java Key Store (JKS).
There is a tricky problem of securing key encrypting key (KEK).
This is a key that is used to encrypt the keystore. But how do we secure it?
Securing KEK
Use hardware secure modules (HSM).
Use Virtual HSM (Unbound vHSM).
Derive KEK for user-entered password.
An example of this can be seen in Symantec Encryption Desktop Software, securing our laptops.
Derive KEK from data unique to the machine the product is running on.
This could be file system metadata (random file names, file timestamps).
An attacker that downloads the database or the keystore will not be able to as easily obtain this information.
Impact of Quantum Computing
Quantum computing is computing using quantum-mechanical phenomena. Quantum computing may negatively affect cryptographic algorithms we employ today.
We are still 10–15 years away from quantum computing having an effect on cryptography.
Risks to existing cryptography:
Symmetric encryption (e.g., AES) will be weakened.
To maintain current levels of security, double the encryption key size (e.g., got from 128-bit to 256-bit keys).
Public key encryption that relies on prime number factorization (e.g., RSA used in SSL/TLS, blockchain, digital signatures) will be broken.
Plan on switching to quantum-resistant algorithms – e.g., Lattice-based Cryptography, Homomorphic Encryption.
Attacker can capture conversations now and decrypt them when quantum computing becomes available.
General Good practice – make your encryption, hash, signing algorithms “replaceable”, so that you could exchange them for something more robust if a weakness is discovered.
Subsections of Network Security and Database Vulnerabilities
Introduction to the TCP/IP Protocol Framework
Stateless Inspection
Stateless means that each packet is inspected one at a time with no knowledge of the previous packets.
Stateless Inspection Use Cases
To protect routing engine resources.
To control traffic going in or your organization.
For troubleshooting purposes.
To control traffic routing (through the use of routing instances).
To perform QoS/CoS (marking the traffic).
Stateful Inspection
A stateful inspection means that each packet is inspected with knowledge of all the packets that have been sent or received from the same session.
A session consists of all the packets exchanged between parties during an exchange.
What if we have both types of inspection?
Firewall Filters – IDS and IPS System
Firewall Filter (ACLs) / Security Policies Demo…
IDS
An Intrusion Detection System (IDS) is a network security technology originally built for detecting vulnerability exploits against a target application or computer.
By default, the IDS is a listen-only device.
The IDS monitor traffic and reports its results to an administrator.
Cannot automatically take action to prevent a detected exploit from taking over the system.
Basics of an Intrusion Prevention System (IPS)
An IPS is a network security/threat prevention technology that examines network traffic flows to detect and prevent vulnerability exploits.
The IPS often sites directly behind the firewall, and it provides a complementary layer of analysis that negatively selects for dangerous content.
Unlike the IDS – which is a passive system that scans traffic and reports back on threats – the IPS is placed inline (in the direct communication path between source and destination), actively analyzing and taking automated actions on all traffic flows that enter the network.
How does it detect a threat?
The Difference between IDS and IPS Systems
Network Address Translation (NAT)
Method of remapping one IP address space into another by modifying network address information in Internet Protocol (IP) datagram packet headers, while they are in transit across a traffic routing device.
Gives you an additional layer of security.
Allows the IP network of an organization to appear from the outside to use a different IP address space than what it is actually using. Thus, NAT allows an organization with non-globally routable addresses to connect to the Internet by translating those addresses into a globally routable addresses space.
It has become a popular and essential tool in conserving global address space allocations in face of IPv4 address exhaustion by sharing one Internet-routable IP address of a NAT gateway for an entire private network.
Types of NAT
Static Address translation (static NAT): Allows one-to-one mapping between local and global addresses.
Dynamic Address Translation (dynamic NAT): Maps unregistered IP addresses to registered IP addresses from a pool of registered IP addresses.
Overloading: Maps multiple unregistered IP addresses to a single registered IP address (many to one) using different ports. This method is also known as Port Address Translation (PAT). By using overloading, thousands of users can be connected to the Internet by using only one real global IP address.
Network Protocols over Ethernet and Local Area Networks
An Introduction to Local Area Networks
Network Addressing
Layer 3 or network layer adds an address to the data as it flows down the stack; then layer 2 or the data link layer adds another address to the data.
Introduction to Ethernet Networks
For a LAN to function, we need:
Connectivity between devices
A set of rules controlling the communication
The most common set of rules is called Ethernet.
To send a packet from one host to another host within the same network, we need to know the MAC address, as well as the IP address of the destination device.
Ethernet and LAN – Ethernet Operations
How do devices know when the data if for them?
Destination Layer 2 address: MAC address of the device that will receive the frame.
Source Layer 2 address: MAC address of the device sending the frame.
Types: Indicates the layer 3 protocol that is being transported on the frame such as IPv4, IPv6, Apple Tall, etc.
Data: Contains original data as well as the headers added during the encapsulation process.
Checksum: This contains a Cyclic Redundancy Check to check if there are errors on the data.
MAC Address
A MAC address is a 48-bits address that uniquely identifies a device’s NIC. The first 3 bytes are for the OUI and the last 3 bytes are reserved to identify each NIC.
Preamble and delimiter (SFD)
Preamble and delimiter (SFD) are 7 byte fields in an Ethernet frame. Preamble informs the receiving system that a frame is starting and enables synchronization, while SFD (Start Frame Delimiter) signifies that the Destination MAC address field begin with the next byte.
What if I need to send data to multiple devices?
Ethernet and LAN – Network Devices
Twisted Pair Cabling
Repeater
Regenerates electrical signals.
Connects 2 or more separate physical cables.
Physical layer device.
Repeater has no mechanism to check for collision.
Bridge
Ethernet bridges have 3 main functions:
Forwarding frames
Learning MAC addresses
Controlling traffic
Difference between a Bridge and a Switch
VLANs provide a way to separate LANs on the same switch.
Devices in one VLAN don’t receive broadcast from devices that are on another VLAN.
Limitations of Switches:
Network loops are still a problem.
Might not improve performance with multicast and broadcast traffic.
Can’t connect geographically dispersed networks.
Basics of Routing and Switching, Network Packets and Structures
Layer 2 and Layer 3 Network Addressing
Address Resolution Protocol (ARP)
The process of using layer 3 addresses to determine layer 2 addresses is called ARP or Address Resolution Protocol.
Routers and Routing Tables
Routing Action
Basics of IP Addressing and the OSI Model
IP Addressing – The Basics of Binary
IP Address Structure and Network Classes
IP Protocol
IPv4 is a 32 bits address divided into four octets.
From 0.0.0.0 to 255.255.255.255
IPv4 has 4,294,967,296 possible addresses in its address space.
Classful Addressing
When the Internet’s address structure was originally defined, every unicast IP address had a network portion, to identify the network on which the interface using the IP address was to be found, and a host portion, used to identify the particular host on the network given in the network portion.
The partitioning of the address space involved five classes. Each class represented a different trade-off in the number of bits of a 32-bit IPv4 address devoted to the network numbers vs. the number of bits devoted to the host number.
IP Protocol and Traffic Routing
IP Protocol (Internet Protocol)
Layer 3 devices use the IP address to identify the destination of the traffic, also devices like stateful firewalls use it to identify where traffic has come from.
IP addresses are represented in quad dotted notation, for example, 10.195.121.10.
Each of the numbers is a non-negative integer from 0 to 255 and represents one-quarter of the whole IP address.
A routable protocol is a protocol whose packets may leave your network, pass through your router, and be delivered to a remote network.
IP Protocol Header
IPv4 vs. IPv6 Header
Network Mask
The subnet mask is an assignment of bits used by a host or router to determine how the network and subnetwork information is partitioned from the host information in a corresponding IP address.
It is possible to use a shorthand format for expressing masks that simply gives the number of contiguous 1 bit in the mask (starting from the left). This format is now the most common format and is sometimes called the prefix length.
The number of bits occupied by the network portion.
Masks are used by routers and hosts to determine where the network/subnetwork portion of an IP address ends and the host part starts.
Broadcast Addresses
In each IPv4 subnet, a special address is reserved to be the subnet broadcast address. The subnet broadcast address is formed by setting the network/subnet portion of an IPv4 address to the appropriate value and all the bits in the Host portion to 1.
Introduction to the IPv6 Address Schema
IPv4 vs. IPv6
In IPv6, addresses are 128 bits in length, four times larger than IPv4 addresses.
An IPv6 address will no longer use four octets. The IPv6 address is divided into eight hexadecimal values (16 bits each) that are separated by a colon(:) as shown in the following examples:
65b3:b834:54a3:0000:0000:534e:0234:5332
The IPv6 address isn’t case-sensitive, and you don’t need to specify leading zeros in the address. Also, you can use a double colon(::) instead of a group of consecutive zeros when writing out the address.
0:0:0:0:0:0:0:1
::1
IPv4 Addressing Schemas
Unicast: Send information to one system. With the IP protocol, this is accomplished by sending data to the IP address of the intended destination system.
Broadcast: Sends information to all systems on the network. Data that is destined for all systems is sent by using the broadcast address for the network. An example of a broadcast address for a network is 192.168.2.2555. The broadcast address is determined by setting all hosts bits to 1 and then converting the octet to a decimal number.
Multicast: Sends information to a selected group of systems. Typically, this is accomplished by having the systems subscribe to a multicast address. Any data that is sent to the multicast address is then received by all systems subscribed to the address. Most multicast addresses start with 224.×.y.z and are considered class D addresses.
IPv6 Addressing Schemas
Unicast: A unicast address is used for one-on-one communication.
Multicast: A multicast address is used to send data to multiple systems at one time.
Anycast: Refers to a group of systems providing a service.
TCP/IP Layer 4 – Transport Layer Overview
Application and Transport Protocols – UDP and TCP
Transport Layer Protocol > UDP
UDP Header Fields
UDP Use Cases
Transport Layer Protocol > TCP
Transport Layer Protocol > TCP in Action
UDP vs TCP
Application Protocols – HTTP
Developed by Tim Berners-Lee.
HTTP works on a request response cycle; where the client returns a response.
It is made of 3 blocks known as the start-line header and body.
Not secure.
Application Protocols – HTTPS
Designed to increase privacy on the internet.
Make use of SSL certificates.
It is secured and encrypted.
TCP/IP Layer 5 – Application Layer Overview
DNS and DHCP
DNS
Domain Name System or DNS translates domains names into IP addresses.
DHCP
Syslog Message Logging Protocol
Syslog is standard for message logging. It allows separation of the software that generates messages, the system that stores them, and the software that report and analyze them. Each message is labeled with a facility code, indicating the software type generating the message, and assigned a severity label.
Used for:
System management
Security auditing
General informational analysis, and debugging messages
Used to convey event notification messages.
Provides a message format that allows vendor specific extensions to be provided in a structured way.
Syslog utilizes three layers
Functions are performed at each conceptual layer:
An “originator” generates syslog content to be carried in a message. (Router, server, switch, network device, etc.)
A “collector” gathers syslog content for further analysis. — Syslog Server.
A “relay” forwards messages, accepting messages from originators or other relays and sending them to collectors or other relays. — Syslog forwarder.
A “transport sender” passes syslog messages to a specific transport protocol. — the most common transport protocol is UDP, defined in RFC5426.
A “transport receiver” takes syslog messages from a specific transport protocol.
Syslog messages components
The information provided by the originator of a syslog message includes the facility code and the severity level.
The syslog software adds information to the information header before passing the entry to the syslog receiver:
Originator process ID
a timestamp
the hostname or IP address of the device.
Facility codes
The facility value indicates which machine process created the message. The Syslog protocol was originally written on BSD Unix, so Facilities reflect the names of the UNIX processes and daemons.
If you’re receiving messages from a UNIX system, consider using the User Facility as your first choice. Local0 through Local7 aren’t used by UNIX and are traditionally used by networking equipment. Cisco routers, for examples, use Local6 or Local7.
Syslog Severity Levels
Flows and Network Analysis
What information is gathered in flows?
Port Mirroring and Promiscuous Mode
Port mirroring
Sends a copy of network packets traversing on one switch port (or an entire VLAN) to a network monitoring connection on another switch port.
Port mirroring on a Cisco Systems switch is generally referred to as Switched Port Analyzer (SPAN) or Remote Switched Port analyzer (RSPAN).
Other vendors have different names for it, such as Roving Analysis Port (RAP) on 3COM switches.
This data is used to analyze and debug data or diagnose errors on a network.
Helps administrators keep a close eye on network performance and alerts them when problems occur.
It can be used to mirror either inbound or outbound traffic (or both) on one or various interfaces.
Promiscuous Mode Network Interface Card (NIC)
In computer networking, promiscuous mode (often shortened to “promisc mode” or “promisc. mode”) is a mode for a wired network interface controller (NIC) or wireless network interface controller (WNIC) that causes the controller o pass all traffic it receives to the Central Processing Unit (CPU) rather than passing only frames that the controller is intended to receive.
Firewalls, Intrusion Detection and Intrusion Prevention Systems
Next Generation Firewalls – Overview
What is a NGFW?
A NGFW is a part of the third generation of firewall technology. Combines traditional firewall with other network device filtering functionalities.
Application firewall using in-line deep packet inspection (DPI)
Intrusion prevention system (IPS).
Other techniques might also be employed, such as TLS/SSL encrypted traffic inspection, website filtering.
NGFW vs. Traditional Firewall
Inspection over the data payload of network packets.
NGFW provides the intelligence to distinguish business applications and non-business applications and attacks.
Traditional firewalls don’t have the fine-grained intelligence to distinguish one kind of Web traffic from another, and enforce business policies, so it’s either all or nothing.
NGFW and the OSI Model
The firewall itself must be able to monitor traffic from layers 2 through 7 and make a determination as to what type of traffic is being sent and received.
NGFW Packet Flow Example and NGFW Comparisons
Flow of Traffic Between Ingress and Egress Interfaces on a NGFW
Flow of Packets Through the Firewall
NGFW Comparisons:
Many firewalls vendors offer next-generation firewalls, but they argue over whose technique is the best.
A NGFW is application-aware. Unlike traditional stateful firewalls, which deal in ports and protocols, NGFW drill into traffic to identify the application transversing the network.
With current trends pushing applications into the public cloud or to be outsourced to SaaS provides, a higher level of granularity is needed to ensure that the proper data is coming into the enterprise network.
Examples of NGFW
Cisco Systems
Cisco Systems have announced plans to add new levels of application visibility into its Adaptive Security Appliance (ASA), as part of its new SecureX security architecture.
Palo Alto Networks
Says it was the first vendor to deliver NGFW and the first to replace port-based traffic classification with application awareness. The company’s products are based on a classification engine known as App-ID. App-ID identifies applications using several techniques, including decryption, detection, decoding, signatures, and heuristics.
Juniper Networks
They use a suite of software products, known as AppSecure, to deliver NGFW capabilities to its SRX Services Gateway. The application-aware component, known as AppTrack, provides visibility into the network based on Juniper’s signature database as well as custom application signatures created by enterprise administrators.
NGFW other vendors:
McAfee
Meraki MX Firewalls
Barracuda
Sonic Wall
Fortinet Fortigate
Check Point
WatchGuard
Open Source NGFW:
pfSense
It is a free and powerful open source firewall used mainly for FreeBSD servers. It is based on stateful packet filtering. Furthermore, it has a wide range of features that are normally only found in very expensive firewalls.
ClearOS
It is a powerful firewall that provides us the tools we need to run a network, and also gives us the option to scale up as and when required. It is a modular operating system that runs in a virtual environment or on some dedicated hardware in the home, office etc.
VyOS
It is open source and completely free, and based on Debian GNU/Linux. It can run on both physical and virtual platforms. Not only that, but it provides a firewall, VPN functionality and software based network routing. Likewise, it also supports paravirtual drivers and integration packages for virtual platforms. Unlike OpenWRT or pfSense, VyOS provides support for advanced routing features such as dynamic routing protocols and command line interfaces.
IPCop
It is an open source Linux Firewall which is secure, user-friendly, stable and easily configurable. It provides an easily understandable Web Interface to manage the firewall. Likewise, it is most suitable for small businesses and local PCs.
IDS/IPS
Classification of IDS
Signature based: Analyzes content of each packet at layer 7 with a set of predefined signatures.
Anomaly based: It monitors network traffic and compares it against an established baseline for normal use and classifying it as either normal or anomalous.
Types of IDS
Host based IDS (HIDS): Anti-threat applications such as firewalls, antivirus software and spyware-detection programs are installed on every network computer that has two-way access to the outside.
Network based IDS (NIDS): Anti-threat software is installed only at specific points, such as servers that interface between the outside environment and the network segment to be protected.
NIDS
Appliance: IBM RealSecure Server Sensor and Cisco IDS 4200 series
Software: Sensor software installed on server and placed in network to monitor network traffic, such as Snort.
IDS Location on Network
Hybrid IDS Implementation
Combines the features of HIDS and NIDS
Gains flexibility and increases security
Combining IDS sensors locations: put sensors on network segments and network hosts and can report attacks aimed at particular segments or the entire network.
What is an IPS?
Network security/threat prevention technology.
Examines network traffic flows to detect and prevent vulnerability exploits.
Often sits directly behind the firewall.
How does the attack affect me?
Vulnerability exploits usually come in the form of malicious inputs to a target application or service.
The attackers use those exploits to interrupt and gain control of an application or machine.
Once successful exploit, the attacker can disable the target application (DoS).
Also, can potentially access to all the rights and permissions available to the compromised application.
Prevention?
The IPS is placed inline (in the direct communication path between source and destination), actively analyzing and taking automated actions on all traffic flows that enter the network. Specifically, these actions include:
Sending an alarm to the admin (as would be seen in an IDS)
Dropping the malicious packets
Blocking traffic from the source address
Resetting the connection
Signature-based detection
It is based on a dictionary of uniquely identifiable patterns (or signatures) in the code of each exploit. As an exploit is discovered, its signature is recorded and stored in a continuously growing dictionary of signatures. Signatures detection for IPS breaks down into two types:
Exploit-facing signatures identify individual exploits by triggering on the unique patterns of a particular exploit attempt. The IPS can identify specific exploits by finding a match with an exploit-facing signatures in the traffic.
Vulnerability-facing signatures are broader signatures that target the underlying vulnerability in the system that is being targeted. These signatures allow networks to be protected from variants of an exploit that may not have been directly observed in the wild, but also raise the risk of false positive.
Statistical anomaly detection
Takes samples of network traffic at random and compares them to a pre-calculated baseline performance level. When the sample of network traffic activity is outside the parameters of baseline performance, the IPS takes action to handle the situation.
IPS was originally built and released as a standalone device in the mid-2000s. This, however, was in the advent of today’s implementations, which are now commonly integrated into Unified Threat Management (UTM) solutions (for small and medium size companies) and NGFWs (at the enterprise level).
High Availability and Clustering
What is HA?
In information technology, high availability (HA) refers to a system or component that is continuously operational for a desirably long length of time. Availability can be measured relative to “100% operational” or “never failing”.
HA architecture is an approach of defining the components, modules, or implementation of services of a system which ensures optimal operational performance, even at times of high loads.
Although there are no fixed rules of implementing HA systems, there are generally a few good practices that one must follow so that you gain most out of the least resources.
Requirements for creating an HA cluster?
Hosts in a virtual server cluster must have access to the same shared storage, and they must have identical network configurations.
Domain name system (DNS) naming is important too: All hosts must resolve other hosts using DNS names, and if DNS isn’t set correctly, you won’t be able to configure HA settings at all.
Same OS level.
Connections between the primary and secondary nodes.
How HA works?
To create a highly available system, three characteristics should be present:
Redundancy:
Means that there are multiple components that can perform the same task. This eliminates the single point of failure problem by allowing a second server to take over a task if the first one goes down or becomes disabled.
Monitoring and Failover
In a highly available setup, the system needs to be able to monitor itself for failure. This means that there are regular checks to ensure that all components are working properly. Failover is the process by which a secondary component becomes primary when monitoring reveals that a primary component has failed.
NIC Teaming
It is a solution commonly employed to solve the network availability and performance challenges and has the ability to operate multiple NICs as a single interface from the perspective of the system.
NIC teaming provides:
Protection against NIC failures
Fault tolerance in the event of a network adapter failure.
HA on a Next-Gen FW
Introduction to Databases
Data Source Types
Distributed Databases
Microsoft SQL Server, DB2, Oracle, MySQL, SQLite, Postgres etc.
Structured Data
Data Warehouses
Amazon’s redshift, Netezza, Exadata, Apache Hive etc.
Structured Data
Big Data
Google BigTable, Hadoop, MongoDB etc.
Semi-Structured Data
File Shares
NAS (Network Attached Storage), Network fileshares such as EMC or NetApp; and Cloud Shares such as Amazon S3, Google Drive, Dropbox, Box.com etc.
Unstructured-Data
Data Model Types
Structured Data
“Structured data is data that has been organized into a formatted repository, typically a database, so that its elements can be made addressable for more effective processing and analysis.”
Semi-Structured Data
“Semi-structured data is data that has not been organized into a specialized repository, such as a database, but that nevertheless has associated information, such as metadata, that makes it more amenable to processing than raw data.”
A Word document with tags and keywords.
Unstructured Data
“Unstructured data is information, in many forms, that doesn’t hew to conventional data models and thus typically isn’t a good fit for a mainstream relational database.”
A Word Document, transaction data etc.
Types of Unstructured Data
Text (most common type)
Images
Audio
Video
Structured Data
Flat File Databases
Flat-file databases take all the information from all the records and store everything in one table.
This works fine when you have some records related to a single topic, such as a person’s name and phone numbers.
But if you have hundreds or thousands of records, each with a number of fields, the database quickly becomes difficult to use.
Relational Databases
Relational databases separate a mass of information into numerous tables. All columns in each table should be about one topic, such as “student information”, “class Information”, or “trainer information”.
The tables for a relational database are linked to each other through the use of Keys. Each table may have one primary key and any number of foreign keys. A foreign key is simply a primary key from one table that has been placed in another table.
The most important rules for designing relational databases are called Normal Forms. When databases are designed properly, huge amounts of information can be kept under control. This lets you query the database (search for information section) and quickly get the answer you need.
Securing Databases
Securing your “Crown Jewels”
Leveraging Security Industry Best Practices
Enforce:
DOD STIG
CIS (Center for Internet Security)
CVE (Common Vulnerability and Exposures)
Secure:
Privileges
Configuration settings
Security patches
Password policies
OS level file permission
Established Baseline:
User defined queries for custom tests to meet baseline for;
Organization
Industry
Application
Ownership and access for your files
Forensics:
Advanced Forensics and Analytics using custom reports
Understand your sensitive data risk and exposure
Structured Data and Relational Databases
Perhaps the most common day-to-day use case for a database is using it as the backend of an application, such as your organization HR system, or even your organization’s email system!
Anatomy of a Vulnerability Assessment Test Report
Securing Data Sources by Type
A Data Protection Solution Example, IBM Security Guadium Use Cases
Data Monitoring
Data Activity Monitoring/Auditing/Logging
Does your product log all key activity generation, retrieval/usage, etc.?
Demo data access activity monitoring and logging of the activity monitoring?
Does your product monitor for unique user identities (including highly privileged users such as admins and developers) with access to the data?
At the storage level, can it detect/identify access to highly privileged users such as database admins, system admins or developers?
Does your product generate real time alerts of policy violations while recording activities?
Does your product monitor user data access activity in real time with customizable security alerts and blocking unacceptable user behavior, access patterns or geographic access, etc.? If yes, please describe.
Does your product generate alerts?
Demo the capability for reporting and metrics using information logged.
Does your product create auditable reports of data access and security events with customizable details that can address defined regulations or standard audit process requirements? If yes, please describe.
Does your product support the ability to log security events to a centralized security incident and event management (SIEM) system?
Demo monitoring of non-Relational Database Management Systems (nRDBMS) systems, such as Cognos, Hadoop, Spark, etc.
Deep Dive Injection Vulnerability
What are injection flaws?
Injection Flaws: They allow attackers to relay malicious code through the vulnerable application to another system (OS, Database server, LDAP server, etc.)
They are extremely dangerous, and may allow full takeover of the vulnerable system.
Injection flaws appear internally and externally as a Top Issue.
OS Command Injection
What is OS Command Injection?
Abuse of vulnerable application functionality that causes execution of attacker-specified OS commands.
Applies to all OSes – Linux, Windows, macOS.
Made possible by lack of sufficient input sanitization, and by unsafe execution of OS commands.
Attacker can inject arbitrary malicious OS command – MUCH WORSE:
/bin/sh -c "/bin/rm /var/app/logs/x;rm -rf /"
OS command injection can lead to:
Full system takeover
Denial of service
Stolen sensitive information (passwords, crypto keys, sensitive personal info, business confidential data)
Lateral movement on the network, launching pad for attacks on other systems
Use of system for botnets or cryptomining
This is as bad as it gets, a “GAME OVER” event.
How to Prevent OS Command Injection?
Recommendation #1 – don’t execute OS commands
Sometimes OS command execution is introduced as a quick fix, to let the command or group of commands do the heavy lifting.
This is dangerous, because insufficient input checks may let a destructive OS command slip in.
Resist the temptation to run OS commands and use built-in or 3rd party libraries instead:
Instead of rm use java.nio.file.Files.deleteIfExists(file)
Instead of cp use java.nio.file.Files.copy(source, destination) … and so on.
Use of library functions significantly reduces the attack surface.
Recommendation #2 – Run at the least possible privilege level
It is a good idea to run under a user account with the least required rights.
The more restricted the privilege level is, the less damage can be done.
If an attacker is able to sneak in an OS command (e.g., rm -rf /) he can do much less damage when the application is running as tomcat user vs. running as root user.
This helps in case of many vulnerabilities, not just injection.
Recommendation #3 – Don’t run commands through shell interpreters
When you run shell interpreters like sh, bash, cmd.exe, powershell.exe it is much easier to inject commands.
The following command allows injection of an extra rm:
/bin/sh -c "/bin/rm /var/app/logs/x;rm -rf /"
… but in this case injection will not work, the whole command will fail:
/bin/rm /var/app/logs/x;rm -rf/
Running a single command directly executes just that command.
Note that it is still possible to influence the behavior of a single command (e.g., for nmap the part on the right, when injected, could overwrite a vital system file):
/usr/bin/nmap 1.2.3.4 -oX /lib/libc.so.6
Also note that the parameters that you pass to a script may still result in command injection:
processfile.sh "x;rm -rf /"
Recommendation #4 – Use explicit paths when running executables
Applications are found and executed based on system path settings.
If a writable folder is referenced in the path before the folder containing the valid executable, an attacker may install a malicious version of the application there.
In this case, the following command will cause execution of the malicious application:
/usr/bin/nmap 123.45.67.89
The same considerations apply to shared libraries, explicit references help avoid DLL hijacking.
Recommendation #5 – Use safer functions when running system commands
If available, use functionality that helps prevent command injection.
For example, the following function call is vulnerable to new parameter injection (one could include more parameters, separated by spaces, in ipAddress):
The query may not return the data directly, but it can be inferred by executing many queries whose behavior presents one of two outcomes.
Can be Boolean-based (one of two possible responses), and Time-based (immediate vs delayed execution).
For example, the following expression, when injected, indicates if the first letter of the password is a:
IF(passwordLIKE'a%',sleep(10),'false')
Out of Band
Data exfiltration is done through a separate channel (e.g., by sending an HTTP request).
How to Prevent SQL Injection?
Recommendation #1 – Use prepared statements
Most SQL injection happens because queries are pieced together as text.
Use of prepared statements separates the query structure from query parameters.
Instead of this pattern:
stmt.executeQuery("SELECT * FROM users WHERE user='"+user+"' AND pass='"pass+"'")
… use this:
PreparedStatementps=conn.preparedStatement("SELECT * FROM users WHERE user = ? AND pass = ?");ps.setString(1,user);ps.setString(2,pass);
SQL injection risk now mitigated.
Note that prepared statements must be used properly, we occasionally see bad examples like:
conn.preparedStatement("SELECT * FROM users WHERE user = ? AND pass = ? ORDER BY "+column);
Recommendation #2 – Sanitize user input
Just like for OS command injection, input sanitization is important.
Only restrictive whitelists should be used, not blacklists.
Where appropriate, don’t allow user input to reach the database, and instead use mapping tables to translate it.
Recommendation #3 – Don’t expose database errors to the user
Application errors should not expose internal information to the user.
Details belong in an internal log file.
Exposed details can be abused for tailoring SQL injection commands.
For examples, the following error message exposes both the internal query structure and the database type, helping attackers in their efforts:
ERROR: If you have an error in your SQL syntax, check the manual that corresponds to your MySQL server version for the right syntax to use near “x” GROUP BY username ORDER BY username ASC’ at line 1.
Recommendation #4 – Limit database user permissions
When user queries are executed under a restricted user, less damage is possible if SQL injection happens.
Consider using a user with read-only permissions when database updates are not required, or use different users for different operations.
Recommendation #5 – Use stored Procedures
Use of stored procedures mitigates the risk by moving SQL queries into the database engine.
Fewer SQL queries will be under direct control of the application, reducing likelihood of abuse.
Recommendation #6 – Use ORM libraries
Object-relational mapping (ORM) libraries help mitigate SQL injection
Examples: Java Persistence API (JPA) implementations like Hibernate.
ORM helps reduce or eliminate the need for direct SQL composition.
However, if ORM is used improperly SQL injections may still be possible:
QueryhqlQuery=session.createQuery("SELECT * FROM users WHERE user='"+user+"'AND pass='"+pass+"'")
Other Types of Injection
Injection flaws exist in many other technologies
Apart from the following, there are injection flaws also exist in Templating engines.
… and many other technologies
Recommendation for avoiding all of them are similar to what is proposed for OS and SQL injection.
NoSQL Injection
In MongoDB $where query parameter is interpreted as JavaScript.
Suppose we take an expression parameter as input:
$where:"$expression"
In simple case it is harmless:
$where:"this.userType==3"
However, an attacker can perform a DoS attack:
$where:"d = new Date; do {c = new Date;} while (c - d < 100000;"
XPath Injection
Suppose we use XPath expressions to select user on login:
In the benign case, it will select only the user whose name and password match:
//Employee[UserName/text()='bob' AND Password/text()='secret']
In the malicious case, it will select any user:
//Employee[UserName/text()='' or 1=1 or '1'='1' And Password/text()='']
LDAP Injection
LDAP is a common mechanism for managing user identity information. The following expression will find the user with the specified username and password.
find("(&(cn=" + user +")(password=" + pass +"))")
In the regular case, the LDAP expression will work only if the username and password match:
find("(&(cn=bob)(password=secret))")
Malicious users may tweak the username to force expression to find any user:
find("(&(cn=*)(cn=*))(|cn=*)(password=any)")
Penetration Testing, Incident Response and Forensics
“Penetration testing is security testing in which assessors mimic real-world attacks to identify methods for circumventing the security features of an application, system, or network. It often involves launching real attacks on real systems and data that use tools and techniques commonly used by attackers.”
Operating Systems
Desktop
Mobile
Windows
iOS
Unix
Android
Linux
Blackberry OS
macOS
Windows Mobile
ChromeOS
WebOS
Ubuntu
Symbian OS
Approaches
Internal vs. external
Web and mobile application assessments
Social Engineering
Wireless Network, Embedded Device & IoT
ICS (Industry Control Systems) penetration
General Methodology
Planning
Discovery
Attack
Report
Penetration Testing Phases
Penetration Testing – Planning
Setting Objectives
Establishing Boundaries
Informing Need-to-know employees
Penetration Testing – Discovery
Vulnerability analysis
Vulnerability scanning can help identify outdated software versions, missing patches, and misconfigurations, and validate compliance with or deviations from an organization’s security policy. This is done by identifying the OSes and major software applications running on the hosts and matching them with information on known vulnerabilities stored in the scanners’ vulnerability databases.
Dorks
A Google Dork query, sometimes just referred to as a dork, is a search string that uses advanced search operators to find information that is not readily available on a website.
What Data Can We Find Using Google Dorks?
Admin login pages
Username and passwords
Vulnerable entities
Sensitive documents
Govt/military data
Email lists
Bank Account details and lots more…
Passive vs. Active Record
Passive
Active
Monitoring employees
Network Mapping
Listening to network traffic
Port Scanning
Password cracking
Social Engineering
“Social Engineering is an attempt to trick someone into revealing information (e.g., a password) that can be used to attack systems or networks. It is used to test the human element and user awareness of security, and can reveal weaknesses in user behavior.”
Scanning Tools
Network Mapper → NMAP
Network Analyzer and Profiler → WIRESHARK
Password Crackers → JOHNTHERIPPER
Hacking Tools → METASPLOIT
Passive Online
Wire sniffing
Man in the Middle
Replay Attack
Active Online
Password Guessing
Trojan/spyware/keyloggers
Hah injection
Phishing
Offline Attacks
Pre-computed Hashes
Data structures that use a hash function to store, order, and/or access data in an array.
Distributed Network Attack (DNA)
DNA is a password cracking system sold by AccessData.
DNA can perform brute-force cracking of 40-bit RC2/RC4 keys. For longer keys, DNA can attempt password cracking. (It’s computationally infeasible to attempt a brute-force attack on a 128-bit key.)
DNA can mine suspect’s hard drive for potential passwords.
Rainbow Tables
A rainbow table is a pre-computed table for reversing cryptographic hash functions, usually for cracking password hashes.
Tech-less Discovery
Social Engineering
Shoulder surfing
Dumpster Diving
Penetration Testing – Attack
“While vulnerability scanners check only for the possible existence of a vulnerability, the attack phase of a penetration test exploits the vulnerability to confirm its existence.”
Types of Attack Scenarios
White Box Testing:
In this type of testing, the penetration tester has full access to the target system and all relevant information, including source code, network diagrams, and system configurations. This type of testing is also known as “full disclosure” testing and is typically performed during the planning phase of penetration testing.
Grey Box Testing:
In this type of testing, the penetration tester has partial access to the target system and some knowledge of its internal workings, but not full access or complete knowledge. This type of testing is typically performed during the Discovery phase of penetration testing.
Black Box Testing:
In this type of testing, the penetration tester has no prior knowledge or access to the target system and must rely solely on external observations and testing to gather information and identify vulnerabilities. This type of testing is also known as “blind” testing and is typically performed during the Attack phase of penetration testing.
Exploited Vulnerabilities
Penetration Testing – Reporting
Executive Summary
“This section will communicate to the reader the specific goals of the Penetration Test and the high level findings of the testing exercise.”
Background
Overall Posture
Risk Ranking
General Findings
Recommendations
Roadmap
Technical Review
Introduction
Personnel involved
Contact information
Assets involved in testing
Objectives of Test
Scope of test
Strength of test
Approach
Threat/Grading Structure
Scope
Information gathering
Passive intelligence
Active intelligence
Corporate intelligence
Personnel intelligence
Vulnerability Assessment
In this section, a definition of the methods used to identify the vulnerability as well as the evidence/classification of the vulnerability should be present.
Vulnerability Confirmation
This section should review, in detail, all the steps taken to confirm the defined vulnerability as well as the following:
Exploitation Timeline
Targets selected for Exploitation
Exploitation Activities
Post Exploitation
Escalation path
Acquisition of Critical Information
Value of information Access to core business systems
Access to compliance protected data sets
Additional information/systems accessed
Ability of persistence
Ability for exfiltration
Countermeasure
Effectiveness
Risk/Exposure
This section will cover the business risk in the following subsection:
Evaluate incident frequency
Estimate loss magnitude per incident
Derive Risk
Penetration Testing Tools
Kali Linux
NMAP (Network Scanner)
JohnTheRipper (Password cracking tool)
MetaSploit
Wireshark (Packet Analyzer)
HackTheBox (Testing playground)
LameWalkThrough (Testing playground)
Incident Response
What is Incident Response?
“Preventive activities based on the results of risk assessments can lower the number of incidents, but not all incidents can be prevented. An incident response is therefore necessary for rapidly detecting incidents, minimizing loss and destruction, mitigating the weaknesses that were exploited, and restoring IT services.”
Events
“An event can be something as benign and unremarkable as typing on a keyboard or receiving an email.”
In some cases, if there is an Intrusion Detection System(IDS), the alert can be considered an event until validated as a threat.
Incident
“An incident is an event that negatively affects IT systems and impacts on the business. It’s an unplanned interruption or reduction in quality of an IT service.”
An event can lead to an incident, but not the other way around.
Why Incident Response is Important
One of the benefit of having an incident response is that it supports responding to incidents systematically so that the appropriate actions are taken, it helps personnel to minimize loss or theft of information and disruption of services caused by incidents, and to use information gained during incident handling to better prepare for handling future incidents.
IR Team Models
Central teams
Distributed teams
Coordinating teams
Coordinating Teams
Incident don’t occur in a vacuum and can have an impact on multiple parts of a business. Establish relationships with the following teams:
Common Attack Vectors
Organization should be generally prepared to handle any incident, but should focus on being prepared to handle incident that use common attack vectors:
External/Removable Media
Attrition
Web
Email
Impersonation
Loss or theft of equipment
Baseline Questions
Knowing the answers to these will help your coordination with other teams and the media.
Who attacked you? Why?
When did it happen? How did it happen?
Did this happen because you have poor security processes?
How widespread is the incident?
What steps are you taking to determine what happened and to prevent future occurrences?
What is the impact of the incident?
Was any PII exposed?
What is the estimated cost of this incident?
Incident Response Phases
Incident Response Process
Incident Response Preparation
Incident Response Policy
IR Policy needs to cover the following:
IR Team
The composition of the incident response team within the organization.
Roles
The role of each of the team members.
Means, Tools, Resources
The technological means, tools, and resources that will be used to identify and recover compromised data.
Policy Testing
The persons responsible for testing the policy.
Action Plan
How to put the policy into the action?
Resources
Incident Handler Communications and Facilities:
Contact information
On-call information
Incident reporting mechanisms
Issue tracking system
Smartphones
Encryption software
War room
Secure storage facility
Incident Analysis Hardware and Software:
Digital forensic workstations and/or backup devices
Laptops
Spare workstations, servers, and networking equipment
Blank removable media
Portable printer
Packet sniffers and protocol analyzers
Digital forensic software
Removable media
Evidence gathering accessories
Incident Analysis Resources:
Port lists
Documentation
Network diagrams and lists of critical assets
Current baselines
Cryptographic hashes
The Best Defense
“Keeping the number of incidents reasonably low is very important to protect the business processes of the organization. It security controls are insufficient, higher volumes of incidents may occur, overwhelming the incident response team.”
So the best defense is:
Periodic Risk Assessment
Hardened Host Security
Whitelist based Network Security
Malware prevention systems
User awareness and training programs
Checklist
Are all members aware of the security policies of the organization?
Do all members of the Computer Incident Response Team know whom to contact?
Do all incident responders have access to journals and access to incident response toolkits to perform the actual incident response process?
Have all members participated in incident response drills to practice the incident response process and to improve overall proficiency on a regularly established basis?
Incident Response Detection and Analysis
Precursors and Indicators
Precursors
A precursor is a sign that an incident may occur in the future.
Web server log entries that show the usage of a vulnerability scanner.
An announcement of a new exploit that targets a vulnerability of the organization’s mail server.
A threat from a group stating that the group will attack the organization.
Indicators
An indicator is a sing that an incident may have occurred or may be occurring now.
Antivirus software alerts when it detects that a host is infected with malware.
A system admin sees a filename with unusual characters.
A host records an auditing configuration change in its log.
An application logs multiple failed login attempts from an unfamiliar remote system.
An email admin sees many bounced emails with suspicious content.
A network admin notices an unusual deviation from typical network traffic flows.
Monitoring Systems
Monitoring systems are crucial for early detection of threats.
These systems are not mutually exclusive and still require an IR team to document and analyze the data.
IDS vs. IPS
Both are parts of the network infrastructure. The main difference between them is that IDS is a monitoring system, while IPS is a control system.
DLP
Data Loss Prevention (DLP) is a set of tools and processes used to ensure that sensitive data is not lost, misused, or accessed by unauthorized users.
SIEM
Security Information and Event Management solutions combine Security Event Management (SEM) – which carries out analysis of event and log data in real-time, with Security Information Management (SIM).
Documentation
Regardless of the monitoring system, highly detailed, thorough documentation is needed for the current and future incidents.
The current status of the incident
A summary of the incident
Indicators related to the incident
Other incident related to this incident
Actions taken by all incident handlers on this incident.
Chain of custody, if applicable
Impact assessments related to the incident
Contact information for other involved parties
A list of evidence gathered during the incident investigation
Comments from incident handlers
Next steps to be taken (e.g., rebuild the host, upgrade an application)
Functional Impact Categories
Information Impact Categories
Recoverability Effort Categories
Notifications
CIO
Local and Head of information security
Other incident response teams within the organization
External incident response teams (if appropriate)
System owner
Human resources
Public affairs
Legal department
Law enforcement (if appropriate)
Containment, Eradication & Recovery
Containment
“Containment is important before an incident overwhelms resources or increases damage. Containment strategies vary based on the type of incident. For example, the strategy for containing an email-borne malware infection is quite different from that of a network-based DDoS attack.”
An essential part of containment is decision-making. Such decisions are much easier to make if there are predetermined strategies and procedures for containing the incident.
Potential damage to and theft of resources
Need for an evidence preservation
Service availability
Time and resources needed to implement the strategy
Effectiveness of the strategy
Duration of the solution
Forensics in IR
“Evidence should be collected to procedures that meet all applicable laws and regulations that have been developed from previous discussions with legal staff and appropriate law enforcement agencies so that any evidence can be admissible in court.” — NIST 800-61
Capture a backup image of the system as-is
Gather evidence
Follow the Chain of custody protocols
Eradication and Recovery
After an incident has been contained, eradication may be necessary to eliminate components of the incident, such as deleting malware and disabling breached user accounts, as well as identifying and mitigating all vulnerabilities that were exploited.
Recovery may involve such actions as restoring systems from clean backups, rebuilding systems from scratch, replacing compromised files with clean versions, installing patches, changing passwords, and tightening network perimeter security.
A high level of testing and monitoring are often deployed to ensure restored systems are no longer impacted by the incident. This could take weeks or months, depending on how long it takes to bring back compromised systems into production.
Checklist
Can the problem be isolated? Are all affected systems isolated from non-affected systems? Have forensic copies of affected systems been created for further analysis?
If possible, can the system be reimaged and then hardened with patches and/or other countermeasures to prevent or reduce the risk of attacks? Have all malware and other artifacts left behind by the attackers been removed, and the affected systems hardened against further attacks?
What tools are you going to use to test, monitor, and verify that the systems being restored to productions are not compromised by the same methods that cause the original incident?
Post Incident Activities
Holding a “lessons learned” meeting with all involved parties after a major incident, and optionally periodically after lesser incidents as resources permit, can be extremely helpful in improving security measures and the incident handling process itself.
Lessons Learned
Exactly what happened, and at what times?
How well did staff and management perform in dealing with the incident? Were the documented procedures followed? Were they adequate?
What information was needed sooner?
Were any steps or actions taken that might have inhibited the recovery?
What would the staff and management do differently the next time a similar incident occurs?
How could information sharing with other organizations have been improved?
What corrective actions can prevent similar incidents in the future?
What precursors or indicators should be watched in the future to detect the similar incidents?
Other Activities
Utilizing data collected
Evidence Retention
Documentation
Digital Forensics
Forensics Overview
What are Forensics?
“Digital forensics, also known as computer and network forensics, has many definitions. Generally, it is considered the application of science to the identification, collection, examination, and analysis of data while preserving the integrity of the information and maintaining a strict chain of custody for the data.”
Types of Data
The first step in the forensic process is to identify potential sources of data and acquire data from them. The most obvious and common sources of data are desktop computers, servers, network storage devices, and laptops.
CDs/DVDs
Internal & External Drives
Volatile data
Network Activity
Application Usage
Portable Digital Devices
Externally Owned Property
Computer at Home Office
Alternate Sources of Data
Logs
Keystroke Monitoring
The Need for Forensics
Criminal Investigation
Incident Handling
Operational Troubleshooting
Log Monitoring
Data Recovery
Data Acquisition
Due Diligence/Regulatory Compliance
Objectives of Digital Forensics
It helps to recover, analyze, and preserve computer and related materials in such a manner that it helps the investigation agency to present them as evidence in a court of law. It helps to postulate the motive behind the crime and identity of the main culprit.
Designing procedures at a suspected crime scene, which helps you to ensure that the digital evidence obtained is not corrupted.
Data acquisition and duplication: Recovering deleted files and deleted partitions from digital media to extract the evidence and validate them.
Help you to identify the evidence quickly, and also allows you to estimate the potential impact of the malicious activity on the victim.
Producing a computer forensic report, which offers a complete report on the investigation process.
Preserving the evidence by following the chain of custody.
Forensic Process – NIST
Collection
Identify, label, record, and acquire data from the possible sources, while preserving the integrity of the data.
Examination
Processing large amounts of collected data to assess and extract of particular interest.
Analysis
Analyze the results of the examination, using legally justifiable methods and techniques.
Reporting
Reporting the results of the analysis.
The Forensic Process
Data Collection and Examination
Examination
Steps to Collect Data
Develop a plan to acquire the data
Create a plan that prioritizes the sources, establishing the order in which the data should be acquired.
Acquire the Data
Use forensic tools to collect the volatile data, duplicate non-volatile data sources, and securing the original data sources.
Verify the integrity of the data
Forensic tools can create hash values for the original source, so the duplicate can be verified as being complete and untampered with.
Overview of Chain of Custody
A clearly defined chain of custody should be followed to avoid allegations of mishandling or tampering of evidence. This involves keeping a log of every person who had physical custody of the evidence, documenting the actions that they performed on the evidence and at what time, storing the evidence in a secure location when it is not being used, making a copy of the evidence and performing examination and analysis using only the copied evidence, and verifying the integrity of the original and copied evidence.
Examination
Bypassing Controls
OSs and applications may have data compression, encryption, or ACLs.
A Sea of Data
Hard drives may have hundreds of thousands of files, not all of which are relevant.
Tools
There are various tools and techniques that exist to help filter and exclude data from searches to expedite the process.
Analysis & Reporting
Analysis
“The analysis should include identifying people, places, items, and events, and determining how these elements are related so that a conclusion can be reached.”
Putting the pieces together
Coordination between multiple sources of data is crucial in making a complete picture of what happened in the incident. NIST provides the example of an IDS log linking an event to a host. The host audit logs linking the event to a specific user account, and the host IDS log indicating what actions that user performed.
Writing your forensic report
A case summary is meant to form the basis of opinions. While there are a variety of laws that relate to expert reports, the general rules are:
If it is not in your report, you cannot testify about it.
Your report needs to detail the basis for your conclusions.
Detail every test conducted, the methods and tools used, and the results.
Report Composition
Overview/Case Summary
Forensic Acquisition & Examination Preparation
Finding & report (analysis)
Conclusion
SANS Institute Best Practices
Take Screenshots
Bookmark evidence via forensic application of choice
Use built-in logging/reporting options within your forensic tool
Highlight and exporting data items into .csv or .txt files
Use a digital audio recorder vs. handwritten notes when necessary
Forensic Data
Data Files
What’s not there
Deleted files
When a file is deleted, it is typically not erased from the media; instead, the information in the directory’s data structure that points to the location of the file is marked as deleted.
Slack Space
If a file requires less space than the file allocation unit size, an entire file allocation unit is still reserved for the file.
Free Space
Free space is the area on media that is not allocated to any partition, the free space may still contain pieces of data.
MAC data
It’s important to know as much information about relevant files as possible. Recording the modification, access, and creation times of files allows analysts to help establish a timeline of the incident.
Modification Time
Access Time
Creation Time
Logical Backup
Imaging
A logical data backup copies the directories and files of a logical volume. It does not capture other data that may be present on the media, such as deleted files or residual data stored in slack space.
Generates a bit-for-bit copy of the original media, including free space and slack space. Bit stream images require more storage space and take longer to perform than logical backups.
Can be used on live systems if using a standard backup software
If evidence is needed for legal or HR reasons, a full bit stream image should be taken, and all analysis done on the duplicate
May be resource intensive
Disk-to-disk vs Disk-to-File
Should not be use on a live system since data is always chaning
Tools for Techniques
Many forensic products allow the analyst to perform a wide range of processes to analyze files and applications, as well as collecting files, reading disk images, and extracting data from files.
File Viewers
Uncompressing Files
GUI for Data Structure
Identifying Known Files
String Searches & Pattern Matches
Metadata
Operating System Data
“OS data exists in both non-volatile and volatile states. Non-volatile data refers to data that persists even after a computer is powered down, such as a filesystem stored on a hard drive. Volatile data refers to data on a live system that is lost after a computer is powered down, such as the current network connections to and from the system.”
Volatile
Non-Volatile
Slack Space
Configuration Files
Free Space
Logs
Network configuration/connections
Application files
Running processes
Data Files
Open Files
Swap Files
Login Sessions
Dump Files
Operating System Time
Hibernation Files
Temporary Files
Collection & Prioritization of Volatile Data
Network Connections
Login Sessions
Contents of Memory
Running Processes
Open Files
Network Configuration
Operating System Time
Collecting Non-Volatile Data
Consider Power-Down Options
File System Data Collected
Users and Groups
Passwords
Network Shares
Logs
Logs
Other logs can be collected depending on the incident under analysis:
In case of a network hack:
Collect logs of all the network devices lying in the route of the hacked devices and the perimeter router (ISP router). Firewall rule base may also be required in this case.
In case it is unauthorized access:
Save the web server logs, application server logs, application logs, router or switch logs, firewall logs, database logs, IDS logs etc.
In case of a Trojan/Virus/Worm attack:
Save the antivirus logs apart from the event logs (pertaining to the antivirus).
Windows
The file systems used by Windows include FAT, exFAT, NTFS, and ReFS.
Investigators can search out evidence by analyzing the following important locations of the Windows:
Recycle Bin
Registry
Thumbs.db
Files
Browser History
Print Spooling
macOS
Mac OS X is the UNIX bases OS that contains a Mach 3 microkernel and a FreeBSD based subsystem. Its user interface is Apple like, whereas the underlying architecture is UNIX like.
Mac OS X offers novel techniques to create a forensic duplicate. To do so, the perpetrator’s computer should be placed into a “Target Disk Mode”. Using this mode, the forensic examiner creates a forensic duplicate of the perpetrator’s hard disk with the help of a FireWire cable connection between the two PCs.
Linux
Linux can provide an empirical evidence of if the Linux embedded machine is recovered from a crime scene. In this case, forensic investigators should analyze the following folders and directories.
/etc[%SystemRoot%/System32/config]
/var/log
/home/$USER
/etc/passwd
Application Data
OSs, files, and networks are all needed to support applications: OSs to run the applications, networks to send application data between systems, and files to store application data, configuration settings, and the logs. From a forensic perspective, applications bring together files, OSs, and networks. — NIST 800-86
Application Components
Config Settings
Configuration file
Runtime Options
Added to Source Code
Authentication
External Authentication
Proprietary Authentication
Pass-through authentication
Host/User Environment
Logs
Event
Audit
Error
Installation
Debugging
Data
Can live temporary in memory and/or permanently in files
File format may be generic or proprietary
Data may be stored in databases
Some applications create temp files during session or improper shutdown
Supporting Files
Documentation
Links
Graphics
App Architecture
Local
Client/Server
Peer-to-Peer
Types of Applications
Certain of application are more likely to be the focus of forensic analysis, including email, Web usage, interactive messaging, file-sharing, document usage, security applications, and data concealment tools.
Email
“From end to end, information regarding a single email message may be recorded in several places – the sender’s system, each email server that handles the message, and the recipient’s system, as well as the antivirus, spam, and content filtering server.” — NIST 800-45
Web Usage
Web Data from Host
Web Data from Server
Typically, the richest sources of information regarding web usage are the hosts running the web browsers.
Another good source of web usage information is web servers, which typically keep logs of the requests they receive.
Favorite websites
Timestamps
History w/timestamps of websites visited
IP Addresses
Cached web data files
Web browesr version
Cookies
Type of request
Resource requested
Collecting the Application Data
Overview
Network Data
“Analysts can use data from network traffic to reconstruct and analyze network-based attacks and inappropriate network usage, as well as to troubleshoot various types of operational problems. The term network traffic refers to computer network communications that are carried over wired or wireless networks between hosts.” — NIST 800-86
TCP/IP
Sources of Network Data
These sources collectively capture important data from all four TCP/IP layers.
Data Value
IDS Software
SEM Software
NFAT Software (Network Forensic Analysis Tool)
Firewall, Routers, Proxy Servers, & RAS
DHCP Server
Packet Sniffers
Network Monitoring
ISP Records
Attacker Identification
“When analyzing most attacks, identifying the attacker is not an immediate, primary concern: ensuring that the attack is stopped and recovering systems and data are the main interests.” — NIST 800-86
Contact IP Address Owner:
Can help identify who is responsible for an IP address, Usually an escalation.
Send Network Traffic:
Not recommended for organizations
Application Content:
Data packets could contain information about the attacker’s identity.
Seek ISP Assistance:
Requires court order and is only done to assist in the most serious of attacks.
History of IP address:
Can look for trends of suspicious activity.
Introduction to Scripting
Scripting Overview
History of Scripting
IBM’s Job Control Language (JCL) was the first scripting language.
Many batch jobs require setup, with specific requirements for main storage, and dedicated devices such as magnetic tapes, private disk volumes, and printers set up with special forms.
JCL was developed as a means of ensuring that all required resources are available before a job is scheduled to run.
The first interactive shell was developed in the 1960s.
Calvin Mooers in his TRAC language is generally credited with inventing command substitution, the ability to embed commands in scripts that when interpreted insert a character string into the script.
One innovation in the UNIX shells was the ability to send the output of one program into the input of another, making it possible to do complex tasks in one line of shell code.
Script Usage
Scripts have multiple uses, but automation is the name of the game.
Image rollovers
Validation
Backup
Testing
Scripting Concepts
Scripts
Small interpreted programs
Script can use functions, procedures, external calls, variables, etc.
Variables
Arguments/Parameters
Parameters are pre-established variables which will be used to perform the related process of our function.
If Statement
Loops
For Loop
While Loop
Until Loop
Scripting Languages
JavaScript
Object-oriented, developed in 1995 by Netscape communications.
Server or client side use, most popular use is client side.
Supports event-driven functional, and imperative programming styles. It has APIs for working with text, arrays, dates, regular expression, and the DOM, but the language itself doesn’t include any I/O, such as networking, storage, or graphics facilities. It relies upon the host environment in which it is embedded to provide these features.
Bash
UNIX shell and command language, written by Brian Fox for the GNU project as a free software replacement for the Bourne shell.
Released in 1989.
Default login shell for most Linux distros.
A command processor typically runs in a text window, but can also read and execute commands from a file.
POSIX compliant
Perl
Larry Wall began work on Perl in 1987.
Version 1.0 released on Dec 18, 1987.
Perl2 – 1988
Perl3 – 1989
Originally, the only documentation for Perl was a single lengthy man page.
Perl4 – 1991
PowerShell
Task automation and configuration management framework
Open-sourced and cross-platformed on 18 August 2016 with the introduction of PowerShell Core. The former is built on .NET Framework, while the latter on .NET Core.
Binary
Binary code represents text, computer processor instructions, or any other data using a two-symbol system. The two-symbol used is often “0” and “1” from the binary number system.
Adding a binary payload to a shell script could, for instance, be used to create a single file shell script that installs your entire software package, which could be composed of hundreds of files.
Hex
Advanced hex editors have scripting systems that let the user create macro like functionality as a sequence of user interface commands for automating common tasks. This can be used for providing scripts that automatically patch files (e.g., game cheating, modding, or product fixes provided by the community) or to write more complex/intelligent templates.
“Cyber threat intelligence is information about threats and threat actors that helps mitigate harmful events in cyberspace.”
Cyber threat intelligence provides a number of benefits, including:
Empowers organizations to develop a proactive cybersecurity posture and to bolster overall risk management policies.
Drives momentum toward a cybersecurity posture that is predictive, not just reactive.
Enables improved detection of threats.
Informs better decision-making during and following the detection of a cyber intrusion.
Today’s security drivers
Breached records
Human Error
IOT innovation
Breach cost amplifiers
Skills gap
Attackers break through conventional safeguards every day.
Threat Intelligence Strategy and External Sources
Threat Intelligence Strategy Map:
Sharing Threat Intelligence
“In practice, successful Threat Intelligence initiatives generate insights and actions that can help to inform the decisions – both tactical, and strategic – of multiple people and teams, throughout your organization.”
Threat Intelligence Strategy Map: From technical activities to business value:
Level 1 Analyst
Level 2/3 Analyst
Operational Leaders
Strategic Leaders
Intelligence Areas (CrowdStrike model)
Tactical:
Focused on performing malware analysis and enrichment, as well as ingesting atomic, static, and behavioral threat indicators into defensive cybersecurity systems.
Stakeholders:
SOC Analyst
SIEM
Firewall
Endpoints
IDS/IPS
Operation:
Focused on understanding adversarial capabilities, infrastructure, and TTPs, and then leveraging that understanding to conduct more targeted and prioritized cybersecurity operations.
Stakeholders:
Threat Hunter
SOC Analyst
Vulnerability Mgmt.
IR
Insider Threat
Strategic:
Focused on understanding high level trends and adversarial motives, and then leveraging that understanding to engage in strategic security and business decision-making.
Stakeholders:
CISO
CIO
CTO
Executive Board
Strategic Intel
Trends and Predictions
Threat Intelligence Platforms
“Threat Intelligence Platforms is an emerging technology discipline that helps organizations aggregate, correlate, and analyze threat data from multiple sources in real time to support defensive actions.”
These are made up of several primary feature areas that allow organizations to implement an intelligence-driven security approach.
Collect
Correlate
Enrichment and Contextualization
Analyze
Integrate
Act
Platforms
Recorded Future
On top of Recorded Future’s already extensive threat intelligence to provide a complete solution. Use fusion to centralize data, to get the most holistic and relevant picture of your threat landscape.
Features include:
Centralize and Contextualize all sources of threat data.
Collaborate on analysis from a single source of truth.
Customize intelligence to increase relevance.
FireEye
Threat Intelligence Subscriptions Choose the level and depth of intelligence, integration and enablement your security program needs.
Subscriptions include:
Fusion Intelligence
Strategic Intelligence
Operation Intelligence
Vulnerability Intelligence
Cyber Physical Intelligence
Cyber Crime Intelligence
Cyber Espionage Intelligence
IBM X-Force Exchange
IBM X-Force Exchange is a cloud-based threat intelligence sharing platform enabling users to rapidly research the latest security threats, aggregate actionable intelligence and collaborate with peers. IBM X-Force Exchange is supported by human and machine-generated intelligence leveraging the scale of IBM X-Force.
Access and share threat data
Integrate with other solutions
Boost security operations
TruSTAR
It is an intelligence management platform that helps you operationalize data across tools and teams, helping you prioritize investigations and accelerate incident response.
Streamlined Workflow Integrations
Secure Access Control
Advanced Search
Automated Data ingest and Normalization
Threat Intelligence Frameworks
Getting Started with ATT&CK
Adversarial Tactics, Techniques, and Common Knowledge (ATT&CK) can be useful for any organization that wants to move toward a threat-informed defense.
Level 2:
Understand ATT&CK
Find the behavior
Research the behavior into a tactic
Figure out what technique applies to the behavior
Compare your results to other analyst
Cyber Threat Framework
An integrated and intelligent security immune system
Best practices: Intelligent detection
Predict and prioritize security weaknesses
Gather threat intelligence information
Manage vulnerabilities and risks
Augment vulnerability scan data with context for optimized prioritization
Correlate logs, events, network flows, identities, assets, vulnerabilities, and configurations, and add context
Use automated and cognitive solutions to make data actionable by existing staff
Security Intelligence
“The real-time collection, normalization, and analytics of the data generated by users, applications, and infrastructure that impacts the IT security and risk posture of an enterprise.”
Security Intelligence provides actionable and comprehensive insights for managing risks and threats from protection and detection through remediation.
Ask the right questions – The exploit timeline
3 Pillars of Effective Threat Detection
See Everything
Automate Intelligence
Become Proactive
Security Effectiveness Reality
Key Takeaways
Data Loss Prevention and Mobile Endpoint Protection
What is Data Security and Protection?
Protecting the:
Confidentiality
Integrity
Availability
Of Data:
In transit
At rest
Databases
Unstructured Data (files)
On endpoints
What are we protecting against?
Deliberate attack:
Hackers
Denial of Service
Inadvertent attacks:
Operator error
Natural disaster
Component failure
Data Security Top Challenges
Explosive data growth
New privacy regulations (GDPR, Brazil’s LGPD etc.)
Operational complexity
Cybersecurity skills shortage
Data Security Common Pitfalls
Five epic fails in Data Security:
Failure to move beyond compliance
Failure to recognize the need for centralized data security
Failure to define who owns the responsibility for the data itself
Failure to address known vulnerabilities
Failure to prioritize and leverage data activity monitoring
Industry Specific Data Security Challenges
Healthcare
Process and store combination of personal health information and payment card data.
Subject to strict data privacy regulations such as HIPAA.
May also be subject to financial standards and regulations.
Highest cost per breach record.
Data security critical for both business and regulatory compliance.
Transportation
Critical part of national infrastructure
Combines financially sensitive information and personal identification
Relies on distributed IT infrastructure and third party vendors
Financial industries and insurance
Most targeted industry: 19% of cyberattacks in 2018
Strong financial motivation for both external and internal attacks
Among the most highly targeted groups for data breaches
Large number of access points in retail data lifecycle
Customers and associates access and share sensitive data in physical outlets, online, mobile applications
Capabilities of Data Protection
The Top 12 critical data protection capabilities:
Data Discovery
Where sensitive data resides
Cross-silo, centralized efforts
Data Classification
Parse discovered data sources to determine the kind of data
Vulnerability Assessment
Determine areas of weakness
Iterative process
Data Risk analysis
Identify data sources with the greatest risk exposure or audit failure and help prioritize where to focus first
Build on classification and vulnerability assessment
Data and file activity monitoring
Capture and record real-time data access activity
Centralized policies
Resource intensive
Real-time Alerting
Blocking Masking, and Quarantining
Obscure data and/or blocking further action by risky users when activities deviate from regular baseline or pre-defined policies
Provide only level of access to data necessary
Active Analytics
Capture insight into key threats such as, SQL injections, malicious stored procedures, DoS, Data leakage, Account takeover, data tampering, schema tampering etc
Develop recommendations for actions to reduce risk
Encryption
Tokenization
A special type of format-preserving encryption that substitutes sensitive data with a token, which can be mapped to the original value
Key Management
Securely distribute keys across complex encryption landscape
Centralize key management
Enable organized, secure key management that keeps data private and compliant
Automated Compliance Report
Pre-built capabilities mapped to specific regulations such as GDPR, HIPAA, PCI-DSS, CCPA and so on
Includes:
Audit workflows to streamline approval processes
Out-of-the-box reports
Pre-built classification patterns for regulated data
Tamper-proof audit repository
Data Protection – Industry Example
Guardium support the data protection journey
Guardium – Data Security and Privacy
Protect all data against unauthorized access
Enable organizations to comply with government regulations and industry standards
Mobile Endpoint Protection
iOS
Developed by Apple
Launched in 2007
~13% of devices (based on usage)
~60% of tablets worldwide run iOS/iPadOS
MDM capabilities available since iOS 6
Android
Android Inc. was a small team working on an alternative to Symbian and Windows Mobile OS.
Purchased by Google in 2005 – the Linux kernel became the base of the Android OS. Now developed primarily by Google and a consortium known as Open Handset Alliance.
First public release in 2008
~86% of smartphones and ~39% of tablets run some form of Android.
MDM capabilities since Android 2.2.
How do mobile endpoints differ from traditional endpoints?
Users don’t interface directly with the OS.
A series of applications act as a broker between the user and the OS.
OS stability can be easily monitored, and any anomalies reported that present risk.
Antivirus software can “see” the apps that are installed on a device, and reach certain signatures, but can not peek inside at their contents.
Primary Threats To Mobile Endpoints
System based:
Jailbreaking and Rooting exploit vulnerabilities to provide root access to the system.
Systems that were previously read-only can be altered in malicious ways.
One primary function is to gain access to apps that are not approved or booting.
Vulnerabilities and exploits in the core code can open devices to remote attacks that provide root access.
App based threats:
Phishing scams – via SMS or email
Malicious code
Apps may request access to hardware features irrelevant to their functionality
Web content in mobile browsers, especially those that prompt for app installations, can be the root cause of many attacks
External:
Network based attacks
Tethering devices to external media can be exploited for vulnerabilities
Social engineering to unauthorized access to the device
Protection mobile assets
MDM: Control the content allowed on the devices, restrict access to potentially dangerous features.
App security: Report on the health and reliability of applications, oftentimes before they even make it on the devices.
User Training
Day-to-day operations
While it may seem like a lot to monitor hundreds, thousands, or hundreds of thousands of devices daily, much of the information can be digested by automated systems and action taken without much admin interactions.
Scanning
Vulnerability Assessment Tools
“Vulnerability scanning identifies hosts and host attributes (e.g., OSs, applications, open ports), but it also attempts to identify vulnerabilities rather than relying on human interpretation of the scanning results. Vulnerability scanning can help identify outdated software versions, missing patches, and misconfigurations, and validate compliance with or deviation from an organization’s security policy.” — NIST SP 800-115
What is a Vulnerability Scanner?
Capabilities:
Keeping an up-to-date database of vulnerabilities.
Detection of genuine vulnerabilities without an excessive number of false positives.
Ability to conduct multiple scans at the same time.
Ability to perform trend analyses and create clear reports of the results.
Provide recommendations for effective countermeasures to eliminate discovered vulnerabilities.
Components of Vulnerability Scanners
There are 4 main components of most scanners:
Engine Scanner
Performs security checks according to its installed plug-ins, identifying system information, and vulnerabilities.
Report Module
Provides scan result reporting such as technical reports for system administrators, summary reports for security managers, and high-level graph and trend reports for corporate executives’ leadership.
Database
Stores vulnerability information, scan results, and other data used by the scanner.
User interface
Allows the admin to operate the scanner. It may be either a GUI, or just a CLI.
Host & Network
Internal Threats:
It can be through Malware or virus that is downloaded onto a network through internet or USB.
It can be a disgruntled employee who has the internal network access.
It can be through the outside attacker who has gained access to the internal network.
The internal scan is done by running the vulnerability scanner on the critical components of the network from a machine which is a part of the network. This important component may include core router, switches, workstations, web server, database, etc.
External Threats:
The external scan is critical as it is required to detect the vulnerabilities to those internet facing assets through which an attacker can gain internal access.
Common Vulnerability Scoring Systems (CVSS)
The CVSS is a way of assigning severity rankings to computer system vulnerabilities, ranging from zero (least severe) to 10 (most severe).
It provides a standardized vulnerability score across the industry, helping critical information flow more effectively between sections within an organization and between organizations.
The formula for determining the score is public and freely distributed, providing transparency.
It helps prioritize risk — CVSS rankings provide both a general score and more specific metrics.
Score Breakdown:
The CVSS score has three values for ranking a vulnerability:
A base score, which gives an idea of how easy it is to exploit targeting that vulnerability could inflict.
A temporal score, which ranks how aware people are of the vulnerability, what remedial steps are being taken, and whether threat actors are targeting it.
An environmental score, which provides a more customized metric specific to an organization or work environment.
STIGS – Security Technical Implementation Guides
The Defense Information Systems Agency (DISA) is the entity responsible for maintaining the security posture of the DoD IT infrastructure.
Default configurations for many applications are inadequate in terms of security, and therefore DISA felt that developing a security standard for these applications would allow various DoD agencies to utilize the same standard – or STIG – across all application instances that exist.
STIGs exist for a variety of software packages including OSs, DBAs, OSS, Network devices, Wireless devices, Virtual software, and, as the list continues to grow, now even include Mobile Operating Systems.
Center for Internet Security (CIS)
Benchmarks:
CIS benchmarks are the only consensus-based, best-practice security configuration guides both developed and accepted by government, business, industry, and academia.
The initial benchmark development process defines the scope of the benchmark and begins the discussion, creation, and testing process of working drafts. Using the CIS WorkBench community website, discussion threads are established to continue dialogue until a consensus has been reached on proposed recommendations and the working drafts. Once consensus has been reached in the CIS Benchmark community, the final benchmark is published and released online.
Controls:
The CIS ControlsTM are a prioritized set of actions that collectively form a defense-in-depth set of best practices that mitigate the most common attacks against systems and networks. The CIS Controls are developed by a community of IT experts who apply their first-hand experience as cyber defenders to create these globally accepted security best practices.
The five critical tenets of an effective cyber defense systems as reflected in the CIS Controls are:
Offense informs defense
Prioritization
Measurements and metrics
Continuous diagnostics and mitigation
Automation
Implementation Groups
20 CIS Controls
Port Scanning
“Network port and service identification involves using a port scanner to identify network ports and services operating on active hosts–such as FTP and HTTP–and the application that is running each identified service, such as Microsoft Internet Information Server (IIS) or Apache for the HTTP service. All basic scanners can identify active hosts and open ports, but some scanners are also able to provide additional information on the scanned hosts.” —NIST SP 800-115
Ports
Managed by IANA.
Responses
A port scanner is a simple computer program that checks all of those doors – which we will start calling ports – and responds with one of three possible responses:
Open — Accepted
Close — Not Listening
Filtered — Dropped, Blocked
Types of Scans
Port scanning is a method of determining which ports on a network are open and could be receiving or sending data. It is also a process for sending packets to specific ports on a host and analyzing responses to identify vulnerabilities.
Ping:
Simplest port scan sending ICMP echo request to see who is responding
TCP/Half Open:
A popular, deceptive scan also known as SYN scan. It notes the connection and leaves the target hanging.
TCP Connect:
Takes a step further than half open by completing the TCP connection. This makes it slower and noisier than half open.
UDP:
When you run a UDP port scan, you send either an empty packet or a packet that has a different payload per port, and will only get a response if the port is closed. It’s faster than TCP, but doesn’t contain as much data.
Stealth:
These TCP scans are quieter than the other options and can get past firewalls. They will still get picked by the most recent IDS.
Tools – NMAP
NMAP (Network Mapper) is an open source tool for network exploration and security auditing.
Design to rapidly scan large networks, though work fine against single hosts.
Uses raw IP packets.
Used to know, service type, OS type and version, type of packet filter/firewall in use, and many other things.
Also, useful for network inventory, managing service upgrade schedules, and monitoring host or service uptime.
ZenMap is a GUI version of NMAP.
Network Protocol Analyzers
“A protocol analyzer (also known as a sniffer, packet analyzer, network analyzer, or traffic analyzer) can capture data in transit for the purpose of analysis and review. Sniffers allow an attacker to inject themselves in a conversation between a digital source and destination in hopes of capturing useful data.”
Sniffers
Sniffers operate at the data link layer of the OSI model, which means they don’t have to play by the same rules as the applications and services that reside further up the stack. Sniffers can capture everything on the wire and record it for later review. They allow user’s to see all the data contained in the packet.
Wireshark
WireShark
Wireshark intercepts traffics and converts that binary traffic into human-readable format. This makes it easy to identify what traffic is crossing your network, how much of it, how frequently, how much latency there is between certain hops, and so on.
Network Admins use it to troubleshoot network problems.
Network Security Engineers use it to examine security issues.
QA engineers use it to verify network applications.
Developers use it to debug protocol implementations.
People use it to learn network protocol internals.
WireShark Features
Deep inspection of hundred of protocols, with more being added all the time
Live capture and offline analysis
Standard three pane packet browser
Cross-platform
GUI or TTY-mode – TShark utility
Powerful display filters
Rich VoIP analysis
Read/write to different formats
Capture compressed file with gzip
Live data from any source
Decryption support for many protocols
Coloring rules
Output can be exported to different formats
Packet Capture (PCAP)
PCAP is a valuable resource for file analysis and to monitor network traffic.
Monitoring bandwidth usage
Identify rogue DHCP servers
Detecting Malware
DNS resolution
Incident Response
Wireshark is the most popular traffic analyzer in the world. Wireshark uses .pcap files to record packet data that has been pulled from a network scan. Packet data is recorded in files with the .pcap file extension and can be used to find performance issues and cyberattacks on the network.
Security Architecture considerations
Characteristics of a Security Architecture
The foundation of robust security is a clearly communicated structure with a systematic analysis of the threats and controls.
Build with a clearly communicated structure
Use systematic analysis of threats and controls
As IT systems increase in complexity, they require a standard set of techniques, tools, and communications.
Architectural thinking is about creating and communicating good structure and behavior with the intent of avoiding chaos.
Architecture need to be:
Described before it can be created
With different level of elaboration for communication
Include a solution for implementation and operations
That is affordable
And is secure
Architecture: “The architecture of a system describes its overall static structure and dynamic behavior. It models the system’s elements (which for IT systems are software, hardware and its human users), the externally manifested properties of those elements, and the static and dynamic relationships among them.”
ISO/IEC 422010:20071 defines Architecture as “the fundamental organization of a system, embodied in its components, their relationships to each other and the environment, and the principles governing its design and evolution.”
High-level Architectural Models
Enterprise and Solution Architecture break down the problem, providing different levels of abstraction.
High-level architectures are described through Architectural Building Blocks (ABBs) and Solution Building Blocks (SBBs).
Here are some example Security ABBs and SBBs providing different levels of abstraction aimed at a different audience.
Here is a high level example of an Enterprise Security Architecture for hybrid multicloud showing security domains.
The Enterprise Security Architecture domains could be decomposed to show security capabilities… without a context.
Adding context gives us a next level Enterprise Architecture for hybrid multi-cloud, but without specific implementation.
Solution Architecture
Additional levels of abstraction are used to describe architectures down to the physical operational aspects.
Start with a solution architecture with an Architecture Overview giving an overview of the system being developed.
Continue by clearly defining the external context describing the boundary, actors and use that process data.
Examine the system internally looking at the functional components and examine the threats to the data flows.
Finally, look at where the function is hosted, the security zones and the specific protection required to protect data.
As the architecture is elaborated, define what is required and how it will be delivered?
Security Patterns
The use of security architecture patterns accelerate the creation of a solution architecture.
A security Architecture pattern is
a reusable solution to a commonly occurring problem
it is a description or template for how to solve a problem that can be used in many different situations
is not a finished design as it needs conext
it can be represented in many different formats
Vendor specific or agnostic
Available at all levels of abstraction
There are many security architecture patterns available to provide a good starting point to accelerate development.
Application Security Techniques and Risks
Application Security Overview
Software Development Lifecycle
Penetration Testing Tools
Source Code Analysis Tools
Application Security Threats and Attacks
Third Party Software
Standards
Patching
Testing
Supplier Risk Assessment
Identify how any risks would impact your organization’s business. It could be a financial, operational or strategic risk.
Next step would be to determine the likelihood the risk would interrupt the business
And finally there is a need to identify how the risk would impact the business.
Web Application Firewall (WAF)
Application Threats/Attacks
Input Validation:
Buffer overflow
Cross-site scripting
SQL injection
Canonicalization
Authentication:
Network eavesdropping
Brute force attack
Dictionary attacks
Cookie replay
Credential theft
Authorization:
Elevation of privilege
Disclosure of confidential data
Data tampering
Luring Attacks
Configuration Management:
Unauthorized access to admin interface
Unauthorized access to configuration stores
Retrieval of clear text configuration data
Lack of individual accountability; over-privileged process and service accounts
Exception Management:
Information disclosure
DoS
Auditing and logging:
User denies performing an operation
Attacker exploits an application without trace
Attacker covers his tracks
Application Security Standards and Regulations
Threat Modeling
“Threat modeling is a process by which potential threats, such as structural vulnerabilities or the absence of appropriate safeguards, can be identified, enumerated, and mitigations can be prioritized.”
Conceptually, a threat modeling practice flows from a methodology.
STRIDE methodology: STRIDE is a methodology developed by Microsoft for threat modeling. It provides a mnemonic for security threats in six categories: Spoofing, Tampering, Repudiation, Information disclosure, Denial of service and Elevation of privilege.
Microsoft developed it
P.A.S.T.A: P.A.S.T.A. stands for Process for Attack Simulation and Threat Analysis. It is an attacker-focused methodology that uses a seven-step process to identify and analyze potential threats.
Seven-step process
VAST: VAST is an acronym for Visual, Agile, and Simple Threat modeling. The methodology provides actionable outputs for the unique needs of various stakeholders like application architects and developers.
Trike: Trike threat modeling is an open-source threat modeling methodology focused on satisfying the security auditing process from a cyber risk management perspective. It provides a risk-based approach with unique implementation and risk modeling process.
Standards vs Regulations
Standards
Regulations
Cert Secure Coding
Common Weakness Enumeration (CWE)
Gramm-Leach-Bliley Act
DISA-STIG
HIPAA
ISO 27034/24772
Sarbanes-Oxley Act (SOX)
PCI-DSS
NIST 800-53
DevSecOps Overview
Why this matter?
Emerging DevOps teams lead to conflicting objectives.
DevSecOps is an integrated, automated, continuous security; always.
Integrating Security with DevOps to create DevSecOps.
What does DevSecOps look like?
Define your operating and governance model early.
A successful program starts with the people & culture.
Training and Awareness
Explain and embrace new ways of working
Equip teams & individuals with the right level of ownership & tools
Continuous improvement and feedback.
Develop Securely: Plan A security-first approach
Use tools and techniques to ensure security is integral to the design, development, and operation of all systems.
Enable empowerment and ownership by the Accreditor/Risk owner participating in Plan & Design activities.
Security Coach role to drive security integration.
Develop Security: Code & Build Security & Development combined
Apply the model to Everything-as-Code:
Containers
Apps
Platforms
Machines
Shift security to the left and embrace security-as-code.
Security Engineer to drive technical integration and uplift team security knowledge.
Develop Securely: Code & Build
Detect issues and fix them, earlier in the lifecycle
Develop Securely: Test
Security and development Combined
Validate apps are secure before release & development.
DevSecOps Deployment
Secure Operations: Release, Deploy & Decom
Orchestrate everything and include security.
Manage secure creation and destruction of your workloads.
Automate sign-off to certified levels of data destruction.
Controlled creation & destruction
Create securely, destroy securely, every time.
Secure Operations: Operate & Monitor
If you don’t detect it, you can’t fix it.
Integrated operational security helps ensure the security health of the system is as good as it can be with the latest information.
Playbooks-as-code run automatically, as issues are detected they are remediated and reported on.
Security & Operations combined
It’s not a question of if you get hacked, but when.
“At its core, System Information Event Management (SIEM) is a data aggregator, search and reporting system. SIEM gathers immense amounts of data from your entire networked environment, consolidates and makes that data human accessible. With the data categorized and laid out at your fingertips, you can research data security breaches with as much detail as needed.”
Key Terms:
Log collection
Normalization
Correlation
Aggregation
Reporting
SIEM
A SIEM system collects logs and other security-related documentation for analysis.
The core function to manage network security by monitoring flows and events.
It consolidates log events and network flow data from thousands of devices, endpoints, and applications distributed throughout a network. It then uses an advanced Sense Analytics engine to normalize and correlate this data and identifies security offenses requiring investigation.
A SIEM system can be rules-based or employ a statistical correlation between event log entries.
Capture log event and network flow data in near real time and apply advanced analytics to reveal security offenses.
It can be available on premises and in a cloud environment.
Events & Flows
Events
Flows
Typically is a log of a specific action such as a user login, or a FW permit, occurs at a specific time and the event is logged at that time
A flow is a record of network activity between two hosts that can last for seconds to days depending on the activity within the session.
For example, a web request might download multiple files such as images, ads, video, and last for 5 to 10 seconds, or a user who watches a NetFlix movie might be in a network session that lasts up to a few hours.
Data Collection
It is the process of collecting flows and logs from different sources into a common repository.
It can be performed by sending data directly into the SIEM or an external device can collect log data from the source and move it into the SIEM system on demand or scheduled.
To consider:
Capture
Memory
Storage capacity
License
Number of sources
Normalization
The normalization process involves turning raw data into a format that has fields such as IP address that SIEM can use.
Normalization involves parsing raw event data and preparing the data to display readable information.
Normalization allows for predictable and consistent storage for all records, and indexes these records for fast searching and sorting.
License Throttling
Monitors the number of incoming events to the system to manage input queues and EPS licensing.
Coalescing
Events are parsed and then coalesced based on common attributes across events. In QRadar, Event coalescing starts after three events have been found with matching properties within a 10-second period.
Event data received by QRadar is processed into normalized fields, along with the original payload. When coalescing is enabled, the following five properties are evaluated.
QID
Source IP
Destination IP
Destination port
Username
SIEM Deployment
SIEM Deployment Considerations
Compliance
Cost-benefit
Cybersecurity
QRadar Deployment Examples
Events
Event Collector:
The event collector collects events from local and remote log sources, and normalize raw log source events to format them for use by QRadar. The Event Collector bundles or coalesces identical events to conserve system usage and send the data to the Event Processor.
The Event Collector can use bandwidth limiters and schedules to send events to the Event Processor to overcome WAN limitations such as intermittent connectivity.
Event Processor:
The Event Processor processes events that are collected from one or more Event Collector components.
Processes events by using the Custom Rules Engine (CRE).
Flows
Flow Collector:
The flow collector generates flow data from raw packets that are collected from monitor ports such as SPANS, TAPS, and monitor sessions, or from external flow sources such as netflow, sflow, jflow.
This data is then converted to QRadar flow format and sent down the pipeline for processing.
Flow Processor:
Flow deduplication: is a process that removes duplicate flows when multiple Flow Collectors provide data to Flow Processors appliances.
Asymmetric recombination: Responsible for combining two sides of each flow when data is provided asymmetrically. This process can recognize flows from each side and combine them in to one record. However, sometimes only one side of the flow exists.
License throttling: Monitors the number of incoming flows to the system to manage input queues and licensing.
Forwarding: Applies routing rules for the system, such as sending flow data to offsite targets, external Syslog systems, JSON systems, other SIEMs.
Reasons to add event or flow collectors to an All-in-One deployment
Your data collection requirements exceed the collection capability of your processor.
You must collect events and flows at a different location than where your processor is installed.
You are monitoring packet-based flow sources.
As your deployment grows, the workload exceeds the processing capacity of the All-in-One appliance.
Your security operations center employs more analytics who do more concurrent searches.
The types of monitored data, and the retention period for that data, increases, which increases processing and storage requirements.
As your security analyst team grows, you require better search performance.
Security Operations Center (SOC)
Triad of Security Operations: People, Process and Technology.
SOC Data Collection
SIEM Solutions – Vendors
“The security information and event management (SIEM) market is defined by customers’ need to analyze security event data in real-time, which supports the early detection of attacks and breaches. SIEM systems collect, store, investigate, support mitigation and report on security data for incident response, forensics and regulatory compliance. The vendors included in this Magic Quadrant have products designed for this purpose, which they actively market and sell to the security buying center.”
Deployments
Small:
Gartner defines a small deployment as one with around 300 log sources and 1500 EPS.
Medium:
A midsize deployment is considered to have up to 1000 log sources and 7000 EPS.
Large:
A large deployment generally covers more than 1000 log sources with approximately 15000 EPS.
Important Concepts
IBM QRadar
IBM QRadar Components
ArcSight ESM
Splunk
Friendly Representation
LogRythm’s Security Intelligence Platform
User Behavior Analytics
Security Ecosystem
Detecting insider threats requires a 360 degree view of both logs and flows.
Advantages of an integrated UBA Solution
Complete visibility across end point, network and cloud infrastructure with both log and flow data.
Avoids reloading and curating data faster time to insights, lowers opex, frees valuable resources.
Out-of-the-box analytics models that leverage and extend the security operations platform.
Single Security operation processes with integration of workflow system and other security solutions.
Easily extend to third-party analytic models, including existing insider threats use cases already implemented.
Leverage UBA insights in other integrated security analytics solutions.
Get more from your QRadar ecosystem.
IBM QRadar UBA
160+ rules and ML driven use cases addressing 3 major insider threat vectors:
Compromised or Stolen Credentials
Careless or Malicious Insiders
Malware takeover of user accounts
Detecting Compromised Credentials
70% of phishing attacks are to steal credentials.
81% of breaches are with stolen credentials.
$4M average cost of a data breach.
Malicious behavior comes in many forms
Maturing into User Behavioral Analytics
QRadar UBA delivers value to the SOC
AI and SIEM
Your goals as a security operations team are fundamental to your business.
Pressures today make it difficult to achieve your business goals.
Challenge #1: Unaddressed threats
Challenge #2: Insights Overload
Challenge #3: Dwell times are getting worse
Lack of consistent, high-quality and context-rich investigations lead to a breakdown of existing processes and high probability of missing crucial insights – exposing your organization to risk.
Challenge #4: Lack of cybersecurity talent and job fatigue
Overworked
Understaffed
Overwhelmed
Investigating an Incident without AI:
Unlock a new partnership between analysts and their technology:
AI and SIEM – An industry Example
QRadar Advisor with Watson:
Built with AI for the front-line Security Analyst.
QRadar Advisor empowers security analysts to drive consistent investigations and make quicker and more decisive incident escalations, resulting in reduced dwell times, and increased analyst efficiency.
Benefits of adopting QRadar Advisor:
How it works – An app that takes QRadar to the next level:
How it works – Building the knowledge (internal and external)
How it works – Aligning incidents to the ATT&CK chain:
How it works – Cross-investigation analytics
How it works – Using analyst feedback to drive better decisions
How it works – QRadar Assistant
Threat Hunting Overview
Fight and Mitigate Upcoming Future Attacks with Cyber Threat Hunting
Global Cyber Trends and Challenges
Cybercrime will/has transform/ed the role of Citizens, Business, Government, law enforcement ad the nature of our 21st Century way of life.
We depend more than ever on cyberspace.
A massive interference with global trade, travel, communications, and access to databases caused by a worldwide internet crash would create an unprecedented challenge.
The Challenges:
The Rise of Advanced Threats
Highly resourced bad guys
High sophisticated
Can evade detection from rule and policy based defenses
Dwell in the network
Can cause the most damage
The threat surface includes:
Targeted ‘act of war’ & terrorism
Indirect criminal activities designed for mass disruption
Targeted data theft
Espionage
Hacktivists
Countermeasures challenges include:
Outdated security platforms
Increasing levels of cybercrime
Limited marketplace skills
Increased Citizen expectations
Continuous and ever-increasing attack sophistication
The act of proactively and aggressively identifying, intercepting, tracking, investigating, and eliminating cyber adversaries as early as possible in the Cyber Kill Chain.
The earlier you locate and track your adversaries Tactics, Techniques, and Procedures (TTPs) the less impact these adversaries will have on your business.
Multidimensional Trade craft: What is the primary objective of cyber threat hunting?
Know Your Enemy: Cyber Kill Chain
The art and Science of threat hunting.
Advance Your SOC:
Cyber Threat Hunting – An Industry Example
Cyber threat hunting team center:
Build a Cyber Threat Hunting Team:
Six Key Use Cases and Examples of Enterprise Intelligence:
i2 Threat Hunting Use Cases:
Detect, Disrupt and Defeat Advanced Threats
Know Your Enemy with i2 cyber threat analysis:
Intelligence Concepts are a Spectrum of Value:
i2 Cyber Users:
Cybersecurity Capstone: Breach Response Case Studies
Disclaimer: Expand me…
Dear Stranger;
I would like to thank you for taking an interest in my project, which I have shared on GitHub as a part of my specialization course. While I am happy to share my work with others, I would like to emphasize that this project is the result of my own hard work and effort, and I would like it to be used solely for the purpose of reference and inspiration.
Therefore, I strongly advise against any unethical use of my project, such as submitting it as your own work or copying parts of it to gain easy grades. Plagiarism is a serious offense that can result in severe consequences, including academic penalties and legal action.
I would like to remind you that the purpose of sharing my project is to showcase my skills and knowledge in a specific subject area. I encourage you to use it as a reference to understand the concepts and techniques used, but not to copy it verbatim or use it in any unethical manner.
In conclusion, I ask you to respect my work and use it ethically. Please do not plagiarize or copy my project, but rather use it as a source of inspiration to create your own unique and original work.
Cybersecurity Specialization is an advanced course offered by University of Maryland. It dives deep into the core topics related to software security, cryptography, hardware etc.
Info
My progress in this specialization came to a halt after completing the first course, primarily because the subsequent courses were highly advanced and required background knowledge that I lacked. I will resume my journey once I feel confident in possessing the necessary expertise to tackle those courses.
1. Usable Security
This course is all about principles of Human Computer Interaction, designing secure systems, doing usability studies to evaluate the most efficient security model and much more…
Fundamentals of Human-Computer Interaction: users, usability, tasks, and cognitive models
What is Human Computer Interaction?
“HCI is a study of how humans interact with the computers.”
It is important to keep in mind how humans interact with the machines.
Cybersecurity experts, designers etc. should always consider HCI element as the major proponent for design and security infrastructure.
HCI involves knowing the users, tasks, context of the tasks.
Evaluation of how easy/difficult it is to use the system.
Usability
“It is a measure of how easy it is to use a system for a user.”
Measuring Usability
Speed
How quickly can the task be accomplished.
Efficiency
How many mistakes are made in accomplishing the task.
Learnability
How easy is it to learn to use the system.
Memorability
Once learned, how easy is it to remember how to use the system.
User Preference
What do users like?
How do we measure Usability?
Speed – timing
Efficiency – counting error
Learnability, Memorability and User Preference don’t have straight forward measurement tools.
Tasks and Task analysis
“Tasks are goals that users have when interacting with the system.”
Common errors in task creation
Leading or too descriptive
Click on the username box at the upper right of the screen and enter your username, then click on the password box underneath and enter your password. Click submit…
Specific questions?
What is the third headline on CNN.com?
Directing users towards things you want to tell them, not what they want to know.
What are the names of the members of the website security team?
Chunking Information
“Breaking a long list of pieces of information into smaller groups.”
“Aggregating several pieces of information into coherent groups to make them easier to remember.”
When designing systems, the most important thing to consider is human memory, as it is very volatile.
Working memory’s limitations should be kept in mind.
For design technology products, we should not expect user to remember more than 3 things at a time in his/her working memory.
Mental Models
Number of factors affecting mental models;
Affordance
Mapping
Visibility
Feedback
The user sees some visual change when they click a button.
Constraints
A user should not be allowed to perform a task until certain conditions are met.
Conventions
There are some conventions in place, for cross culture usability.
Design: design methodology, prototyping, cybersecurity case study
Intro to Design
Have the insight of the users who are they.
To include children or not.
Testing your design with users.
Involving the users from the very start of your design.
What other people are doing in your niche, and you should probably design something similar for familiarity reasons of mental models
Define your goal, is it an innovative idea, or something already existing but adding a value over it.
Don’t wait until your product is finished, take input from the users from the very first stage of design.
Design Methodologies
Design Process
The Golden rule is;
Know Your User.
Where do ideas come from?
Many processes;
Iterative design
System centered design
What can be built easily on this platform?
What can I create from the available tools?
What do I as a programmer find interesting to work on?
User centered design
Design is based upon a user’s
Abilities and real needs
Context
Work
Tasks
Participatory design
Problem
intuitions wrong
interviews etc. not precise
designer cannot know the user sufficiently well to answer all issues that come up during the design
Solution
designers should have access to a pool of representative users. That is, END users, not their managers or union reps!
Designer centered design
“It’s not the consumers’ job to know what they want.”
— Steve Jobs
Case Study: SSL Warnings – example user
User knows something bad is happening, but not what.
User has good general strategies (worry more about sites with sensitive info)
Error message relies on a lot of information users don’t understand
Evaluation: usability studies, A/B testing, quantitative and qualitative evaluation, cybersecurity case study
Quantitative Evaluation
Cognitive Walkthrough
Requirements;
Description or prototype of interface
Task Description
List of actions to complete task
Use background
What you look for; (A mobile Gesture prototype)
Will users know to perform the action?
Will users see the control
Will users know the control does what they want?
Will users understand the feedback?
Heuristic Analysis
Follow ‘rules of thumb’ or suggestions about good design.
Can be done by experts/designers, fast and easy.
May miss problems users would catch.
Nielsen’s Heuristics
Simple and natural dialog
Speak the users’ language
Minimize user memory load
Consistency
Feedback
Clearly marked exits
Shortcuts
Prevent errors
Good error messages
Providing help and documentation
Personas
A fictitious user representing a class of users
Reference point for design and analysis
Has a goal or goals they want to accomplish (in general or in the system)
Running Controlled Experiments
State a lucid, testable hypothesis.
Identify independent and dependent variables
Design the experimental protocol
Choose the user population
Run some pilot participants
Fix the experimental protocol
Run the experiment
Perform statistical analysis
Draw conclusion
Communicate results
Analysis
Statistical comparison (e.g., t-test)
Report results
Usability Studies
Testing Usability of Security
Security is rarely the task users set out to accomplish.
Good Security is a seamless part of the task.
Usability Study Process
Define tasks (and their importance)
Develop Questionnaires
Selecting Tasks
What are the most important things a user would do with this interface?
Present it as a task not a question
Be specific
Don’t give instructions
Don’t be vague or provide tiny insignificant tasks
Choose representative tasks that reflect the most important things a user would do with the interface
Security Tasks
Security is almost never a task
Pre-Test Questionnaires
Learn any relevant background about the subject’s
Age, gender, education level, experience with the web, experience with this type of website, experience with this site in particular.
Perhaps more specific questions based on the site, e.g., color blindness, if the user has children, etc.
Post-Test Questionnaires
Have users provide feedback on the interface.
Evaluation
Users are given a list of tasks and asked to perform each task.
Interaction with the user is governed by different protocols.
Observation Methods
Silent Observer
Think Aloud
Constructive Interaction
Interview
Ask users to give you feedback
Easier for the user than writing it down
They will tell you, things, you never thought to ask
Reporting
After the evaluation, report your results
Summarize the experiences of users
Emphasize your insights with specific examples or quotes
Offer suggestions for improvement for tasks that were difficult to perform
A/B Testing
Doesn’t include any Cognitive or psychological understanding or model of user behavior.
You give two options, A or B, and measure how they perform.
How to Run A/B Test
Start with a small percentage of visitors trying the experimental conditions.
Automatically stop testing if any condition has very bad performance.
Let people consistently see the same variation so, they don’t get confused.
Strategies for Secure Interaction Design: authority, guidelines for interface design
Strategies for Secure Interaction Design: authority, guidelines for interface design
It’s the user who is making security decision, so, keep user in mind when designing security systems.
Authority Guidelines
Match the easiest way to do a task with the least granting of authority.
What are typical user tasks?
What is the easiest way for the user to accomplish each task?
What authority is granted to software and other people when the user takes the easiest route to completing the task?
How can the safest ways of accomplishing the task be made easier and vice versa?
Grant authority to others in accordance with user actions indicating consent.
When does the system give access to the user’s resources?
What user action grants that access?
Does the user understand that the action grants access?
Offer the user ways to reduce other’s authority to access the user’s resources.
What kind of access does the user grant to software and other users?
Which types of access can be revoked?
How can the interface help the user find and revoke access?
Authorization and Communication Guidelines
Users should know what authority other’s have.
What kind of authority can software and other users hold?
What kind of authority impact user decisions with security consequences?
How can the interface provide timely access to information about these authorities?
User should know what authority they themselves have.
What kind of authority does the user hold?
How does the user know they have that authority?
What might the user decide based on their expectation of authority?
Make sure the user trust the software acting on their behalf.
What agents manipulate authority on the user’s behalf?
How can users be sure they are communicating with the intended agent?
How might the agent be impersonated?
How might the user’s communication with the agent be corrupted/intercepted?
Interface Guidelines for Usable Security
Enable the user to express safe security policies that fit the user’s task.
What are some examples of security policies that users might want enforced for typical tasks?
How can the user express these policies?
How can the expression of policy be brought closer to the task?
Draw distinction among objects and actions along boundaries relevant to the task.
At what level of details does the interface allow objects and actions to be separately manipulated?
What distinction between affected objects and unaffected objects does the user care about?
Present objects and actions using distinguishable, truthful appearances.
How does the user identify and distinguish different objects and actions?
In what ways can the means of identification be controlled by other parties?
What aspects of an object’s appearances are under system control?
How can those aspects be chosen to best prevent deception?
DevOps is not a tool or a job title. It is a shared mindset.
Embrace the DevOps Culture.
#1 reason why DevOps fails is due to issues around organizational learning and cultural change.
DevOps is not a tool or a job title. It is a shared mindset.
“Tools are not the solution to a cultural problem.”
– Gartner
“Team culture makes a large difference to a team’s ability to deliver software and meet or exceed their organizational goals.”
– Accelerate State of DevOps 2021
How to change a Culture
Think Differently
Social Coding
Work in small batches
Minimum viable product
Work Differently
Team culture makes a large difference to a team’s ability to deliver software and meet or exceed their organizational goals.
Organize Differently
Measure Differently
Measure what matters
You get what you measure
Business Case For DevOps
Disruptive Business model:
52% of the Fortune 500 have disappeared since the year 2000.
When disruption happen, businesses need to adopt according no matter what, and this adaptation should be agile and lean.
Digitization + Business Model:
Technology is the enabler of innovation, not the driver of innovation.
The Businesses, who adapt to new tech, survive.
The refusal to change according to the digital ages makes it susceptible to bankruptcy.
DevOps Adoption
Unlearn what you have Learned
A different mindset
Unlearn your current culture
Often easier said than done
Consider this:
fail fast and roll back quickly
test in market instead of analyzing
modular design which makes individual components replaceable
How are they doing this?
What is their secret?
They have embraced the DevOps culture.
Definition of DevOps
The term (development and operations) is an extension of agile development environments that aims to enhance the process of software delivery as a whole.
— Patrick Debois, 2009
DevOps defined:
Recognition that working in silos doesn’t work
Development and operations engineers working together
Following lean and agile principles
Delivering software in a rapid and continuous manner
DevOps requires:
A change in culture
A new application design
Leveraging automation
Programmable platform
What DevOps not:
Not simply combining development and operations
Not a separate team
Not a tool
Not one size fits all
Not just automation
Essential Characteristics of DevOps
What’s the Goal?
Agility is the goal:
Smart experimentation
Moving in market
With maximum velocity and minimum risk
Gaining quick, valuable insights
Agility: The Three pillars
DevOps:
Cultural change
Automated pipeline
infrastructure as code
immutable infrastructure
Microservices:
Loose coupling/binding
RESTful APIs
Designed to resist failures
Test by breaking/fail fast
Containers
portability
Developer centric
Ecosystem enabler
Fast startup
The Perfect Combination/Storm
DevOps for speed and agility
Microservices for small deployments
Containers for ephemeral runtimes
Learning how to work differently
“DevOps starts with learning how to work differently. It embraces cross-functional teams with openness, transparency, and respect as pillars.”
— Tony Stafford, Shadow Soft.
Application Evolution
DevOps has three dimensions:
Responsibility, transparency, feedback:
“Culture is the #1 success factor in DevOps. Building a culture of shared responsibility, transparency, and faster feedback is the foundation of every high-performing DevOps team.”
— Atlassian
Culture, culture, culture:
While tools and methods are important;
… it’s the culture that has the biggest impact.
How to change a Culture?
-Change thinking patterns of people
working methodology as well as environment
Organizational change.
Change of the way people are measured.
Leading Up to DevOps
Architects worked for months designing the system.
Development worked for months on features.
Testing opened defects and sent the code back to development.
At some point, the code is released to operations.
The operations team took forever to deploy.
Traditional Waterfall Method
Problems with Waterfall Approach
No room for change
No idea if it works till end
Each step ends when the next begins
Mistakes found in the later stages are more expensive to fix
Long time between software releases
Team work separately, unaware of their impact on each other
Least familiar people with the code are deploying it into production
XP, Agile, and Beyond
Extreme Programming (XP)
In 1996, Kent Beck introduced Extreme Programming
Based on an interactive approach to software development
Intended to improve software quality, responsiveness to changing customer requirements
One of the first Agile methods
The Agile Manifesto
We have come to value:
Individuals and interactions over processes and tools
Working Software over comprehensive docs
Customer collaboration over contract negotiation
Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
Agile Development
Agile alone is not good enough:
2 Speed IT:
This is how Shadow IT started, as Ops team wasn’t meeting their needs.
Shadow IT
Resources the business doesn’t know about
People go around IT
We need the solution to this problem, and DevOps is the answer
Brief History of DevOps
2007 Patrick Debois:
He recognized Dev and Ops worked ineffectively and not together.
2008 Agile Conference:
Andrew Clay Shafer – Agile Conference 2008 BoF (Birds of a Feather) meeting “Agile Infrastructure”
2009 Velocity 10+ deploys per day:
John Allspaw – Velocity 2009 “10+ Deploys Per Day: Dev and Ops Cooperation at Flickr”
DevOpsDays – Patrick Debois started the first DevOpsDays conference Ghent, Belgium, October 2009
2010 Continuous Delivery:
Continuous Delivery – by Jez Humble and David Farley
2013 The Phoenix Project:
The Phoenix Project – by Gene Kim, Kevin Behr and George Spafford
2015 State of DevOps Report:
State of DevOps Reports – from DevOps Research and Assessment (DORA), founded by Dr. Nicole Forsgren, Gene Kim, and Jez Humble
2016 The DevOps Handbook:
The DevOps Handbook – by Gene Kim, Jez Humble, Patrick Debois, and John Willis
2019 10 Years of DevOpsDays:
DevOpsDays – 40 events in 21 countries are scheduled for 2019 (10 years later)
Patrick Debois (lead 2009-15)
Bridget Kromhout (lead 2015-2020)
Why is the history significant?
It reminds us that DevOps is:
From the practitioners, by practitioners
Not a product, specification, or job title
An experience-based movement
Decentralized and open to all
Thinking DevOps
Social Coding Principles
What is social coding?
Open source practice
All repos are public
Everyone is encouraged to contribute
Anarchy is controlled via Pull Requests
Code reuse dilemma:
Code has 80% of what you need, but 20% is missing
How do you add 20% missing features?
Make a feature request and depend on another team?
Rebuild 100% of what you need (no dependencies)
Social Coding Solution:
Discuss with the repo owner
Agree to develop it
Open an Issue and assign it to yourself
Fork the code and make your changes
Issue a Pull Request to review and merge back
Pair Programming:
Two programmers on one workstation
The driver is typing
The navigator is reviewing
Every 20 minutes they switch roles
Pair programming benefits:
Higher code quality
Defects found earlier
Lower maintenance costs
Skills transfer
Two set of eyes on every line of codebase
Git Repository Guidelines
Create a separate Git repository for every component
Create a new branch for every Issue
Use PRs to merge to master
Every PR is an opportunity for a code review
Git feature branch workflow:
Working in Small Batches
Concept from Lean Manufacturing
Faster feedback
Supports experimentation
Minimize waste
Deliver faster
Small batch example:
You need to mail 1000 brochures:
Step 1: Fold brochures
Step 2: Insert brochures into envelopes
Step 3: Seal the envelopes
Step 4: Stamp the envelopes with postage
Batch of 50 brochures:
Single Piece Flow:
Measuring the size of batches
Feature size supports frequent releases
Features should be completed in a sprint
Features are a step toward a goal, so keep them small
Minimum Viable Product (MVP)
MVP is not “Phase 1” of a project
MVP is an experiment to test your value hypothesis and learn
MVP is focused on learning, not delivery
At the end of each MVP, you decide whether to pivot or persevere
Minimum Viable Product Example:
Gaining an understanding
MVP is a tool for learning
The experiment may fail and that’s okay
Failure leads to understanding
What did you learn from it?
What will you do differently?
Test Driven Development (TDD)
The importance of testing:
“If it’s worth building, it’s worth testing. If it’s not worth testing, why are you wasting your time working on it?”
— Scott Ambler
What is test driven development?
Test cases drive the design
You write the tests first then you write the code to make the test pass
This keeps you focused on the purpose of the code
Code is of no use if your client can’t call it
Why devs don’t test:
I already know my code works
I don’t write broken code
I have no time
Basic TDD workflow
Why is TDD important for DevOps?
It saves time when developing
You can code faster and with more confidence
It ensures the code is working as expected
It ensures that future changes don’t break your code
In order to create a DevOps CI/CD pipeline, all testing must be automated
Behavior Driven Development (BDD)
Describes the behavior of the system from the outside
Great for integration testing
Uses a syntax both devs and stakeholders can easily understand
BDD vs. TDD:
BDD ensures that you’re building the “right thing”
TDD ensures that you are building the “thing right”
BDD workflow
Explore the problem domain and describe the behavior
Document the behavior using Gherkin syntax
Use BDD tools to run those scenarios
One document that’s both the specification and the tests
Gherkin:
An easy-to-read natural language syntax
Given … When… Then…
Understandable by everyone
Gherkin Syntax:
Given (some context)
When (some event happens)
Then (some testable outcome)
And (more context, events, or outcomes)
Retail BDD example
Gherkin for acceptance criteria:
Add acceptance criteria to every user story
Use Gherkin to do that
Indisputable definition of “done”
Expected benefits of BDD
Improves communication
More precise guidance
Provides a common syntax
Self-documenting
Higher code quality
Acceptance criteria for user stories
Cloud Native Microservices
Think differently about application design:
Think cloud native:
The Twelve-Factor App
A collection of stateless microservices
Each service maintains its own database
Resilience through horizontal scaling
Failing instances are killed and respawned
Continuous Delivery of services
Think microservices:
“The microservices architectural style is an approach to developing a single application as a suit of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery.”
— Martin Fowler and James Lewis
Monolith vs. Microservices
Designing for Failure
Failure happens:
Embrace failures – they will happen!
How to avoid –> How to identify and what to do about it
Operational concern –> developer concern
Plan to be throttled
Plan to retry (with exponential back off)
Degrade gracefully
Cache when appropriate
Retry pattern:
Circuit Breaker pattern:
Bulkhead pattern:
Chaos engineering:
Also known as monkey testing
You deliberately kill services
Netflix created The Simian Army tools
You cannot know how something will respond to a failure until it actually fails
Working DevOps
Taylorism and Working in Silos
Working DevOps:
Culture of teaming and collaboration
Agile development as a shared discipline
Automate relentlessly
Push smaller releases faster
Taylorism:
Adoption of command and control management
Organizations divided into functional silos
Decision-making is separated from work
Impact of Taylorism on IT:
Software development is bespoke:
Software development is NOT like assembling automobiles
Most of the parts don’t exist, yet
Software development is craft work
Taylorism is not appropriate for craft work
Abandon Command and Control:
Command and control is not Agile
Stop working in silos
Let your people amaze you
Software Engineering vs. Civil Engineering
Software engineering is organic:
Software stack is constantly updated
New features are being added
System behavior changes over time
Yet we treat software engineering like a civil engineering project
The project model is flawed:
The project model doesn’t work for software development
Treat software development like product development
Encourage ownership and understanding
Software engineering is not civil engineering
Maintain stable, lasting teams
Required DevOps Behaviors
Diametrically opposed views:
Enterprises see “new” as complex and time-consuming
DevOps delivers a continual series of small changes
These cannot survive traditional overheads
A clash of work culture:
The no-win scenario:
Development wants innovation
Operations wants stability
Operations view of development:
Development teams throw dead cats over the wall
Manually implemented changes
Lack of back-out plans
Lack of testing
Environments that don’t look like production
Development view of operations:
All-or-nothing changes
Change windows in the dead of night
Implemented by people furthest away from the application
Ops just cuts and pastes from “runbooks”
No-win scenario:
If the website works, the developers get the praise!
If the website is down, operations gets the blame!
Required DevOps behaviors:
Infrastructure as Code
Described an executable textual format
Configure using that description
Configuration Management Systems to make this possible (Ansible, puppet etc.)
Never perform configurations manually
Use version control
Ephemeral immutable infrastructure:
Server drift is a major source of failure
Servers are cattle not pets
Infrastructure is transient
Build through parallel infrastructure
Immutable delivery via containers:
Applications are packaged in containers
Same container that runs in production can be run locally
Dependencies are contained
No variance limits side effects
Rolling updates with immediate roll-back
Immutable way of working:
You never make changes to a running container
You make changes to the image
Then redeploy a new container
Keep images up-to-date
Continuous Integration (CI)
CI vs. CD:
CI/CD is not one thing
Continuous Integration (CI):
Continuously building, testing, and merging to master
Continuous Delivery (CD):
Continuously deploying to a production-like environment
Traditional Development:
Devs work in long-lived development branches
Branches are periodically merged into a release
Builds are run periodically
Devs continue to add to the development branch
Continuous Integration
Devs integrate code often
Devs work in short-lived feature branches
Each check-in is verified by an automated build
Changes are kept small:
Working in small batches
Committing regularly
Using pull requests
Committing all changes daily
CI automation:
Build and test every pull request
Use CI tools that monitor version control
Test should run after each build
Never merge a PR with failing tests
Benefits of CI:
Faster reaction times to changes
Reduced code integration risk
Higher code quality
The code in version control works
Master branch is always deployable
Continuous Delivery
“Continuous Delivery is a software development discipline where you build software in such a way that the software can be released to production at any time.” — Martin Fowler
Release to production at any time:
The master branch should always be ready to deploy
You need a way to know if something will “break the build”
Deliver every change to a production-like environment
CI/CD pipeline:
Automated gates that create a pipeline of checks:
Unit testing
Code quality checks
Integration testing
Security testing
Vulnerability scanning
Package signing
A CI/CD pipeline needs:
A code repository
A build server
An integration server
An artifact repository
Automatic configuration and deployment
Continuous integration and delivery:
Five key principles:
Build quality in
Work in small batches
Computers perform repetitive tasks, people solve problems
Relentlessly pursue continuous improvement
Everyone is responsible
CI/CD + Continuous deployment:
How DevOps manages risk:
Deployment is king
Deployment is decoupled from activation
Deployment is not “one size fits all”
Organizing for DevOps
Organizational Impact of DevOps
How does organization affect DevOps?
Is the culture of your organization agile?
Small teams
Dedicated teams
Cross-functional teams
Self-organizing teams
Conway’s Law:
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.” — Melvin Conway, Datamation, 1968
Traditional organization around technology:
Organized around business domains:
Align teams with the business:
Each team has its own mission aligned with the business
Teams have end-to-end responsibility for what they build
Teams should have a long-term mission, usually around a single business domain
There is No DevOps Team
DevOps is often misunderstood:
Dev and Ops are not separate things
You aren’t a DevOps if you’re not a Dev, and other way is also true
Perspectives on DevOps:
DevOps is not a team:
“The DevOps movement addresses the dysfunction that results from organizations composed of functional silos. Thus, creating another functional silo that sits between Dev and Ops is clearly a poor (and ironic) way to try, and solve these problems.” — Jez Humble, The DevOps Handbook
Working in silos doesn’t work:
A DevOps team means we’re DevOps, right?
DevOps is not a job title:
A culture transformation on an organizational scale
Development and operations engineers working together
Following lean and agile principles
Cross-functional teams with openness, transparency, and trust as pillars
Everyone is Responsible for Success
Bad behavior:
“Bad behavior arises when you abstract people from the consequences of their actions.” — Jez Humble, Continuous Delivery
Functional silos breed bad behavior:
Actions have consequences:
Make people aware of the consequences of their actions
Make people responsible for the consequences of their actions
DevOps organizational objective:
Shared consciousness
…with
distributed (local) control
Measuring DevOps
Rewarding for “A” while hoping for “B”
On the folly of rewarding for A, while hoping for B
“Whether dealing with monkeys, rats, or human beings, it is hardly controversial to state that most organisms seek information concerning what activities are rewarded, and then seek to do (or at least pretend to do) those things, often to the virtual exclusion of activities not rewarded. The extent to which this occurs, of course, will depend on the perceived attractiveness of the rewards offered, but neither operant nor expectancy theorists would quarrel with the essence of this notion.” — Steven Kerr, The Ohio State University
Measure what matters:
Social metrics:
Who is leveraging the code you are building?
Whose code are you leveraging?
DevOps metrics:
A baseline provides a concrete number for comparison as you implement your DevOps changes
Metric goals allow you to reason about these numbers and judge the success of your progress
DevOps changes the objective:
Old school is focused on mean time to failure (MTTF)
DevOps is focused on mean time to recovery (MTTR)
Vanity metrics vs. actionable metrics
Vanity metrics:
We had 10,000 daily hits to our website!
Now what? (What does a hit represent?)
What actions drove those visitors to you?
Which actions to take next?
Actionable metrics:
Actionable metric examples:
Reduce time to market
Increase overall availability
Reduce time to deploy
Defects detected before production
More efficient use of infrastructure
Quicker performance feedback
Top four actionable metrics:
Mean lead time
Release frequency
Change failure rate
Mean time to recovery (MTTR)
How to Measure Your Culture
Culture measurements:
You can rate statements developed by Dr. Nicole Forsgren to measure your team’s culture, including statements about information, failures, collaboration, and new ideas.
Strongly agree or disagree?
On my team, information is actively sought
On my team, failures are learning opportunities and messengers of them are not punished
On my team, responsibilities are shared
On my team, cross-functional collaboration is encouraged and rewarded
On my team, failure causes inquiry
On my team, new ideas are welcomed
Comparison of DevOps to Site Reliability Engineering
What is SRE?
“…what happens when a software engineer is tasked with what used to be called operations.” —Ben Treynor Sloss
Goal: Automate yourself out of a job.
Tenets of SRE:
Hire only software engineers
Site reliability engineers work on reducing toil through automation
SRE teams are separate from development teams
Stability is controlled through error budgets
Developers rotate through operations
Team differences:
SRE maintains separate development and operations silos with one staffing pool
DevOps breaks down the silos into one team with one business objective
Maintaining stability:
Commonality:
Both seek to make both Dev and Ops work visible to each other
Both require a blameless culture
The objective of both is to deploy software faster with stability
DevOps + SRE:
SRE maintains the infrastructure
DevOps uses infrastructure to maintain their applications
Subsections of Introduction to Agile Development and Scrum
Introduction to Agile and Scrum
> 70% of organizations have incorporated some Agile approaches. — Project Management Institute
28% more successful using agile than traditional projects. — Price Waterhouse Coopers
47% agile transformations’ failure rate. — Forbes
#1 reason is inexperience with implementing and integrating the Agile methodology. — VersionOne
Agile is a mindset that requires culture change.
It’s hard to learn Agile from just reading a book.
Recognizing when something is wrong is just as important as knowing how to do something right.
Introduction to Agile Philosophy: Agile Principles
What is Agile?
Agile is an iterative approach to project management that helps teams be responsive and deliver value to their customers faster
Agile defining characteristics:
Agile emphasizes:
Adaptive planning
Evolutionary development
Early delivery
Continual improvement
Responsiveness to change
Agile Manifesto:
We have come to value:
Individuals and interactions over processes and tools.
Working software over comprehensive documentation.
Customer collaboration over contract negotiation.
Responding to change over following a plan.
That is, while there is value in the items on the right, we value the items on the left more.
Agile Software development:
An iterative approach to software development consistent with Agile Manifesto
Emphasizes flexibility, interactivity, and a high level of transparency
Uses small, co-located, cross-functional, self-organizing teams
Key takeaway:
Build what is needed, not what was planned.
Methodologies Overview
Traditional Waterfall Development:
Problems with waterfall approach:
No provisions for changing requirements
No idea if it works until the end
Each step ends when the next begins
Mistakes found in the later stages are more expensive to fix
There is usually a long time between software releases
Teams work separately, unaware of their impact on each other
The people who know the least about the code are deploying it into production
Extreme Programming (XP)
In 1996 Kent Beck introduced XP
Based on an interactive approach to software development
Intended to improve software quality and responsiveness to changing customer requirements
One of the first Agile method
Extreme Programming values:
Simplicity
Communication
Feedback
Respect
Courage
Kanban
What is Kanban?
Kanban | ‘kanban | noun
(also Kanban system) a Japanese manufacturing system in which the supply of components is regulated through the use of an instruction card sent along the production line.
An instruction card used in a Kanban system.
Origin
1970s: Japanese, Literally mean ‘billboard, sign’
Core principles of Kanban:
Visualize the workflow
Limit work in progress (WIP)
Manage and enhance the flow
Make process policies explicit
Continuously improve
Working Agile
Working in small batches
Minimum Viable Product (MVP)
Behavior Driven Development (BDD)
Test Driven Development (TDD) (Gherkin Syntax — Developed by Cucumber Company)
Pair programming
Introduction to Scrum Methodology
Agile and Scrum:
Agile is a philosophy for doing work (not prescriptive)
Scrum is a methodology for doing work (add process)
Scrum Overview
Scrum:
Is a management framework for incremental product development
Prescribes small, cross-functional, self-organizing teams
Provides a structure of roles, meeting, rules, and artifacts
Uses fixed-length iterations called sprints
Has a goal to build a potentially shippable product increment with every iteration
Easy to Understand – Difficult to master
Sprint:
A sprint is one iteration through the design, code, test, and deploy cycle
Every sprint should have a goal
2 weeks in duration
Steps in the Scrum process:
Agile development is iterative:
The 3 Roles of Scrum
Scrum roles:
Product owner
Scrum master
Scrum team
Product owner:
Represents the stakeholder interests
Articulates the product vision
Is the final arbiter of requirements’ questions
Constantly re-prioritizes the product backlog, adjusting any expectations
Accepts or rejects each product increment
Decides whether to ship
Decides whether to continue development
Scrum master:
If your team is experienced, you might skip this role, but if you have a team new to Scrum, you require an experienced Scrum master.
Facilitates the Scrum process
Coaches the team
Creates an environment to allow the team to be self-organizing
Shields the team from external interference to keep it “in the zone”
Helps resolve impediments
Enforces sprint timeboxes
Captures empirical data to adjust forecasts
Has no management authority over the team
Scrum Team:
A cross-functional team consisting of
Developers
Testers
Business analysts
Domain experts
Others
Self-organizing
There are no externally assigned roles
Self-managing
They self-assign their own work
Membership: consists of 7 ± 2 collaborative members
Co-located: most successful when located in one team room, particularly for the first few Sprints
Dedicated: Most successful with long-term, full-time membership
Negotiates commitments with the product owner – one sprint at a time
Has autonomy regarding how to reach commitments
Artifacts, Events, and Benefits
Scrum Artifacts:
Product backlog
Sprint backlog
Done increment
Scrum events:
Sprint planning meeting
Daily Scrum meeting (a.k.a. daily stand-up)
Sprint
Sprint review
Sprint retrospective
Benefits of Scrum:
Higher productivity
Better product quality
Reduced time to market
Increased stakeholders satisfaction
Better team dynamics
Happier employees
Scrum vs. Kanban:
Organizing for Success: Organizational impact of Agile
Organize for success:
Proper organization is critical to success
Existing teams may need to be reorganized
Conway’s Law:
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
— Melvin Conway, Datamation, 1968
Examples of Conway’s Law:
If you ask an organization with four teams to write a compiler
… you will get a 4-pass compiler!
How teams should be aligned?
Teams are loosely coupled, tightly aligned
Each team has its own mission aligned with the business (like a “mini startup”)
Teams have end-to-end responsibility for what they build
The long-term mission is usually around a single business domain
Autonomy is important:
It’s motivating – and motivated people build better stuff
It’s fast – decisions happen locally in the team
It minimizes handoffs and waiting, so teams don’t get bogged down
The Agile dilemma!
The entire organization must be Agile:
Agile + DevOps = Alignment
Mistaking Iterative Development for Agile
The biggest pitfall for companies is that, they think they’re agile, but actually they’re just doing an iterative work.
Agile is not…
Agile isn’t a new version of a waterfall, software development life cycle (SDLC), where you do legacy development in sprints
Agile isn’t just the developers working in each sprint, it involves a cross-functional team
The Agile Manifesto doesn’t include the term “Agile project management” (and so there are no “project managers” in Agile)
Agile Planning
Planning to be Agile: Destination Unknown
Deadlines:
“I love deadlines… I like the whooshing sound they make as they fly by”.
– Douglas Adams
How do you avoid this?
Plan iteratively:
Don’t decide everything at the point when you know the least
Plan for what you know
Adjust as you know more
Your estimates will be more accurate
Agile Roles and the Need for Training
Formulas for failure:
Product manager becomes product owner
Project manager becomes scrum master
Developers (alone) become scrum team
Product Manager vs. Product Owner:
Project Manager vs. Scrum Master:
Development Team vs. Scrum Team:
“Until and unless business leaders accept the idea that they are no longer managing projects with fixed functions, timeframes, and costs, as they did with waterfall, they will struggle to use agile as it was designed to be used.”
— Bob Kantor, Founder Kantor Consulting Group, Inc.
The roles have changed:
You cannot put people in new roles without the proper training and mindset
This mindset must come down from upper management
Kanban and Agile Planning Tools
Agile planning tools:
Tools will not make you Agile
Tools can support your Agile process
Many Agile planning tools
ZenHub is one of them
ZenHub:
Plug-in to GitHub
Provides a kanban board and project management reporting
Customizable and integrated with GitHub
Why use ZenHub?
Helps you manage where you are in a project based on GitHub Issues
Provides an easy way to let management know how you are doing
Maintains up-to-date status due to integration with GitHub
Allows developers to only use one tool – GitHub
What is Kanban Board?
Real World Example:
Default ZenHub pipelines:
User Stories: Creating Good User Stories
What is a user story?
A user story represents a small piece of business value that a team can deliver in an iteration.
Story contents:
Stories should contain:
A brief description of the need and business value
Any assumptions or details
The definition of “done”
Story description:
User stories document a persona requesting a function to achieve a goal:
As a <some role>
I need <some function>
So that <some benefit>
Assumptions and details:
It’s important to document what you know;
List any assumptions
Document any details that may help the developer
Acceptance criteria:
It is critical to document the definition of “done”
I like to use the Gherkin syntax
Given <some precondition>
When <some event happens>
Then <some outcome>
Sample Story:
Bill Wake’s INVEST:
Independent
Negotiable
Valuable
Estimable
Small
Testable
Epic:
A big idea
A user story that is bigger than a single sprint
A user story that is too big to estimate on its own
When to use an epic?
When a story is too large in scope it is considered an epic
Backlog items tend to start as epics when they are lower priority and less defined
For sprint planning, epics should be broken down into smaller stories
Effectively using Story Points
What are story points?
Story point;
A metric used to estimate the difficulty of implementing a given user story
An abstract measure of overall effort
What does a story point measure?
Relative T-Shirt sizes
Story points acknowledge that humans are bad at estimating time-to-completion
Instead, story points use relative T-Shirt sizes (S, M, L, XL)
Most tools use Fibonacci numbers (1, 2, 3, 5, 8, 13, 21)
Agree on what “medium” means:
Since story points are relative, it’s important to agree on what “medium” is
Then, evaluate from there
Is it the same, larger, or smaller than medium
Story size:
A story should be small enough to be coded and tested within a single sprint iteration – ideally, just a few days
Large stories should be broken down into smaller ones
Story point antipattern
Equating a story point to wall-clock time
Humans are bad at estimating wall-clock time
Don’t do it!
Building the Product Backlog
Steps in the Scrum process:
Product Backlog:
A product backlog contains all the unimplemented stories not yet in a sprint
Stories are ranked in order of importance and/or business value
Stories are more detailed at the top, less detailed at the bottom
Sample requirements:
What: A service for counting things
Must allow multiple counters
Counters must persist across restarts of service
Counters can be reset
ZenHub Kanban board:
Creating new stories
Story Template:
As a<some role>
I need<some function>
So that<some benefit>
Need a service for counting things:
As a User
I need a service that has a counter
So that I can keep track of how many times something was done
Creating the next story:
Must allow multiple counters:
As a User
I need to have multiple counters
So that I can keep track of several counts at once
Creating the next story:
Persist counters across restarts:
As a Service Provider
I need the service to persist the last known count
So that users don’t lose track of their counts after the service is restarted
Creating the last story:
Counters can be reset:
As a System Administrator
I need the ability to reset the counter
So that I can redo counting from the start
Stories in the backlog:
Prioritize the product backlog:
The Planning Process
Backlog Refinement: Getting Started
Backlog refinement:
Keep the product backlog ranked by priority so that the important stories are always on the top
Break large stories down into smaller ones
Make sure that stories near the top of the backlog are groomed and complete
Backlog refinement meeting:
Who should attend?
Product owner
Scrum master
Development team (optional)
Lead developer/architect
What is the goal?
Groom the backlog by ranking the stories in order of importance
Make sure the story contains enough information for a developer to start working on it
Backlog refinement workflow:
New issue triage:
Start with new issue triage
Goal: At the end of backlog refinement, the New Issues column is empty
Take stories from new issues and…
Move them into the product backlog if they will be worked on soon
Move them into the icebox if they are a good idea but not now
Reject them if they are not where you want to go
Backlog refinement workflow:
Product owner sorts the product backlog in order of importance
The team may provide estimates and other technical information
Large vague items are split and clarified
The goal is to make the stories “sprint read”
Complete the story template:
As a <some role>
I need <some function>
So that <some benefit>
Assumptions and Details:
<anything you already know>
Acceptance Criteria:
Given <some precondition>
When <some event>
Then <some measurable outcome>
Need a service that has a counter:
Must Persist counter across restarts:
Deploy service to the cloud:
Ability to reset the counter:
Backlog Refinement: Finishing Up
Label:
Help visualize the work
Labels in GitHub
Need a service that has a counter:
Must persist counter across restarts:
Deploy service to the cloud:
Ability to reset the counter:
Technical debt
Technical debt is anything you need to do that doesn’t involve creating a new feature
Technical debt builds up when you take shortcuts, but may also occur naturally
Examples of technical debt:
Code refactoring
Setup and maintenance of environments
Changing technology like databases
Updating vulnerable libraries
Backlog refinement Tips
You should refine the backlog every sprint to ensure the priorities are correct
Have at least two sprints’ worth of stories groomed
The more time you spend refining the backlog, the easier sprint planning will be
Sprint Planning
The purpose of sprint planning is to define what can be delivered in the sprint and how that work will be achieved
This is accomplished by producing a sprint backlog
Sprint planning meeting
Who should attend?
Product owner
Scrum master
Development team
Sprint planning goals:
Each sprint should have a clearly defined business goal
The product owner describes the goal and product backlog items supporting it
It’s important for the whole team to understand why they are building the increment
Mechanics of sprint planning
The development team;
Takes stories from the top of the product backlog and assigns them to the sprint backlog
Assigns story points and labels
Ensures each story contains enough information for a developer to start working on it
Stops adding stories when the team’s velocity is reached
Team velocity:
The number of story points a team can complete in a single sprint
This will change over time as the team gets better at estimating and better at executing
The velocity is unique to the team because the story point assignment is unique to the team
Create a sprint milestone:
Create a sprint milestone to start the sprint
The milestone title should be short
The description should document the milestone goal
The duration should be 2 weeks
Create a milestone:
Executing the Plan
Workflow for Daily Plan Execution
Steps in the Scrum Process:
The Sprint:
A sprint is one iteration through the design, code, test, deploy cycle
It is usually 2 weeks in duration
Every sprint should have a goal
Daily Execution:
Take the next highest priority item from the sprint backlog
Assign it to yourself
Move it in process
No one should have more than one story assigned to them unless they are blocked
When you are finished, move the story to Review/QA and open a PR
When the PR is merged, move the story to the Done column
The Daily Stand-Up
Occurs every day at the same time and place
Sometimes called the “daily Scrum”
Each team member briefly reports on their work
Called a “stand-up” during the meeting to keep it short
Timeboxed to 15 mins
Not a project status meeting – all status should be tabled for later discussion
Daily stand-up meeting:
Who should attend?
Scrum master
Development team
Product owner (optional)
Daily stand-up question:
Each team member answers three questions:
What did I accomplish the previous day?
What will I work on today?
What blockers or impediments are in my way?
Impediments and blockers:
Impediments identified by the team should be unblocked by the scrum master
Developers that are blocked should work on the next story
Tabled topics:
Topics raised during the daily stand-up should be held until the meeting has ended
Anyone interested in those topics can stay to discuss
Completing the Sprint
Using Burndown Charts
Milestones and burndowns:
Milestones can be created for anything in your project
sprint, beta drop, demo, release…
Burndown charts can be used to measure your progress against a milestone
Burndown chart:
The measurement of story points completed vs. story points remaining for a sprint
Over time the story points remaining should go down, hence the name: burndown
Burndown chart examples:
The Sprint Review
Live demonstration of implemented stories
Product owner determines if stories are done based on acceptance criteria
Done stories are closed
Sprint Review meeting:
Who should attend?
Product owner
Scrum master
Development team
Stakeholders
Customers (Optional)
Sprint review:
Feedback gets converted into new product backlog stories
This is where iterative development allows the creation of products that couldn’t have been specified up-front in a plan-driven approach
Rejected Stories:
What about stories that are not considered done?
Add a label to indicate this and close them
Write a new story with new acceptance criteria
This will keep the velocity more accurate
The Sprint Retrospective
A meeting to reflect on the sprint
Measures the health of the process
The development team must feel comfortable to speak freely
Who attend the meeting:
Scrum master
Development team
A time for reflection:
Three questions are answered:
What went well? (keep doing)
What didn’t go well? (stop doing)
What should we change for the next sprint?
The goal is improvement:
This is critical for maintaining a healthy team
The scrum master must ensure that changes are made as a result of the feedback
The goal is to improve for the next sprint
Measuring Success
Using Measurements Effectively
Measurements and metrics:
You can’t improve what you can’t measure
High performing teams use metrics to continually improve
They take baselines and set goals and measure against them
Beware of vanity metrics
Look for the actionable metrics
Baselines and Goals:
Baseline:
It currently requires 5 size team members, 10 hours to deploy a new release of your product
This costs you $X for every release
Goals:
Reduce deployment time from 10 hours to 2 hours
Increase percentage of defects detected in testing from 25% to 50%
Top 4 actionable metrics:
Mean Lead Time
How long does it take from the idea to production?
Release Frequency
How often can you deliver changes?
Change Failure Rate
How typically do changes fail?
Meantime to Recovery (MTTR)
How quickly can you recover from failure?
Example metrics:
Reduce time-to-market for new features
Increase overall availability of the product
Reduce the time it takes to deploy a software release
Increase the percentage of defects detected in testing before production release
Provide performance and user feedback to the team in a more timely manner
Getting Ready for the Next Sprint
End of sprint activities:
Move stories from done to closed
Close the current milestone
Create a new sprint milestone
Adjust unfinished work
Handling untouched stories:
Stories not worked on can be moved to the top of the product backlog
Resist the urge to move them to the next sprint
Remember to unassign them from the sprint milestone
Handling unfinished stories:
Don’t move unfinished stories into the next sprint!
Give the developers credit for the work they did
This will keep your velocity more accurate
Adjust the description and story points of the unfinished story, label it unfinished, and move it to done
Write a new story for the remaining work
Assign remaining story points and move it to the next sprint
Ready for the next sprint:
All stories assigned to the current sprint are closed
All unfinished stories are reassigned
The sprint milestone is closed
A new sprint milestone is created
Agile Anti-Patterns and Health Check
Agile Anti-Patterns:
No real product owner/Multiple product owners
Teams are too large
Teams are not dedicated
Teams are too geographically distributed
Teams are siloed
Teams are not self-managing
YOU WILL FAIL!
…and you should not wonder why.
Scrum health check:
The accountabilities of product owner, development team(s) and Scrum master are identified and enacted
Work is organized in consecutive sprints of 2–4 weeks or fewer
There is a sprint backlog with a visualization of remaining work for the sprint
At sprint planning a forecast, a sprint backlog, and a sprint goal are created
The result of the daily Scrum is work being re-planned for the next day
No later than by the end of the sprint, a Done increment is created
Stakeholders offer feedback as a result of inspecting the increment at the sprint review
Product backlog is updated as a result of the sprint review
Product owner, development team(s) and Scrum master align on the work process for their next sprint at the sprint retrospective
The Software Building Process and Associated Roles
Software Development Methodologies
Common development methodologies:
A process is needed to clarify communication and facilitates information sharing among team members.
Some of these methodologies are:
Waterfall
V-shape model
Agile
Sequential vs. iterative:
Waterfall pros and cons
V-shape model pros and cons
Agile pros and cons
Software Versions
Software versions are identified by version numbers, indicate:
When the software was released
When it was updated
If any minor changes or fixes were made to the software
Software developers use versioning to keep track of new software, updates, and patches
Version numbers:
Version numbers can be short or long, with 2, ,3, or 4 set
Each number set is divided by a period
An application with a 1.0 version number indicates the first release
Software with many releases and updates will have a larger number
Some use dates for versioning, such as Ubuntu Linux version 18.04.2 released in 2018 April, with a change shown in the third number set
What do version numbers mean?
Some version numbers follow the semantic numbering system, and have 4 parts separated by a period
the first number indicates major changes to the software, such as a new release
The second number indicates that minor changes were made to a piece of software
The third number in the version number indicates patches or minor bug fixes
The fourth number indicates build numbers, build dates, and less significant changes
Version compatibility:
Older versions may not work as well in newer versions
Compatibility with old and new versions of software is a common problem
Troubleshoot compatibility issues by viewing the software version
Update software to a newer version that is compatible
Backwards-compatible software functions properly with older versions of files, programs, and systems
Software Testing
Integrate quality checks throughout SDLC
Purpose
Ensure software meets requirements
Error-free software
Test cases:
Three types of testing:
Functional testing:
The purpose of functional is to check:
Usability
Accessibility
Non-functional testing
Its attributes are:
Performance
Security
Scalability
Availability
Non-functional testing questions:
How does the application behave under stress?
What happens when many users log in at the same time?
Are instructions consistent with behavior?
How does the application behave under different OSs?
How does the application handle disaster recovery?
How secure is the application?
Regression Testing
Confirms changes don’t break the application
Occurs after fixes such as change in requirements or when defects are fixed
Choosing test cases for regression testing:
Testing levels
Unit → Integration → System → Acceptance
Unit testing
Test a module code
Occurs during the build phase of the SDLC
Eliminate errors before integration with other modules
Integration testing
Identify errors introduced when two or more modules are combined
Type of black-box test
Occurs after modules are combined into larger application
Purpose of integration testing:
System testing
Compliance with SRS
Validate the system
Functional and non-functional
Staging environment
Acceptance testing
Software Documentation
Written assets
Video assets
Graphical assets
Product vs. process documentation:
Product Documentation
Process Documentation
Relates to product functionality
Describes how to complete a task
Types of product documentation
Requirements documentation
Intended for the development team including developers, architects, and QA. Describes expected features and functionality.
It includes:
SRS
SysRS
User acceptance specification
Design documentation
Written by architects and development team to explain how the software will be built to meet the requirements.
Consists of both conceptual and technical documents
Technical documentation
Written in the code to help developers read the code:
Comments embedded in code and working papers that explain how the code works, documents that record ideas and thoughts during implementation
Quality Assurance documentation
Pertains to the testing team’s strategy progress, and metrics:
Test plans, test data, test scenarios, test cases, test strategies, and traceability matrices
User documentation
Intended for end-users to explain to operate software or help install and troubleshoot system:
FAQs, installation and help guides, tutorials, and user manuals
Standard operating procedures
Accompanies process documentation
Step-by-step instructions on how to accomplish common yet complex tasks
Ex: organization specific instructions for check in code to a repository
Types of SOPs
Flowcharts
Hierarchical
Step-by-step
Updating documentation
Must be kept up-to-date
Documentation should be reviewed and updated periodically
Roles in Software Engineering Projects
Project manager / Scrum master
Stakeholders
System / software architect
UX Designer
Developer
Tester / QA engineer
Site reliability / Ops engineer
Product manager / Product owner
Technical writer / Information developer
Introduction to Software Development
Overview of Web and Cloud Development
Cloud Applications
Built to work seamlessly with a Cloud-based back-end infrastructure
Cloud-based data storage and data processing, and other Cloud services, making them scalable and resilient
Building websites and cloud applications:
The environment is divided into two primary areas:
Front-End
Deals with everything that happens at the client-side
Specializes in front-end coding, using HTML, CSS, JavaScript and related frameworks, libraries, and tools
Back-End
Deals with the server before the code and data are sent to the client
Handles the logic and functionality and the authentication processes that keep data secure
Back-end developers may also work with relational or NoSQL databases
Full-stack developers have skills, knowledge, and experience in both front-end and back-end environments.
Developers Tools:
Code editor
IDE
Learning Front-End Development
HTML is used to create the structure and CSS is used to design it and make it appealing
CSS is also used to create websites that have cross browser compatibility such as PC, mobiles devices etc.
JS adds interactivity
A front-end development language is Syntactically Awesome Style Sheets (SASS)
An extension of CSS that is compatible with all versions of CSS.
SASS enables you to use things like variables, nested rules, inline imports to keep things organized.
SASS allows you to create style sheets faster and more easily.
Learner Style Sheets (LESS)
LESS enhances CSS, adding more styles and functions.
It is backwards compatible with CSS.
Less.js is a JS tool that converts the LESS styles to CSS styles.
Websites are designed as reactive and responsive
Reactive or adaptive websites display the version of the website designed for a specific screen size.
A website can provide more information if opened on a PC than when opened on a mobile device.
Responsive design of a website means that it will automatically resize to the device.
If you open up a products’ website on your mobile device, it will adapt itself to the small size of the screen and still show you all the features.
JavaScript’s frameworksorks:
Angular Framework:
an open-source framework maintained by google
Allows websites to render HTML pages quickly and efficiently
Tools for routing and form validation
React.js:
Developed and maintained by Meta
It is a JS library that builds and renders components for a web page
Routing is not a part of this framework and will need to be added using a third-party tool
Vue.js:
maintained by the community and its main focus is the view layer which includes UI, buttons, visual components
Flexible, scalable, and integrates well with other frameworks
Very adaptable – it can be a library, or it can be the framework
The task of a front-end developer evolves continuously.
The technologies are upgraded constantly, and so the front-end developers need to keep upgrading the websites that they create.
The websites that they create should work in multiple browsers, multiple operating systems, and multiple devices.
The importance of Back-End Development
Creates and manages resources needed to respond to client requests
Enables server infrastructure to process request, supply data and provide other services securely
What does the back-end developer do?
Process the data you enter while browsing, such as:
Login information
Product searches
Payment information
Write and maintain the parts of the application that process the inputs
Back-End Developer skills:
Examples of tasks and associated skills that back-end developers need:
APIs, routing, and endpoints:
APIs, routes, and endpoints process requests from the Front-End
API is a code that works with data
Routes is a path to a website or page
Endpoint can be an API or route
Back-end developers create routes to direct requests to correct service
APIs provide a way for Cloud Apps to access resources from the back-end
Back-end languages and frameworks:
Some popular back-end languages are:
JavaScript
Node.js
Express
Python
Django
Flask
Working with databases:
Languages and tools for working with databases:
Structured Query Language (SQL)
Object-Relational Mapping (ORM)
Introducing Application Development Tools
A cloud application developer’s workbench includes:
Version Control
Libraries
Collection of reusable code
Multiple code libs can be integrated into a project
Call from your code when required
Used to solve a specific problem or add a specific feature
Frameworks:
Provide a standard way to build and deploy applications
Act as a skeleton you extend by adding your own code
Dictate the architecture of the app
Call your code
Allow you less control than libs
Inversion of Control:
Libs allow you to call functions as when required
Frameworks define the workflow that you must follow
Inversion of control makes the framework extensible
More tools:
CI/CD
Build tools
Transform source code into binaries for installation
Important in environments with many interconnected projects and multiple developers
Automate tasks like
Downloading dependencies
Compiling source code into binary code
Packaging that binary code
Running Tests
Deployment to production systems
Examples of Build Tools:
Packages:
Packages make apps easy to install
Packages contain
App files
Instructions for installation
Metadata
Package managers:
Make working with packages easier
Coordinate with file archives to extract package archives
Verify checksums and digital certificates to ensure the integrity and authenticity of the package
Locate, download, install, or update existing software from a software repository
Manage dependencies to ensure a package is installed with all packages it requires
Package Managers by platform:
Cloud application package managers:
Introduction to Software Stacks
What is a software stack?
Combination of technologies
Used for creating applications and solutions
Stacked in a hierarchy to support the application from user to computer hardware
Typically include;
Front-end technologies
Back-end technologies
Parts of the software stack:
Examples of software stack:
Python-Django
Ruby on Rails
ASP .NET
LAMP
MEAN
MEVN
MERN
LAMP Stack:
MEAN and relasted stacks:
Comparison of MEAN, MEVN, and LAMP:
MEAN
All parts use JS – one language to learn
Lost of documentation and reusable code
Not suited to large-scale applications or relational data
MEVN
Similar to MEAN
Less reusable libs
LAMP
Lots of reusable code and support
Only on Linux
Not suited in non-relational data
Uses different languages
Programming Languages and Organization
Interpreted and Compiled Programming Languages
Interpreted programming:
Interpreted programming examples:
Compiled programming:
Programs that you run on your computer
Packaged or compiled into one file
Usually larger programs
Used to help solve more challenging problems, like interpreting source code
Compiled programming examples:
C, C++, and C# are used in many OSs, like MS Windows, Apple macOS and Linux
Java works well across platforms, like the Android OS
Compiled programming:
Comparing Compiled and Interpreted Programming Languages
Choosing a programming language:
Developers determine what programming language is best to use depending on:
What they are most experienced with and trust
What is best for their users
What is the most efficient to use
Programming languages:
Interpreted vs. compiled
Query and Assembly Programming Languages
Programming language levels:
High-level programming languages:
More sophisticated
Use common English
SQL, Pascal, Python
Low-level programming languages:
Use simple symbols to represent machine code
ARM, MIPS, X86
Query languages:
A query is a request for information from a database
The database searches its tables for information requested and returns results
Important that both the user application making the query and the database handling the query are speaking the same language
Writing a query means using predefined and understandable instructions to make the request to a database
Achieved using programmatic code (query language/database query language)
Most prevalent database query language is SQL
Other query languages available:
AQL, CQL, Datalog, and DMX
SQL vs. NoSQL:
NoSQL (Not Only SQL)
Key difference is data structures
SQL databases:
Relational
Use structured, predefined schemas
NoSQL databases:
Non-relational
Dynamic schemas for unstructured data
How does a query language work?
Query language is predominantly used to:
Request data from a database
Create, read, update, and delete data in a database (CRUD)
Database consists of structured tables with multiple row and columns of data
When a user performs a query, the database:
retrieve data from the table
Arranges data into some sort of order
Returns and presents query results
Query statements:
Database queries are either:
Select commands
Action commands (CREATE, INSERT, UPDATE)
More common to use the term “statement”
Select queries request data from a database
Action queries manipulate data in a database
Common query statements:
query statement examples:
Assembly Languages
Less sophisticated than query languages, structured programming languages, and OOP languages
Uses simple symbols to represent 0s and 1s
Closely tied to CPU architecture
Each CPU type has its own assembly language
Assembly language syntax:
Simple readable format
Entered one line at a time
One statement per line
{lable} mnemonic {operand list} ;{comment}
mov TOTAL, 212 ;Transfer the value in the memory variable TOTAL
Assemblers:
Assembly languages are translated using an assembler instead of a compiler or interpreter
One statement translates into just one machine code instruction
Opposite to high-level languages where one statement can be translated into multiple machine code instructions
Translate using mnemonics:
Input (INP), Output (OUT), Load (LDA), Store (STA), Add (ADD)
Statements consist of:
Opcodes that tell the CPU what to do with data
Operands that tell the CPU where to find the data
Understanding Code Organization Methods
Pseudocode vs. flowcharts:
Pseudocode
Flowcharts
Informal, high-level algorithm description
Pictorial representation of algorithm, displays steps as boxes and arrows
Step-by-step sequence of solving a problem
Used in designing or documenting a process or program
Bridge to project code, follows logic
Good for smaller concepts and problems
Helps programmers share ideas without extraneous waste of creating code
Provide easy method of communication about logic behind concept
Provides structure that is not dependent on a programming language
Offer good starting point for project
Flowcharts:
Graphical or pictorial representation of an algorithm
Symbols, shapes, and arrows in different colors to demo a process or program
Analyze different methods of solving a problem or completing a process
Standard symbols to highlight elements and relationships
Flowchart software:
Pseudocode:
Pseudocode Advantages:
Simply explains each line of code
Focuses more on logic
Code development stage is easier
Word/phrases represent lines of computer operations
Simplifies translation to code
Code in different computer languages
Easier review by development groups
Translates quickly and easily to any computer language
More concise, easier to modify
Easier than developing a flowchart
Usually less than one page
Programming Logic and Concepts
Branching and Looping Programming Logic
Introduction to programming logic:
Boolean expressions and variables:
Branching programming logic:
Branching statements allow program execution flow:
if
if-then-else
Switch
GoTo
Looping programming logic:
While loop: Condition is evaluated before processing, if true, then loop is executed
For loop: Initial value performed once, condition tests and compares, if false is returned, loop is stopped
Do-while loop: Condition always executed after the body of a loop
Introduction to Programming Concepts
What are identifiers?
Software developers use identifiers to reference program components
Stored values
Methods
Interfaces
Classes
Identifiers store two types of data values:
Constants
Variables
What are containers?
Special type of identifiers to reference multiple program elements
No need to create a variable for every element
Faster and more efficient
Ex:
To store six numerical integers – create six variables
To store 1,000+ integers – use a container
Arrays and vectors
Arrays:
Simplest type of container
Fixed number of elements stored in sequential order, starting at zero
Declare an array
Specify data type (int, bool, str)
Specify max number of elements it can contain
Syntax
Data type > array name > array size []
int my_array[50]
Vectors:
Dynamic size
Automatically resize as elements are added or removed
a.k.a. ‘dynamic arrays’
Take up more memory space
Take longer to access as not stored in sequential memory
Syntax
Container type/data type in <>/name of array
vector <int> my_vector;
What are functions?
Consequence of modular programming software development methodology
Multiple modular components
Structured, stand-alone, reusable code that performs a single specific action
Some languages refer to them as subroutines, procedures, methods, or modules
Two types:
Standard library functions – built-in functions
User-defined functions – you write yourself
What are objects?
Objects are key to understanding object-oriented programming (OOP)
OOP is a programming methodology focused on objects rather than functions
Objects contain data in the form of properties (attributes) and code in the form of procedures (methods)
OOP packages methods with data structures
Objects operate on their own data structure
Objects in programming
Consist of states (properties) and behaviors (methods)
Store properties in fields (variables)
Expose their behaviors through methods (functions)
Software Architecture Design and Patterns
Introduction to Software Architecture
Software architecture and design:
Design and documentation take place during the design phase of the SDLC
Software architecture is the organization of the system
Serves as a blueprint for developers
Comprised of fundamentals structures and behaviors
Early design decisions:
How components interact
Operating environment
Design principles
Costly to change once implemented
Addresses non-functional aspects
Why software architecture is important:
Communication
Earliest design decisions
Flexibility
Increases lifespan
Software architecture and tech stacks:
Guides technology stack choice
Tech stacks must address non-functional capabilities
Tech stacks include:
Software
Programming languages
Libs
Frameworks
Architects must weigh advantages and disadvantages of tech stack choices
Artifacts
Software design document (SDD)
Architectural diagrams
Unified modeling language (UML) diagrams
Software Design Document (SDD)
Collection of tech specs regarding design implementation
Design considerations:
Assumptions
Dependencies
Constraints
Requirements
Objectives
Methodologies
Architectural diagrams
It displays:
Components
Interactions
Constraints
Confines
Architectural patterns
UML diagrams
Visually communicate structures and behaviors
Not constrained by a programming language
Deployment considerations
Architecture drives production environment choices
Production environment is the infrastructure that runs and delivers the software
Servers
Load balancers
Databases
Software Design and Modeling
Software Design:
Software design is a process to document:
Structural components
Behavioral attributes
Models express software design using:
Diagrams and flowcharts
Unified Modeling Language (UML)
Characteristics of structured design:
Structural elements: modules & submodules
Cohesive
Loosely coupled
Structure diagram example:
Behavioral models:
Describe what a system does but doesn’t explain how it does it
Communicate the behavior of the system
Many types of behavioral UML diagrams
State transition
Interaction
Unified Modeling Language (UML):
Visual representations to communicate architecture, design, and implementation
Two types: structural and behavioral
Programming language agnostic
Advantages of Unified Modeling Language (UML):
State transition diagram example:
Interaction diagram:
Object-Oriented Analysis and Design
Object-Oriented Languages:
A patient could be an object
An object contains data, and an object can perform actions
Classes and objects:
Object-Oriented analysis and design:
Used for a system that can be modeled by interacting objects
OOAD allows developers to work on different aspects of the same application at the same time
Visual UML diagrams can be made to show both static structure and dynamic behavior of a system
Class diagram:
Software Architecture Patterns and Deployment Topologies
Approaches to Application Architecture
What is component?
An individual unit of encapsulated functionality
Serves as a part of an application in conjunction with other components
Component characteristics:
Reusable: reused in different applications
Replaceable: easily replaced with another component
Independent: doesn’t have dependencies on other components
Extensible: add behavior without changing other components
Encapsulated: doesn’t expose its specific implementation
Non-context specific: operates in different environments
Components examples:
Component-based architecture:
Decomposes design into logical components
Higher level abstraction than objects
Defines, composes, and implements loosely coupled independent components, so they work together to create an application
Services
Designed to be deployed independently and reused by multiple systems
Solution to a business need
Has one unique, always running instance with whom multiple clients communicate
Examples of Services:
A service is a component that can be deployed independently
Checking a customer’s credit
Calculating a monthly loan payment
Processing a mortgage application
Service-oriented architecture:
Loosely coupled services that communicate over a network
Supports building distributed systems that deliver services to other applications through the communication protocol
Distributed systems
Multiple services located on different machines
Services coordinate interactions via a communication protocol such as HTTP
Appears to the end-user as a single coherent system
Distributed system characteristics:
Shares resources
Fault-tolerant
Multiple activities run concurrently
Scalable
Runs on a variety of computers
Programmed in a variety of languages
Nodes:
Any devices on a network that can recognize, process, and transmit data to other nodes on the network
Distributed systems have multiple interconnected nodes running services
Distributed system architectures:
Architectural Patterns in Software
Types of architectural patterns:
2-tier
3-tier
Peer-to-peer (P2P)
Event-driven
Microservices
Examples:
Combining patterns
Application Deployment Environments
Application environments:
Include:
Application code/executables
Software stack (libs, apps, middleware, OS)
Networking infrastructure
Hardware (compute, memory and storage)
Pre-production environments:
Production environment
Entire solution stack ++
Intended for all users
Take load into consideration
Other non-functional requirements
Security
Reliability
Scalability
More complex than pre-production environments
On-premises deployment:
System and infrastructure reside in-house
Offers greater control of the application
Organization is responsible for everything
Usually more expensive than compared to cloud deployment
Cloud deployment types:
Production Deployment Components
Production deployment infrastructure:
Web and application servers:
Proxy server:
An intermediate server that handles requests between two tiers
Can be used for load balancing, system optimization, caching, as a firewall, obscuring the source of a request, encrypting messages, scanning for malware, and more
Can improve efficiency, privacy, and security
Databases and database servers:
Databases are a collection of related data stored on a computer that can be accessed in various ways
DBMS (Database Management System) controls a database by connecting it to users or other programs
Database servers control the flow and storage of data
Job Opportunities and Skill sets in Software Engineering
What does a Software Engineer Do?
Software engineering:
Engineering
Mathematics
Computing
Types of Software:
Desktop and web applications
Mobile Applications
Games
Operating Systems
Network controllers
Types of technologies:
Programming languages
Development environments
Frameworks
Libs, databases, and servers
Categories of software engineer:
Back-end engineers or systems developers
Front-end engineers or application developers
Software engineering teams:
Off-the-shelf software
Bespoke software
Internal software
And within the teams they might work on:
Data integration
Business logic
User interfaces
Software engineering tasks:
Designing new software systems
Writing and testing code
Evaluating and testing software
Optimizing software programs
Maintaining and updating software systems
Documenting code
Presenting new systems to users and customers
Integrating and deploying software
Responsibilities:
Skills Required in Software Engineering
What are hard skills?
Commonly required hard skills in software engineering:
Programming languages
Version control
Cloud computing
Testing and debugging
Monitoring
Troubleshooting
Agile development
Database architecture
What are soft skills?
Hard to define, quantify, or certify
Easily transferable
Hard skills for software engineers
Analysis and design:
Analyze users’ needs
Design solutions
Development:
Computer programming
Coding
Languages:
Java
Python
C#
Ruby
Frameworks
Test:
Testing
Meets functional specification
Easy to use
Debugging
Deployment:
Shell scripting
Containers
CI/CD
Monitoring
Troubleshooting
Soft Skills for Software Engineers
Teamwork:
Different teams
Project-based
Role-based
Squads
Pair programming
Take advantage of strengths
Learn from each other
Communication:
Peers
Managers
Clients
Users
Time management:
Time-sensitive projects
Meet deadlines
Avoid delays
Teams across time-zones
Problem-solving:
Design an appropriate solution
Write an effective code
Locate and resolve bugs
Manage issues
Adaptability:
Client changes
Management request
User needs
Open to feedback:
Peer review
Mentor
Stakeholders
Careers in Software Engineering
Job Outlook for Software Engineers
Employment options:
Employed roles:
Apprenticeship/internship
Part-time
Full-time
Self-employed/independent:
Contracting/consulting
Freelancing
Volunteer on open source projects
Career Paths in Software Engineering
Technical
Coding and problem-solving
Management
Leadership and soft skills
Career progression:
Junior or Associate Software Engineer
Develop small chunks of software
Supported by a team leader or mentor
Gain new skills and experience
Software Engineer
Break tasks down into sub-tasks
Learn new languages
Understand the software development lifecycles
Mentor junior software engineers
Senior Software Engineer
Work across a project
Mentor software engineers and review code
Solve problems efficiently
Staff Software Engineer
Part of the technical team
Develop, maintain, and extend software
Ensure software meets expectations
Ensure software uses resources efficiently
Technical Lead
Manage a team of developers and engineers
Responsible for development lifecycle
Report to stakeholders
Principal Engineer/Technical Architect
Responsible for architecture and design
Create processes and procedures
Engineering Manager
Support team
Encourage career progression
Director of Engineering
Strategic and technical role
Determine project priority
Identify hiring needs
Define goals
Define new projects
Specify requirements
Chief Technology Officer (CTO)
Oversee research and development
Monitor corporate technology
Evaluate new technology and products
Other career directions
Prefer interacting with clients:
Technical sales
Customer support
Prefer working with numbers and data:
Data engineering
Data science
Database administration
Database development
Prefer finding and fixing bugs:
Software testing
Software Engineering Job Titles
Job Titles:
Front-end engineer
Back-end engineer
Full-stack engineer
DevOps engineer
Software Quality Assurance Engineer
Software Integration Engineer
Software Security Engineer
Mobile App Developer
Games Developer
Code of Ethics
Origins of the code of ethics:
Developed by the Joint Task Force on Software Engineering Ethics and Professional Practices
Institute of Electrical and Electronics Engineers Computer Society (IEEE-CS)
Association for Computing Machinery (ACM)
Championed the need to hold software engineers accountable
About the code of ethics:
Pertains to the analysis, design, development, testing, and maintenance software cycle
Dedicated to serving the public interest
The 8 principles
Public
Client/Employer
Product
Judgement
Management
Profession
Colleagues
Self
Supplemental guide to behavior
Use in conjunction with conscientious decision-making and common sense
Knowing where to apply principles is at the discretion and wisdom of the individual
Hands-on Introduction to Linux Commands and Shell Scripting
Tuples are written as comma-separated elements within parentheses
Tuples concatenation is possible
Tuple slicing is also possible
Tuples are immutable
If one want to manipulate tuples, they have to create a new tuple with the desired values
Tuples nesting (tuple containing another tuple) is also possible
Ratings=(10,9,6,5,10,8,9,6,2)
Lists
Lists are also ordered in sequence
Here is a List “L”
L=["Michael Jackson",10.1,1982]
A List is represented with square brackets
List is mutable
List can nest other lists and tuples
We can combine lists
List can be extended with extend() method
append() adds only one element to the List, if we append L.append([1,2,3,4]), the List “L” will be:
L=["Michael Jackson",10.1,1982,[1,2,3,4]]
The method split() can convert the string into the List
"Hello, World!".split()
The split() can be used with a delimiter we would like to split on as an argument
"A,B,C,D".split(",")
Multiple names referring to the same object is known as aliasing
We can clone the list, where both lists will be of their independent copies
So changing List “A”, will not change List “B”
Dictionaries
Dictionaries are denoted with curly Brackets {}
The keys have to be immutable and unique
The values can be immutable, mutable and duplicates
Each key and value pair is separated by a comma
Sets
Sets are a type of collection
This means that like lists and tuples you can input different python types
Unlike lists and tuples they are unordered
This means sets don’t record element position
Sets only have unique elements
This means there is only one of a particular element in a set
Sets: Creating a Set
You can convert a list into set
List=['foo']set(List)
To add elements to the set, set.add('foo')
To remove an element, set.remove(‘foo’)
To check if an element is present in the set:
'foo'insetTrue/False
Sets: Mathematical Expression
To find the intersection of the sets elements present in the both sets), set1 & set2 or set1.intersection(set2)
Union of the sets, contain elements of both the sets combined, set1.union(set2)
To find the difference of sets:
#set1 difference from set2set1.difference(set2)#set2 difference from set 1set2.difference(set1)
To find is a set is a subset/superset (have all the elements of other set), `set1.issubset/issuperset(set2)
Digital Marketing
Search Engine Optimization (SEO) Specialization
This specialization is offered by UCDAVIS over Coursera. There are 4 Courses and a Capstone Project in this specialization.
Info
I got access to the first course for free and have completed it; it was worth my time. However, the rest of the specialization requires payment, which I am not inclined to make at the moment as I currently have no use case for the knowledge I would gain.
This specialization is offered by UCDAVIS over Coursera. There are 4 Courses and a Capstone Project in this specialization.
Info
I got access to the first course for free and have completed it; it was worth my time. However, the rest of the specialization requires payment, which I am not inclined to make at the moment as I currently have no use case for the knowledge I would gain.
Fictional characters representing specific users of a website
Personas help build user-centered sites & incorporate correct keywords naturally
Create multiple personas to appeal to a variety of buyers
Couple of questions about our buyers
Persona’s Age
Age could impact keyword choices due to lexicon differences
Persona’s Location
Persona’s location Important in case of regional vocabulary differences
Persona’s Gender
Buyer’s gender can influence vocabulary
Gender plays a larger role in than just their vocabulary
Sites might need a persona for both genders
An image of a person brings your persona to life
Add lots of details, since it will guide your site optimization
Add additional information for your reference if applicable
for example: Is it a B2B or B2C persona?
More
Subsections of MORE
WIKI GitHub
Credits
“This section acknowledges the incredible creators and resources that have contributed to building and enriching this site. From themes to tools, here’s a note of gratitude for their work and inspiration.”
Coursera
A big thanks to Coursera for offering a platform that provides high-quality learning opportunities and world-class courses.
Google
Gratitude to Google Eduction for their well-structured and insightful courses that have contributed to my knowledge and skills.
IBM
Special thanks to IBM Skills Network Team for their valuable courses, helping to deepen my understanding of cutting-edge technologies and concepts.
TryHackMe
Appreciation to TryHackMe for their interactive and hands-on cybersecurity labs, which have greatly enhanced my practical skills in information security.
Khan Academy
Heartfelt thanks to Khan Academy for their free, high-quality educational resources that make learning accessible to everyone, everywhere.
Udemy
Thanks to Udemy for their diverse range of courses and expert instructors, enabling me to learn new skills at my own pace.
Other Course Providers
Appreciation to all the institutions and instructors whose courses have helped me grow and whose content I’ve referenced in my notes.
Welcome to NOTES WIKI. This Privacy Policy explains how we collect, use, and protect information when you visit our website.
2. Information We Collect
2.1 Personal Information
We do not collect personally identifiable information (PII) from visitors.
2.2 Non-Personal Information
We use Cloudflare Insights to monitor site performance, security, and analytics. This tool may collect anonymized data, including:
Browser type, device, and operating system
IP addresses (for security and performance analysis)
Page load times and general site interaction metrics
For details on how Cloudflare handles data, please refer to their Privacy Policy.
3. Cookies
We do not use tracking cookies. However:
Session storage cookies are used to remember your dark theme preference. These are temporary and deleted when you close your browser.
Cloudflare Insights may use functional cookies for performance monitoring and security.
4. Third-Party Links
Our website may contain links to third-party sites. We are not responsible for their privacy practices. Please review their policies before sharing information.
5. Children’s Privacy
Our site is not intended for individuals under 13. If we unintentionally collect any such data, contact us, and we will delete it promptly.
6. Your Rights
If applicable under laws like GDPR or CCPA, you may have the right to:
Access, correct, or delete your data.
Object to certain data processing.
For requests, please contact us using the information below.
7. Changes to This Privacy Policy
We may update this Privacy Policy periodically. Any changes will be posted on this page.
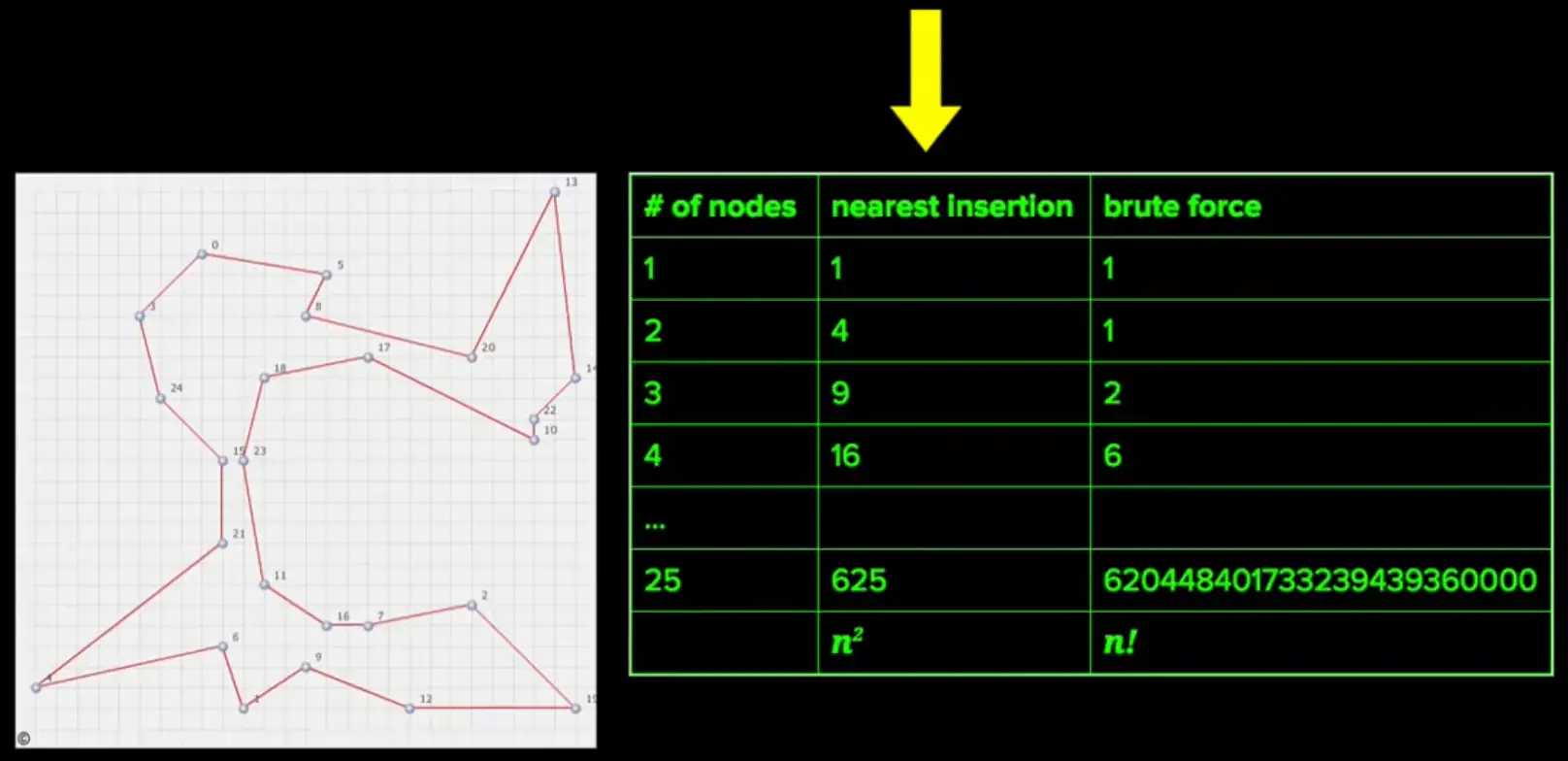



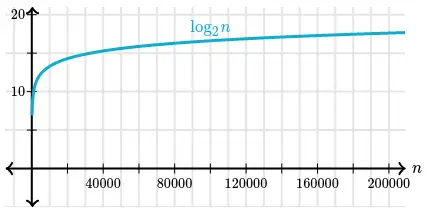
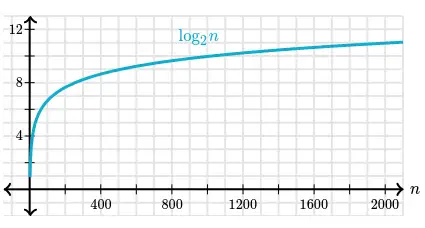
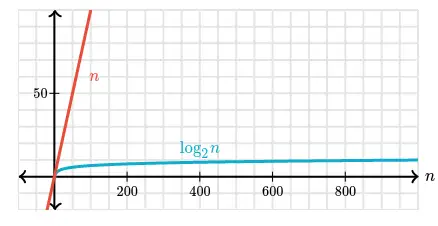
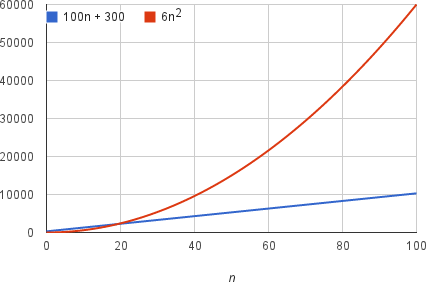
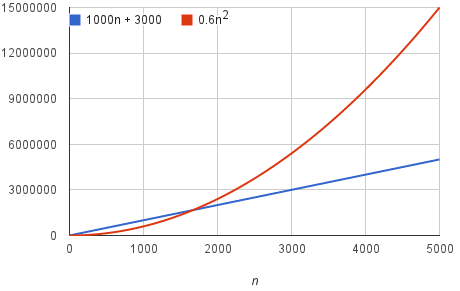




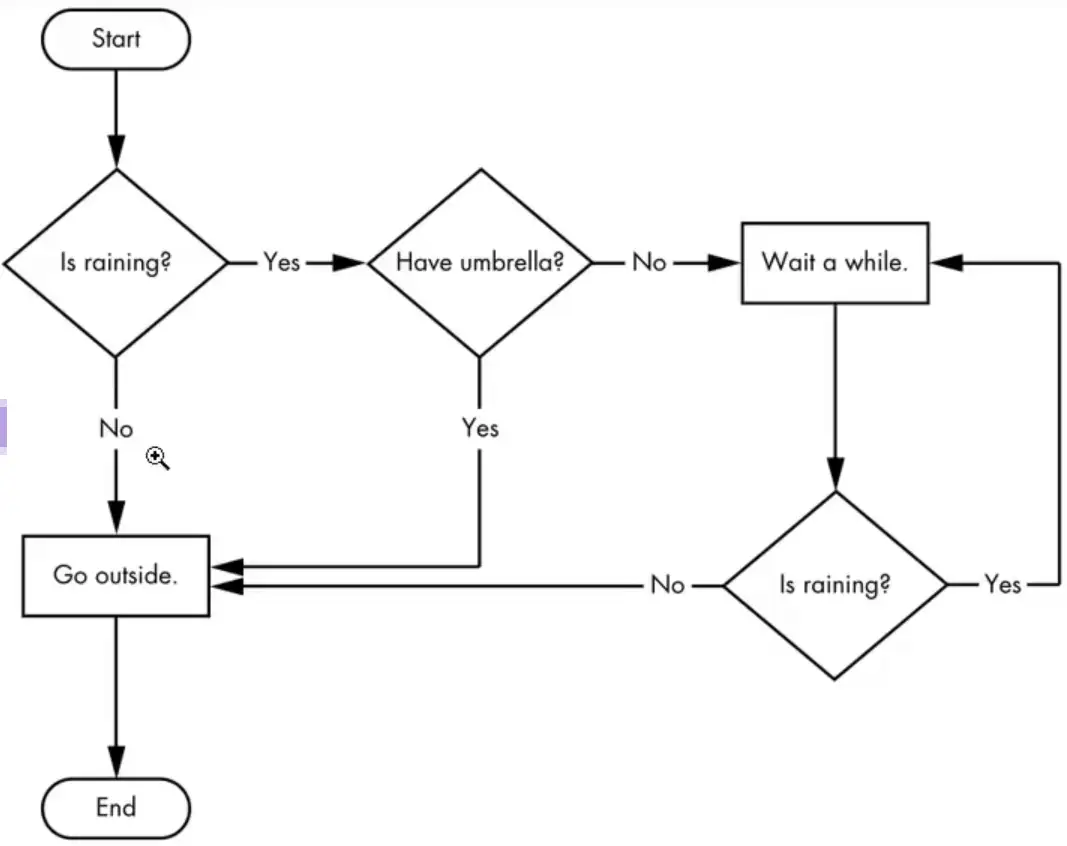
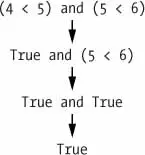
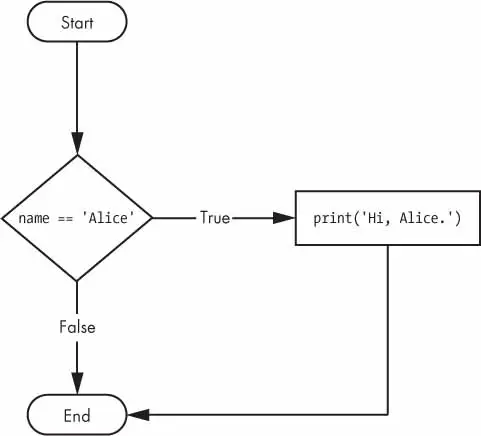
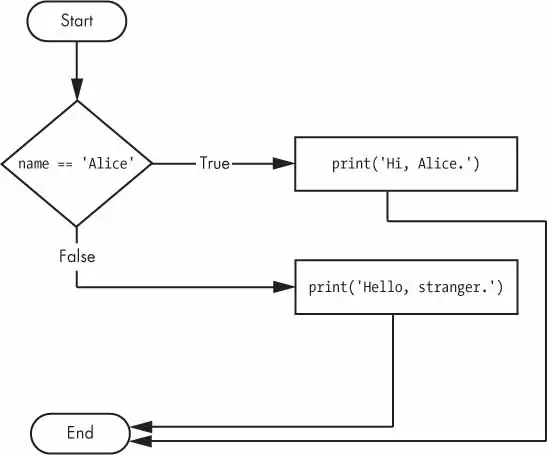
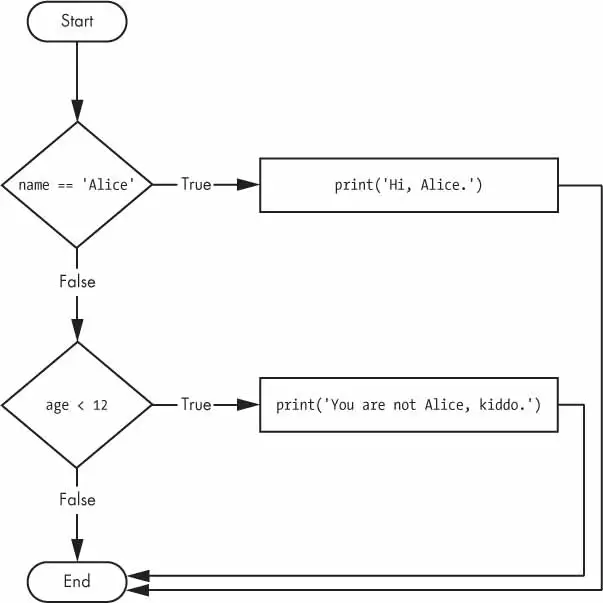
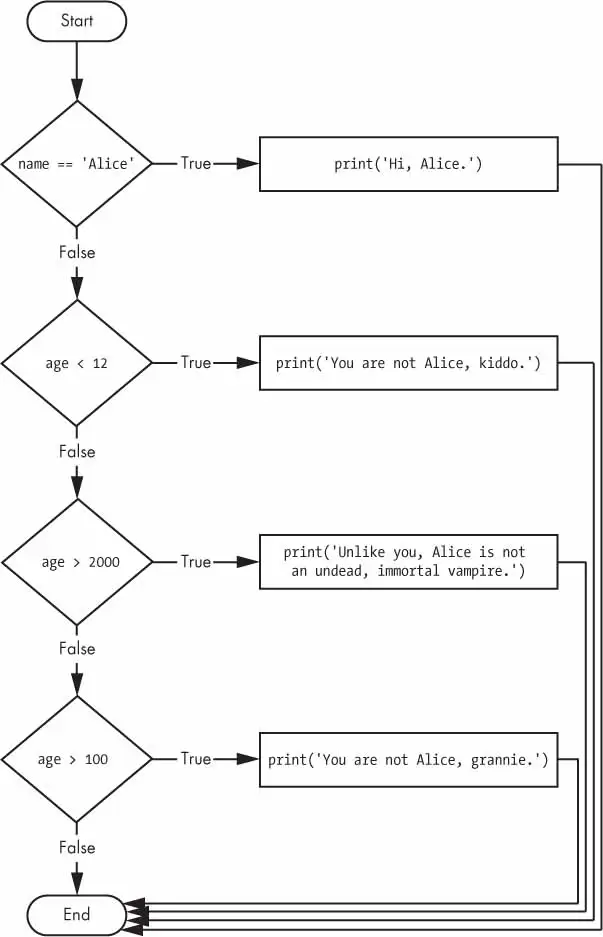
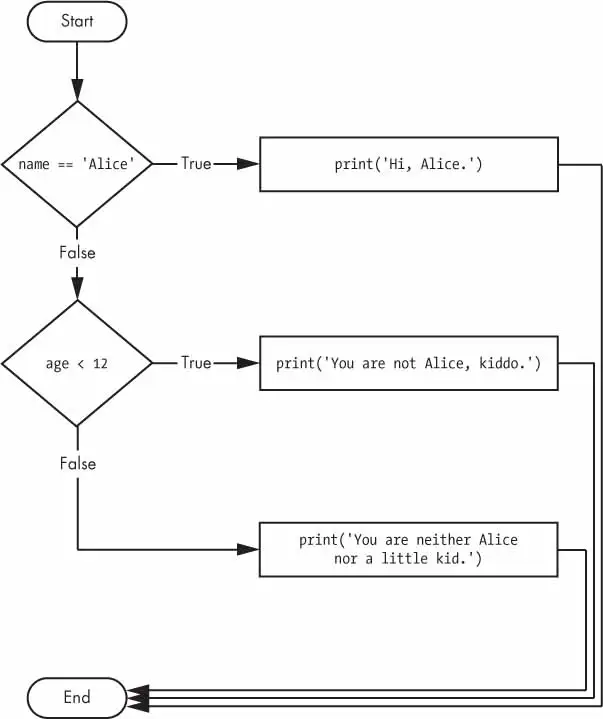

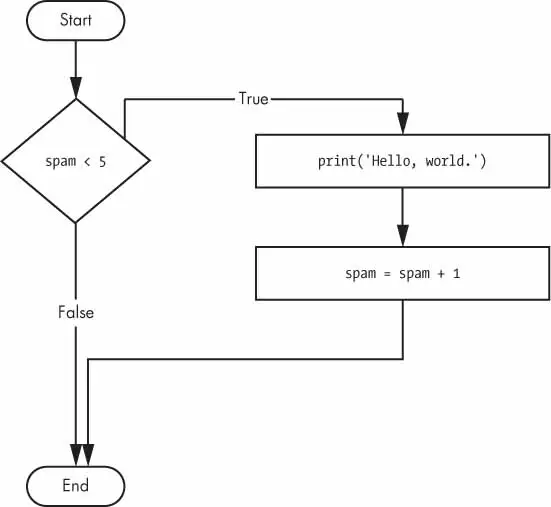
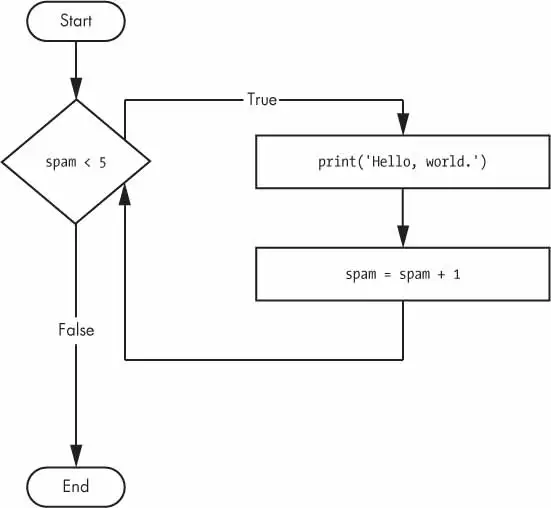
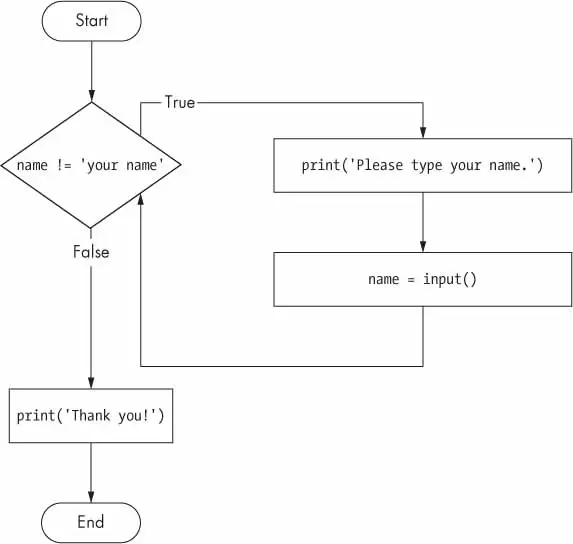
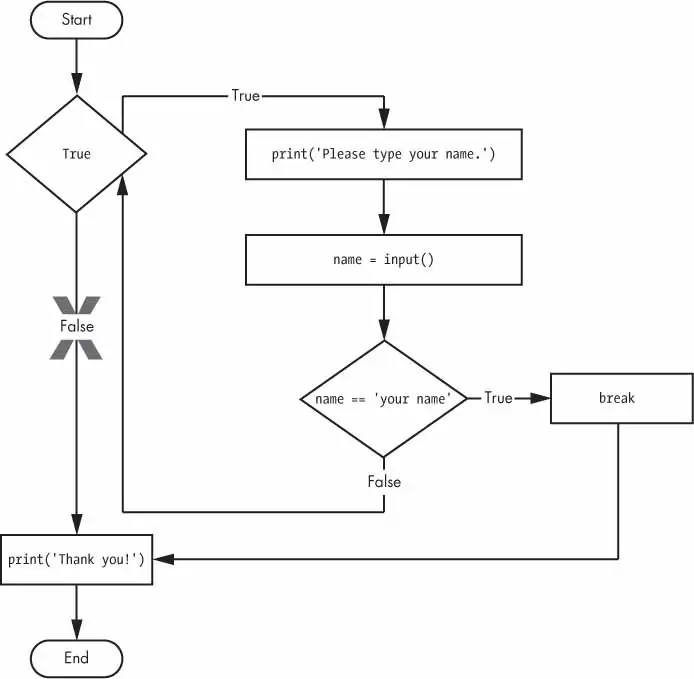
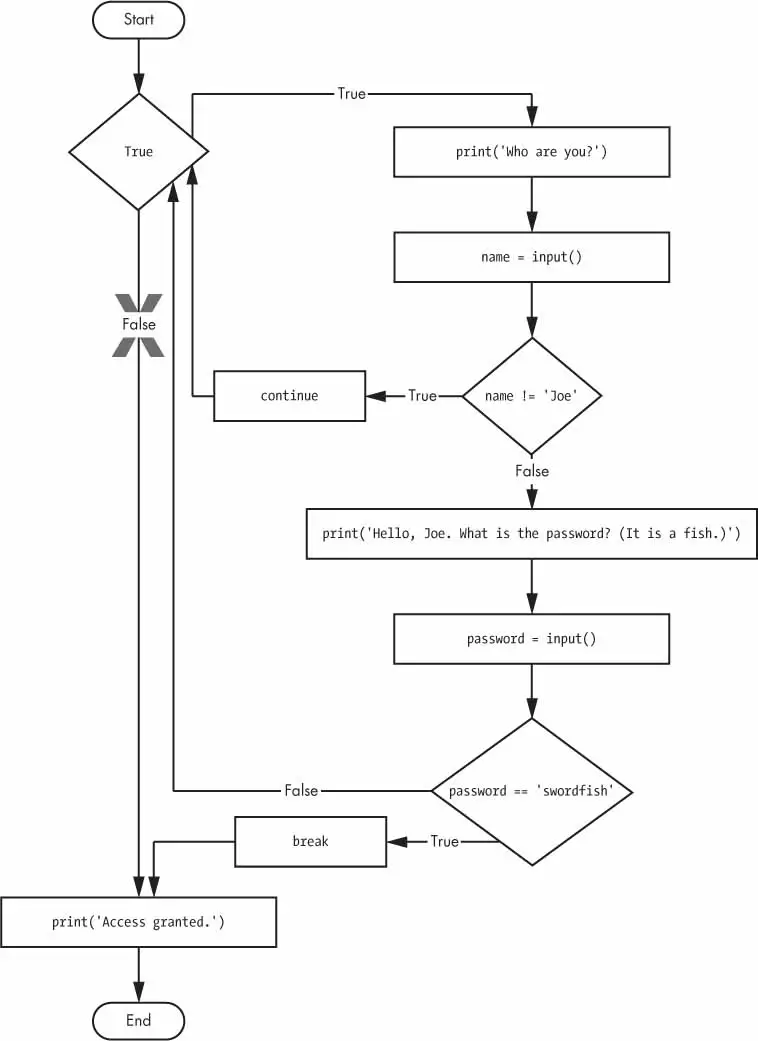
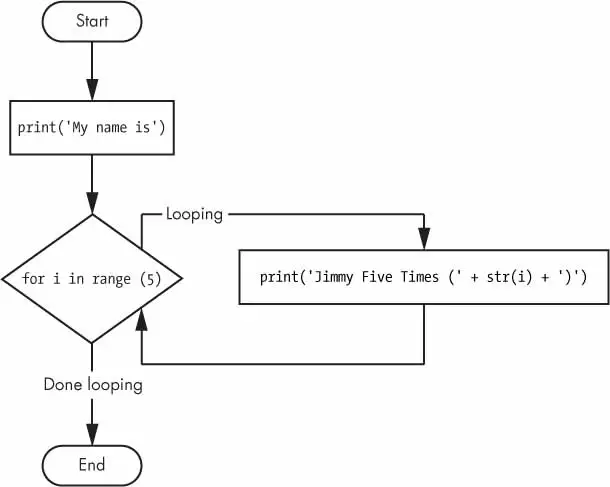



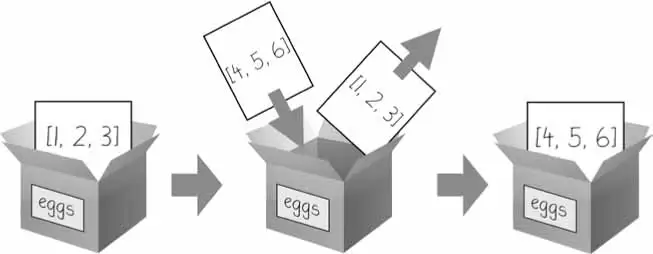
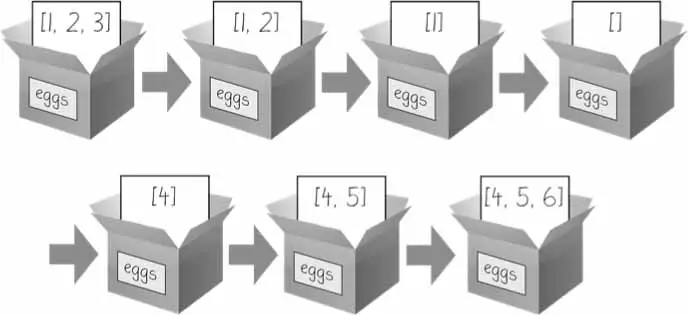
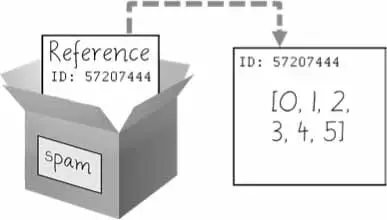
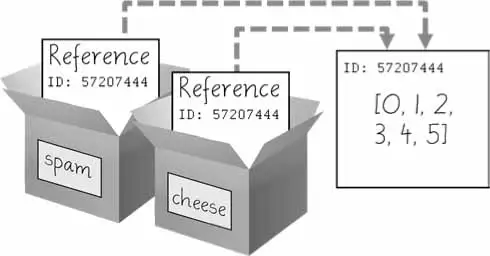
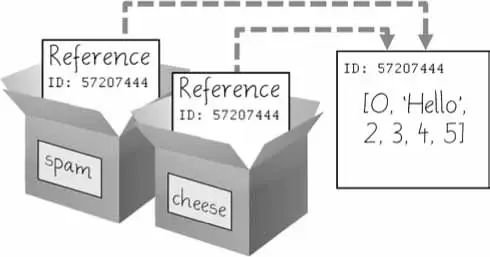
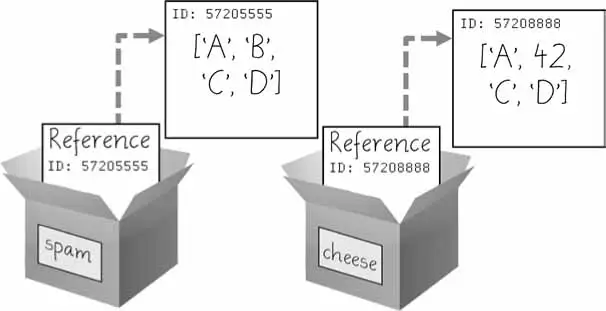

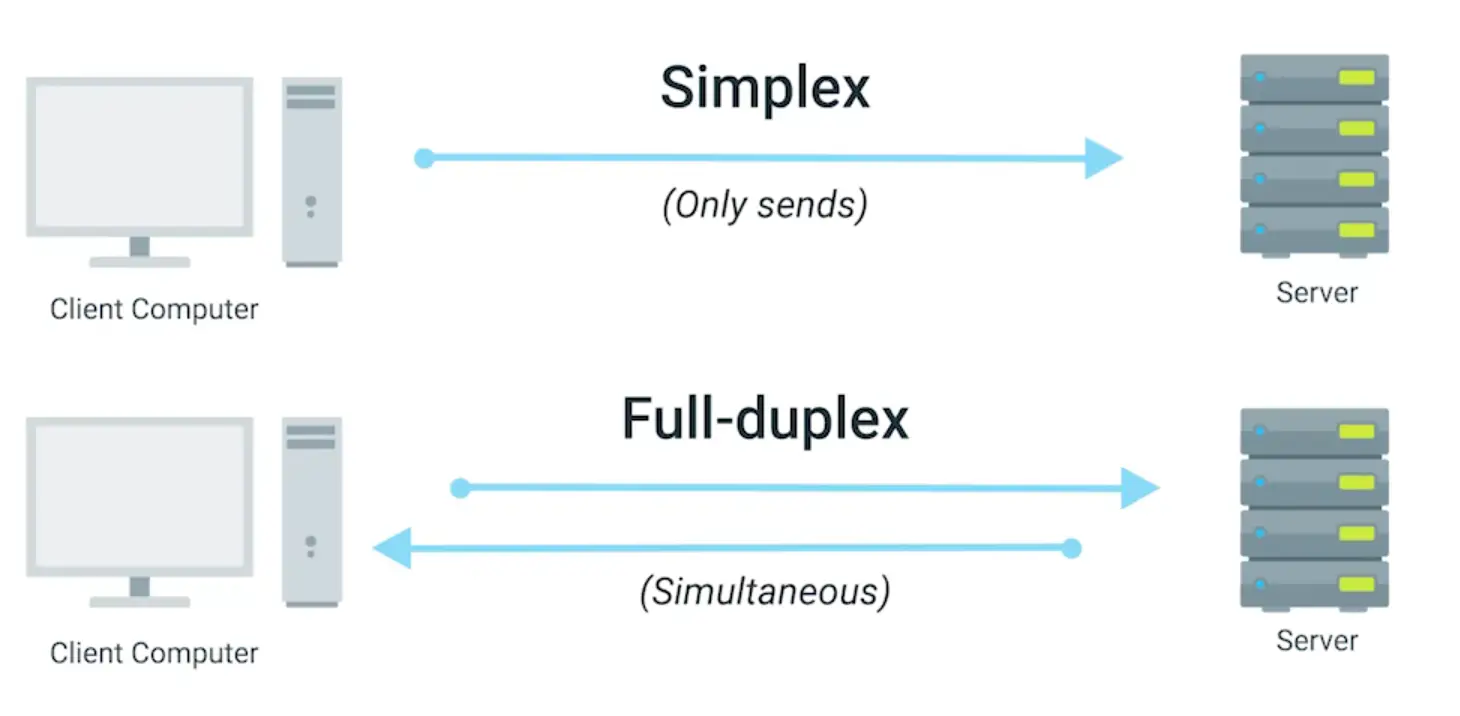

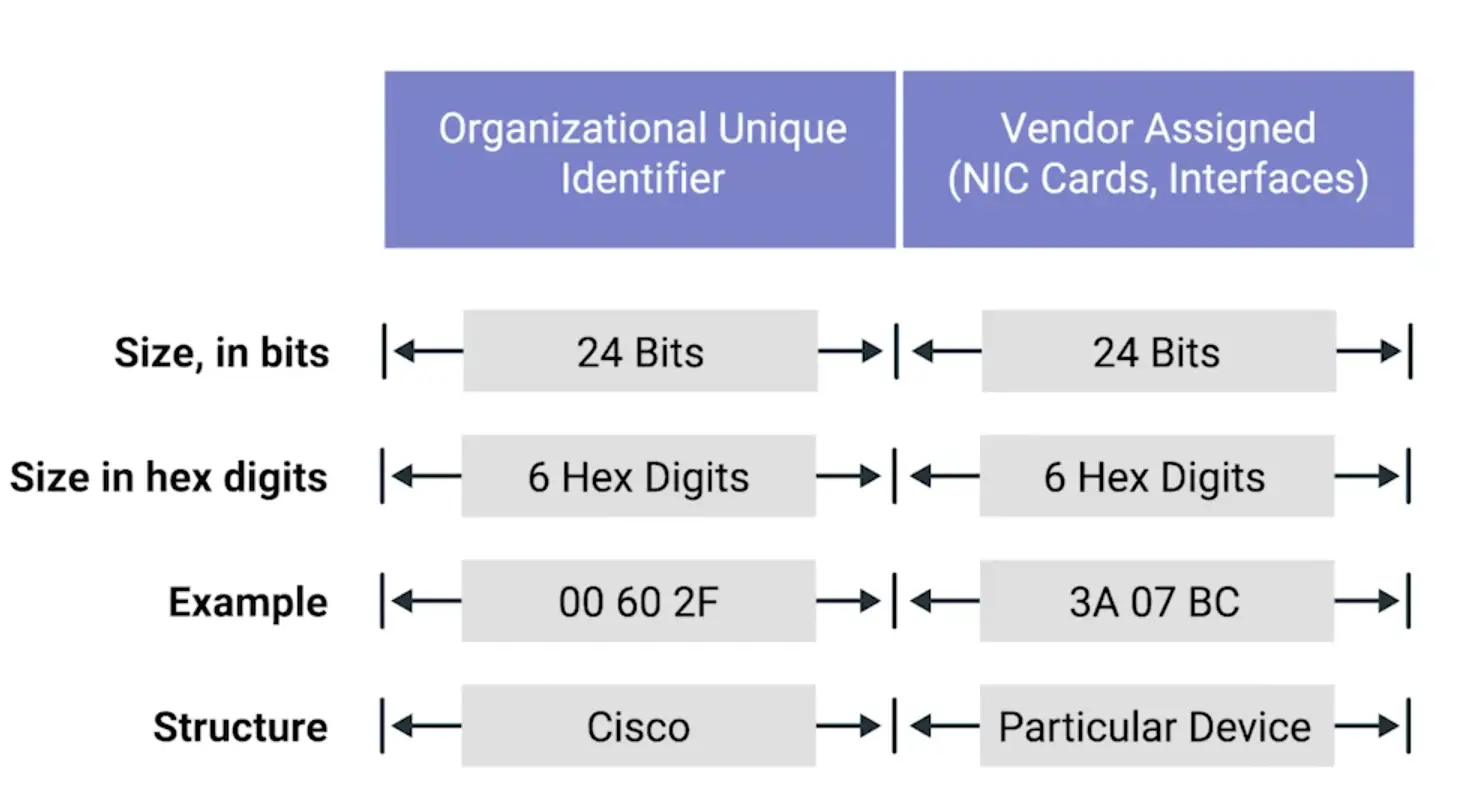
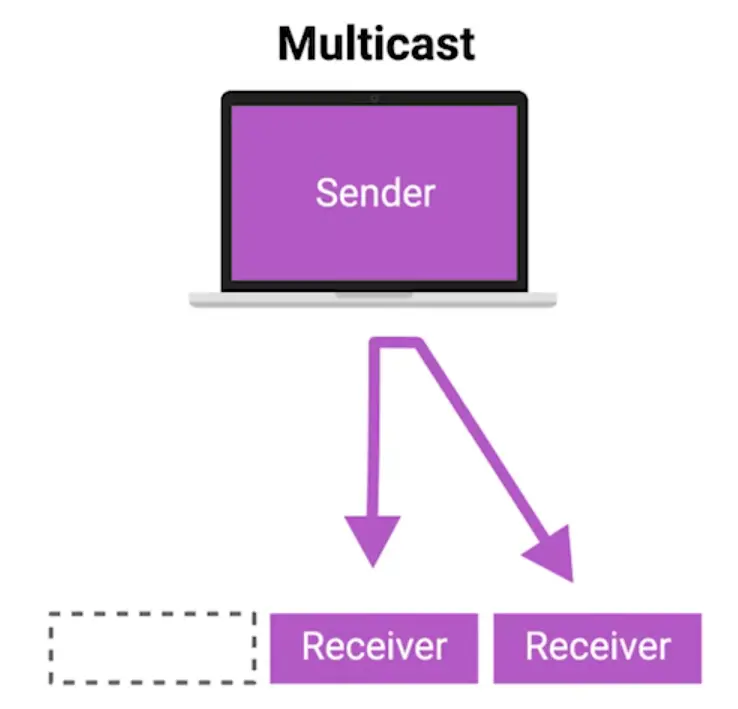
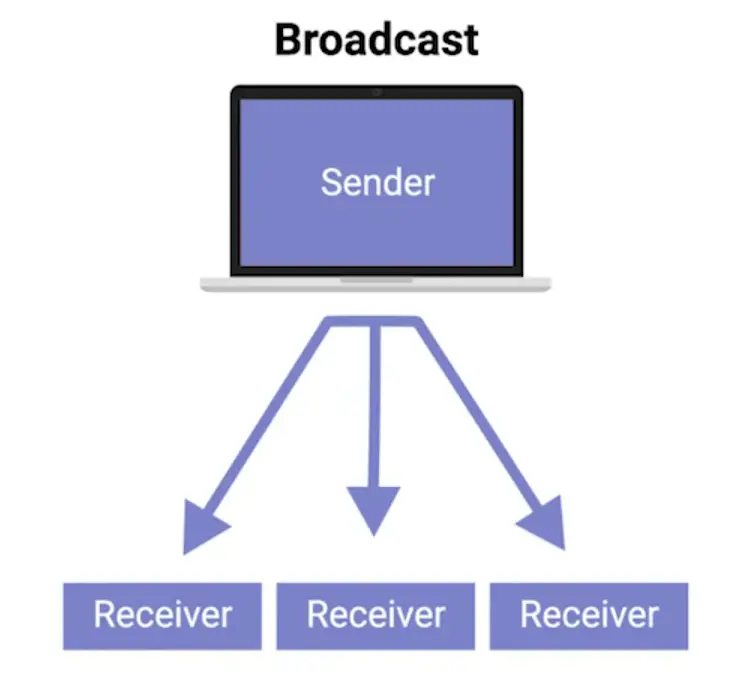

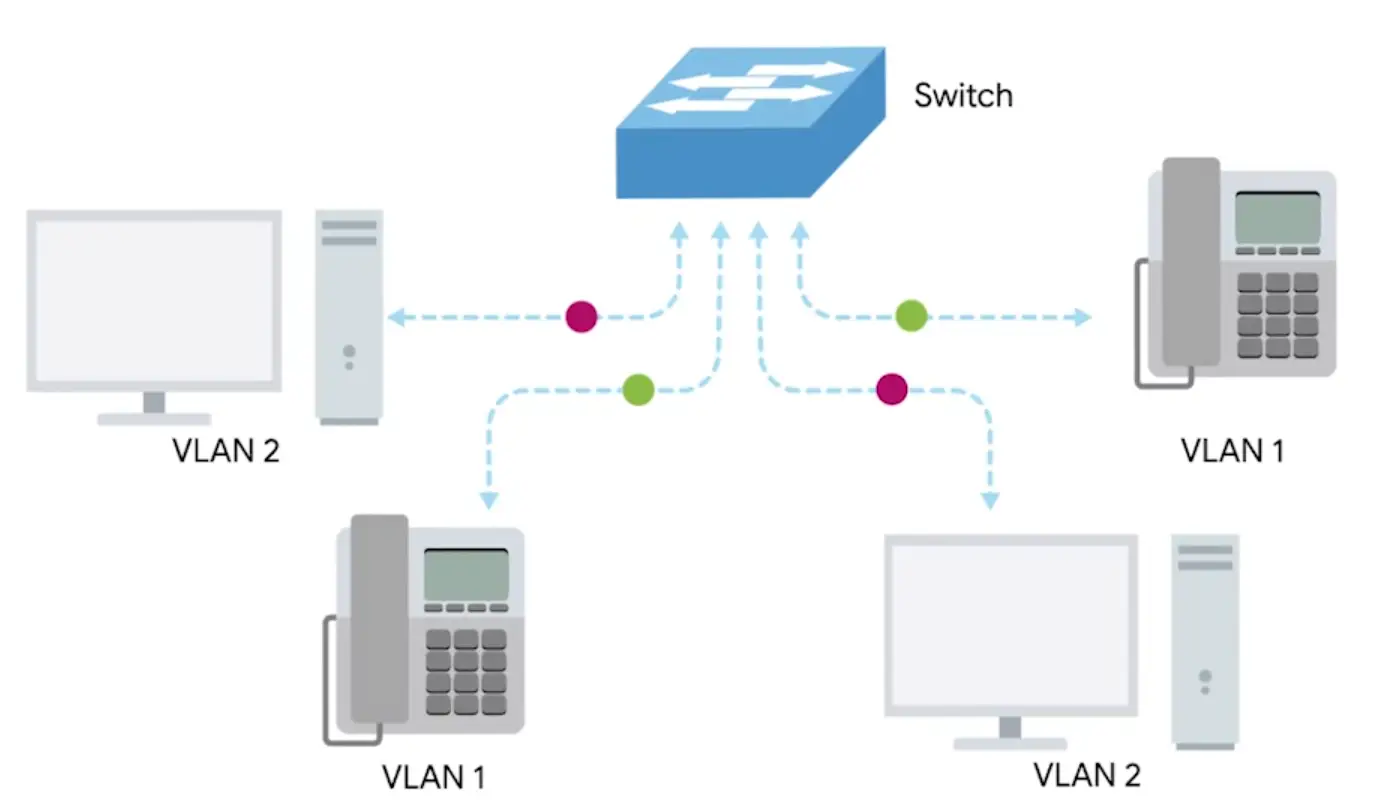

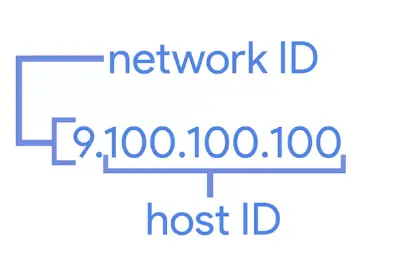

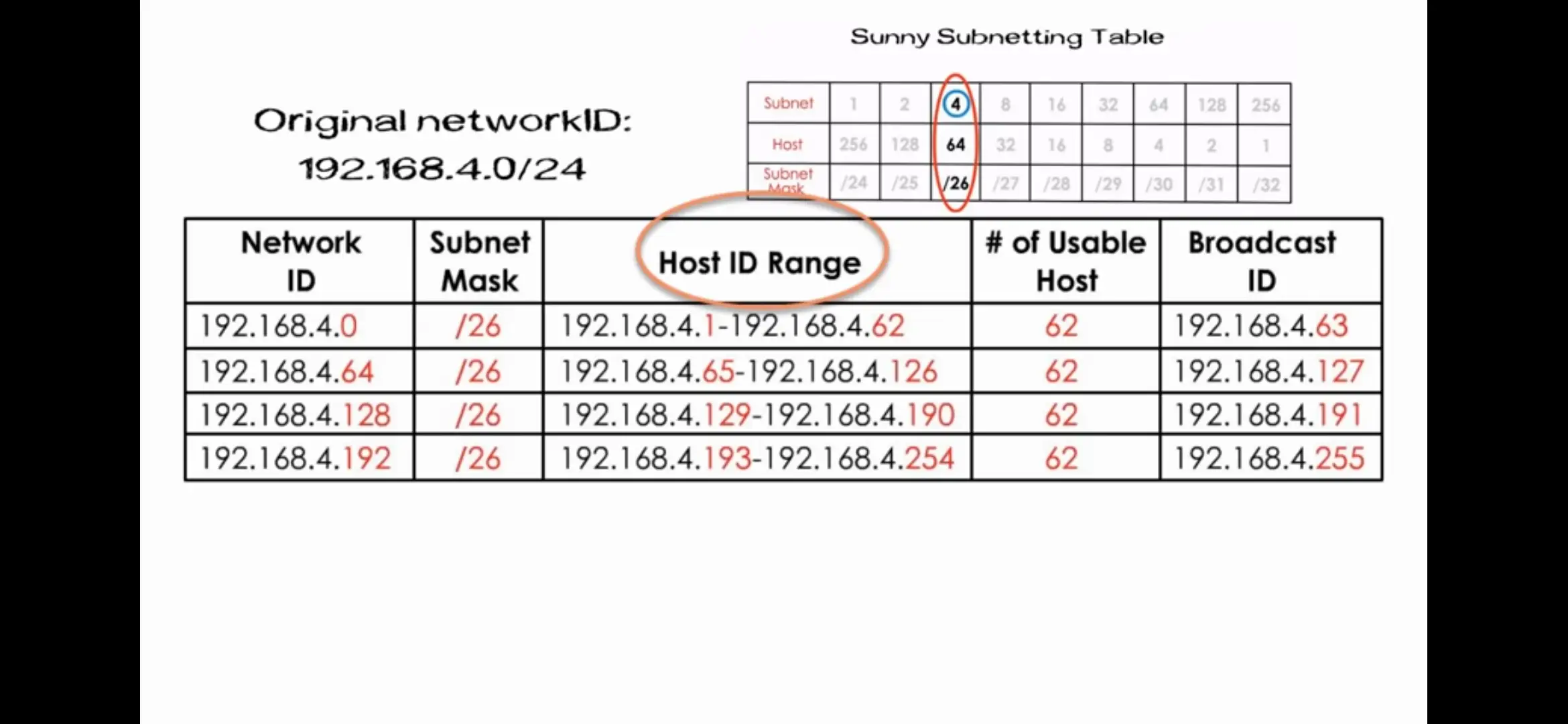


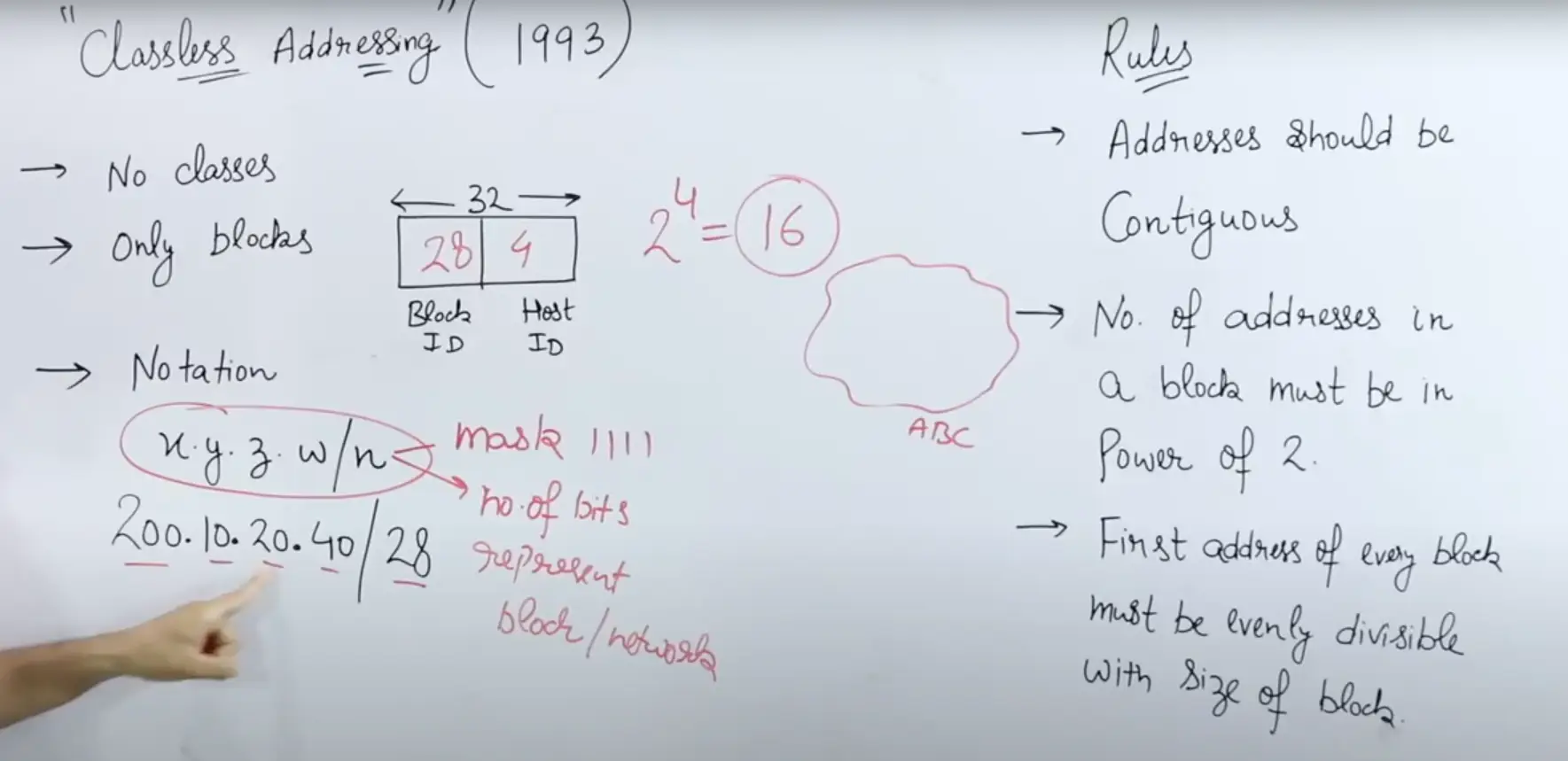
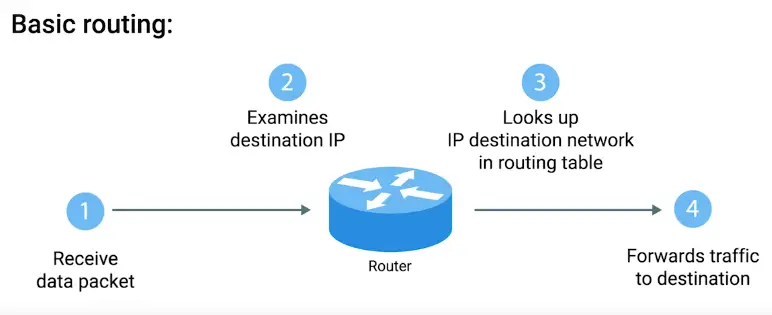
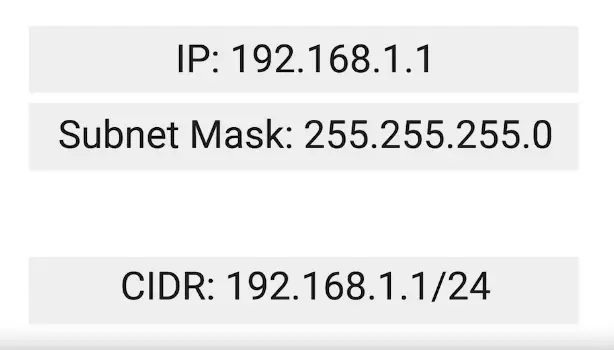


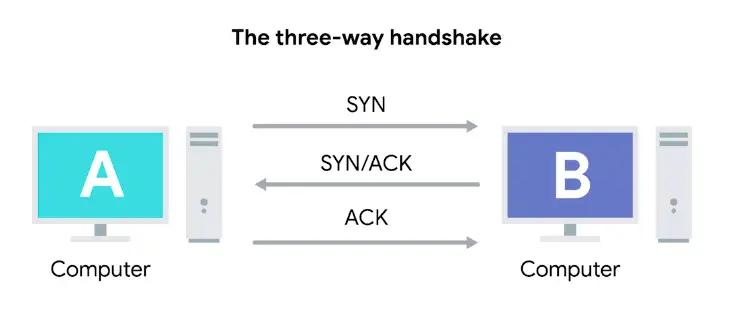
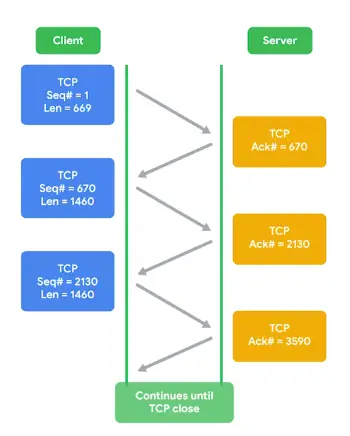
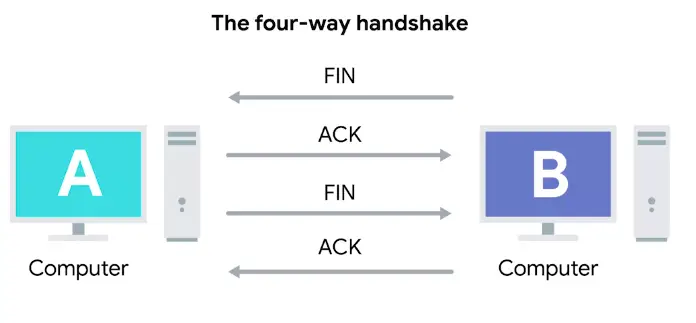
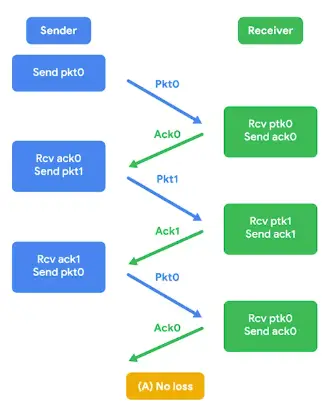
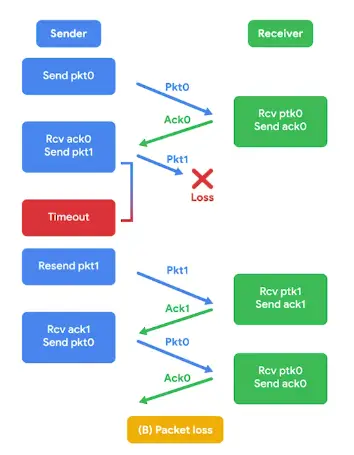
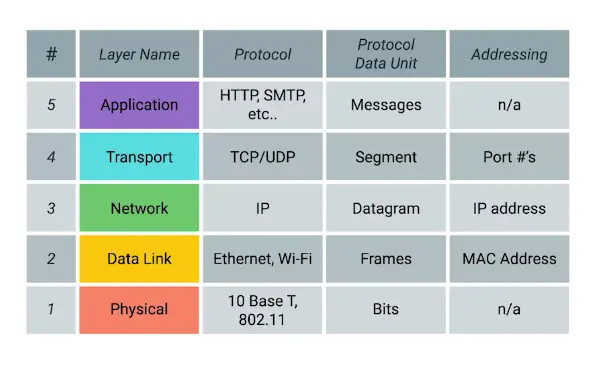
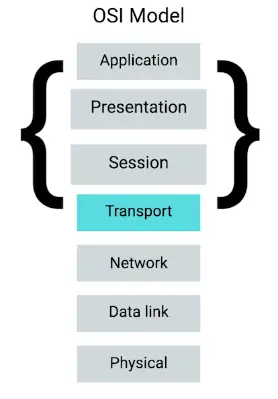
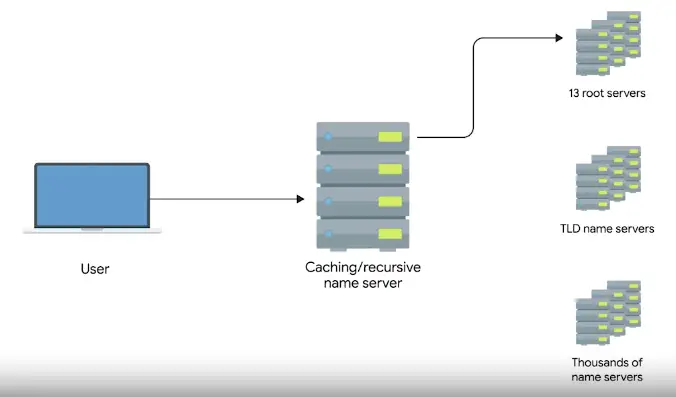
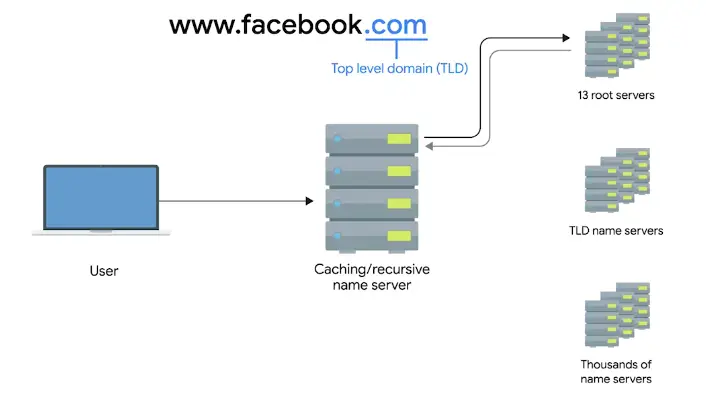
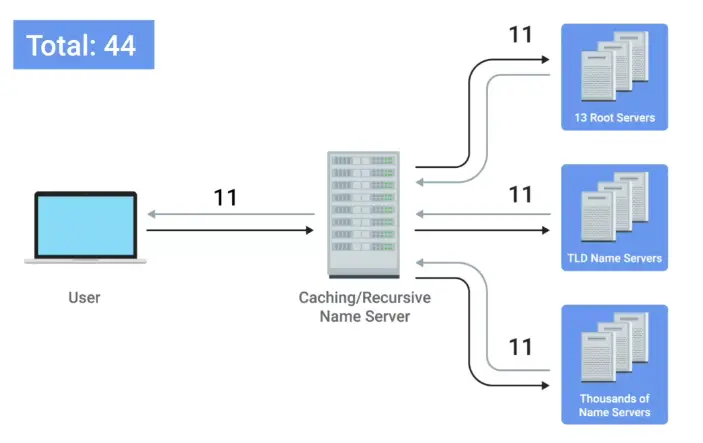
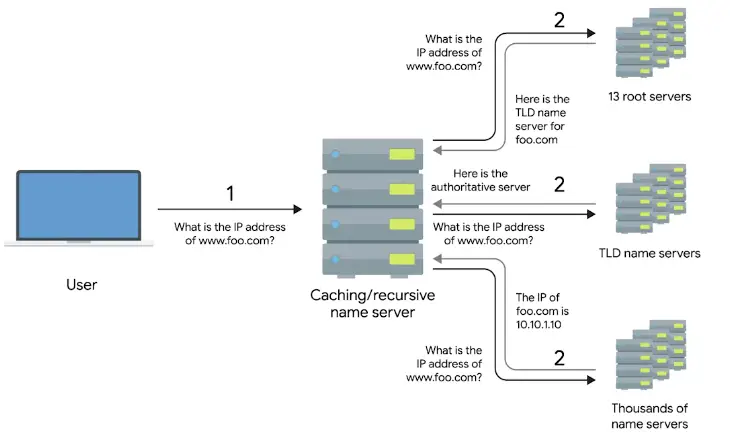
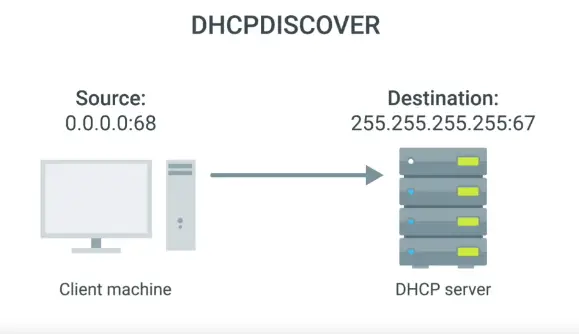
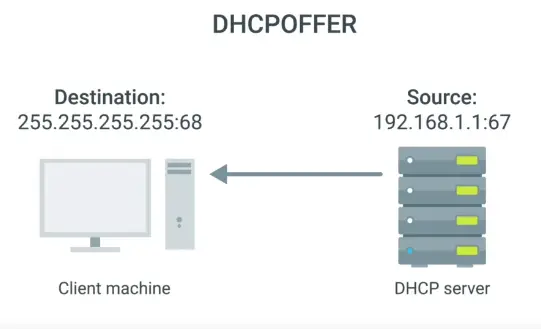
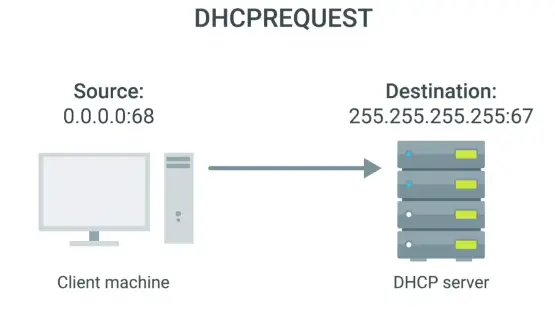
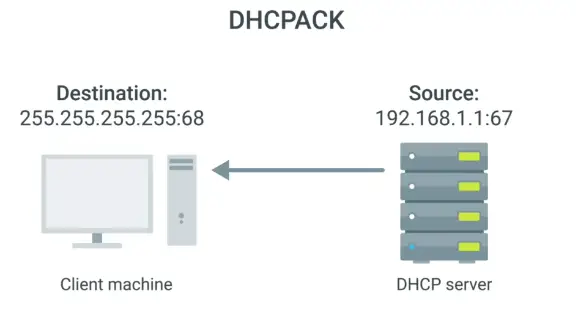
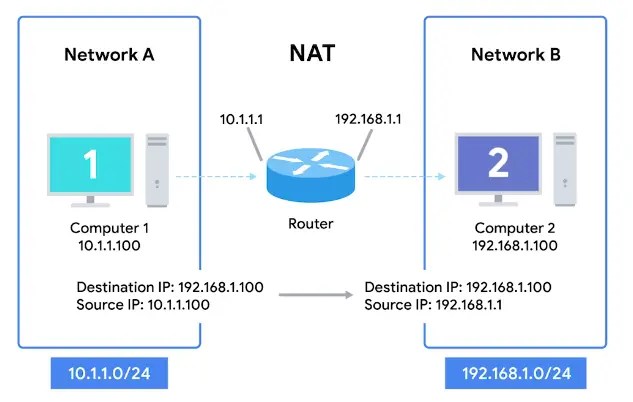
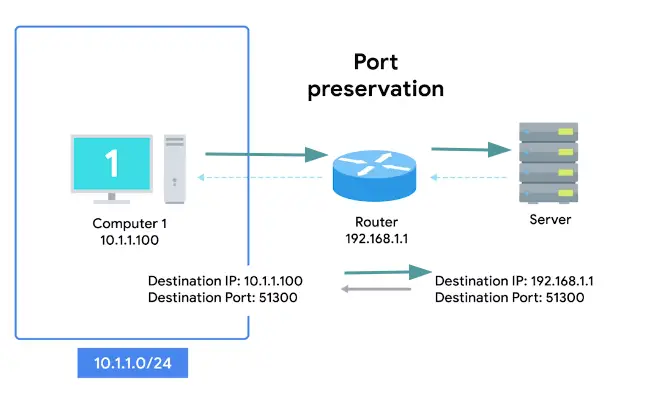
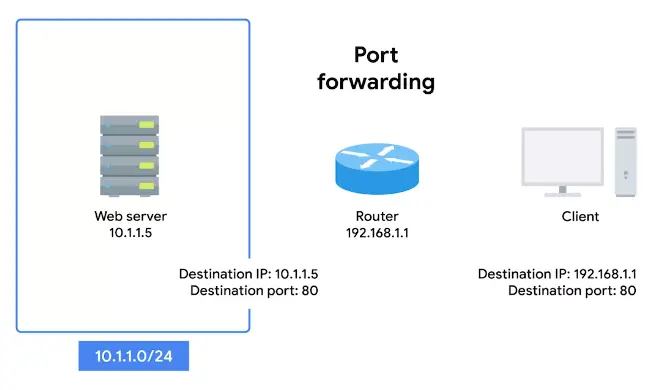
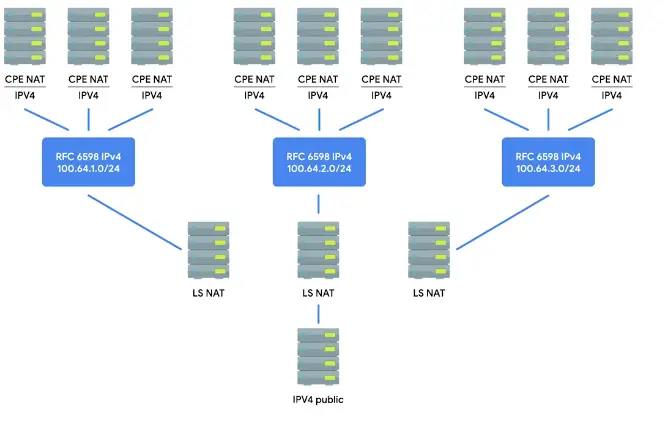
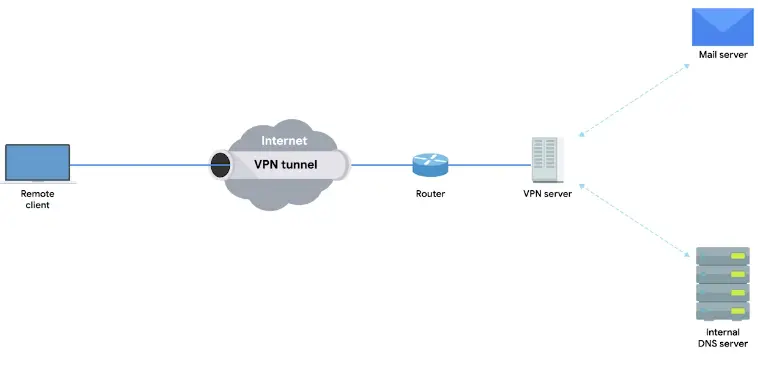
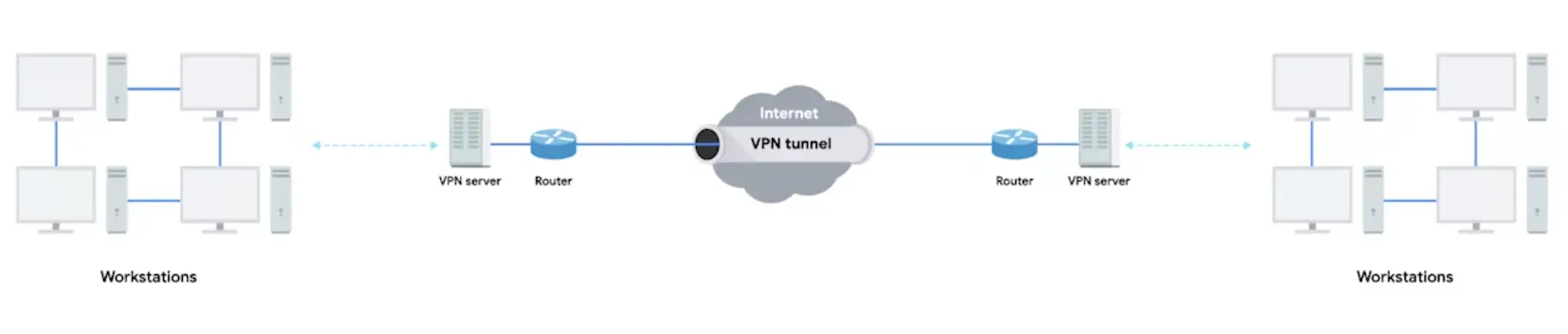
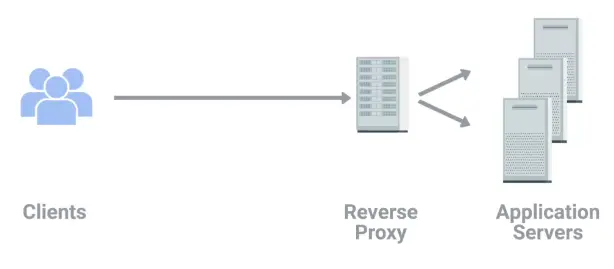
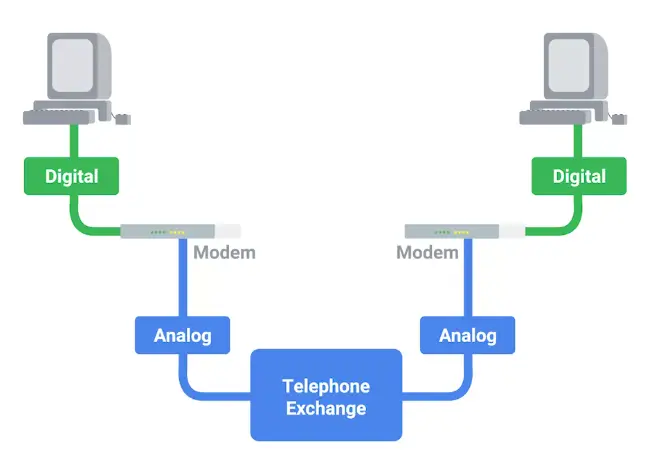
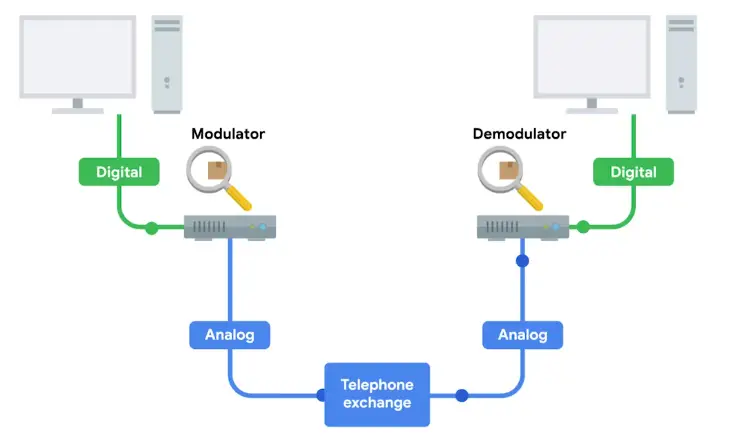
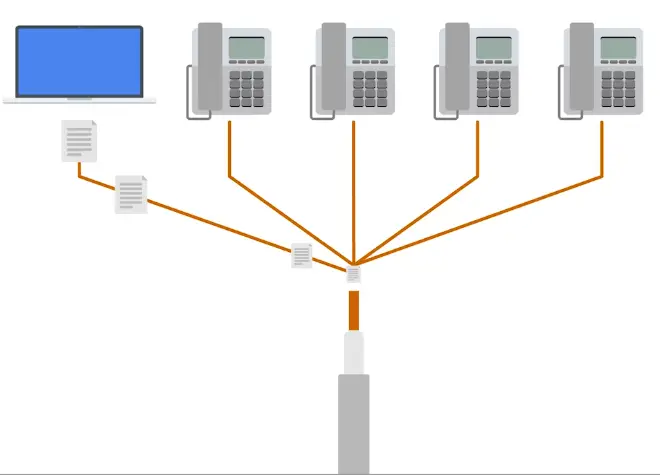
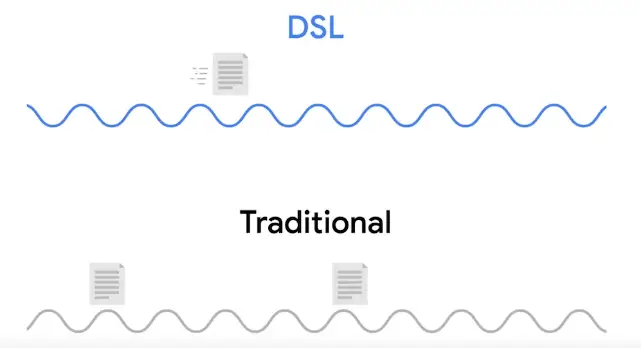
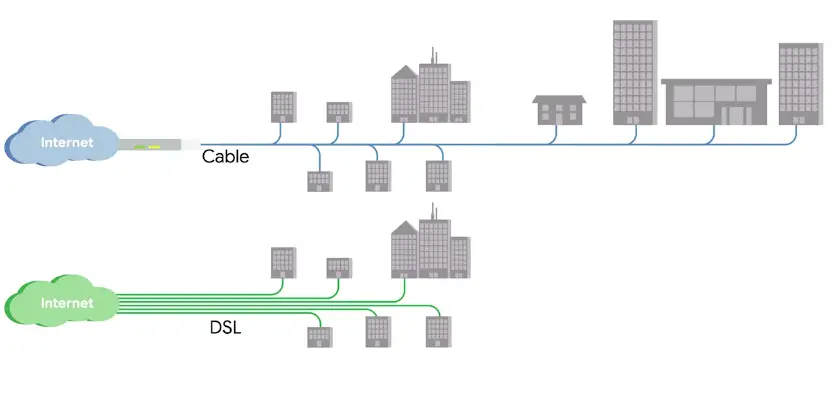
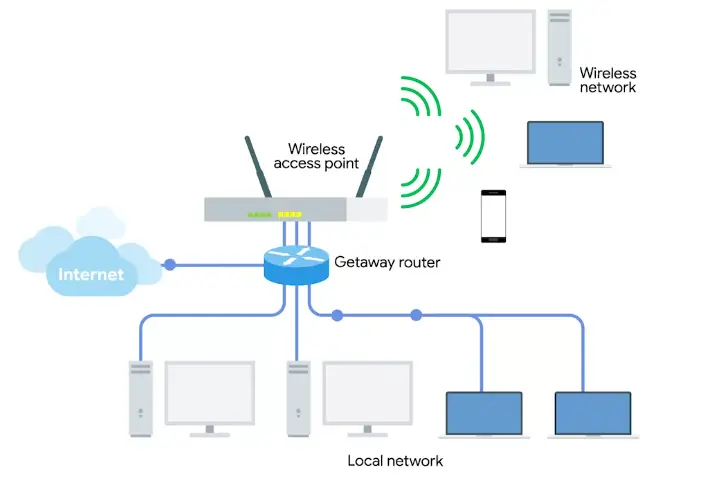
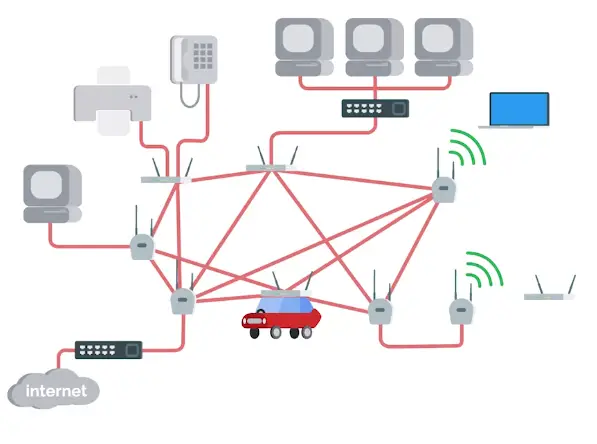
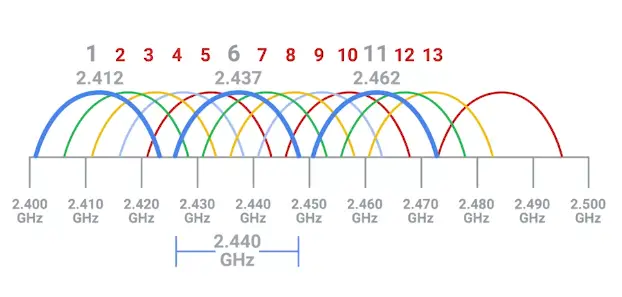
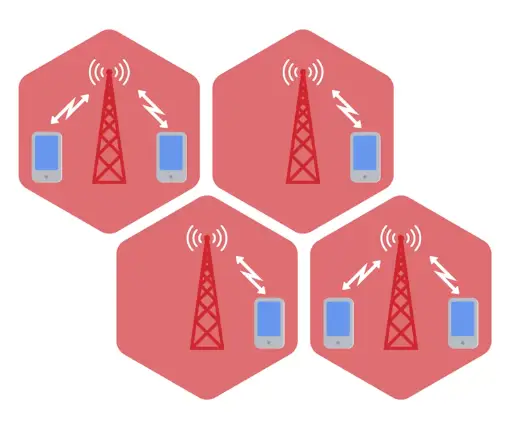
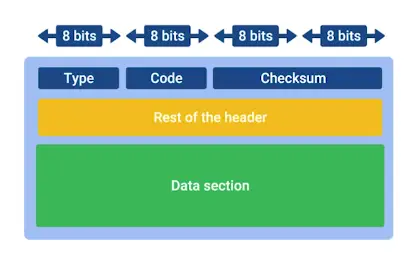
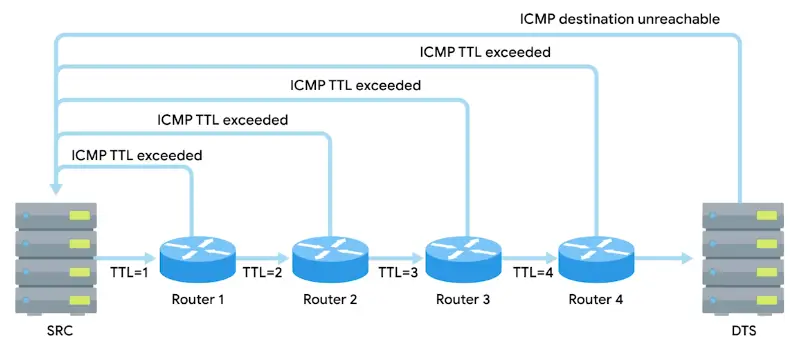
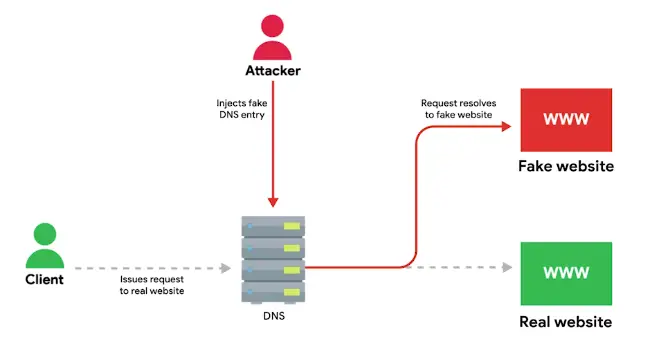
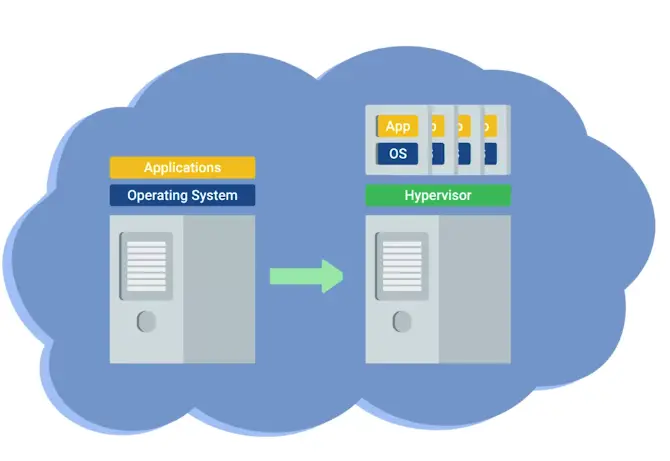


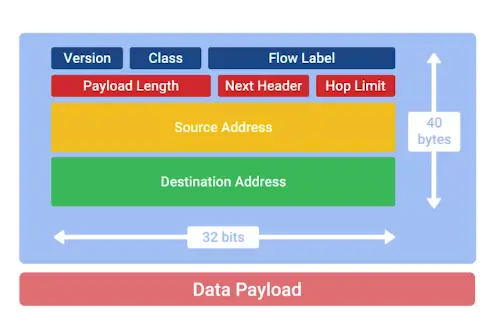








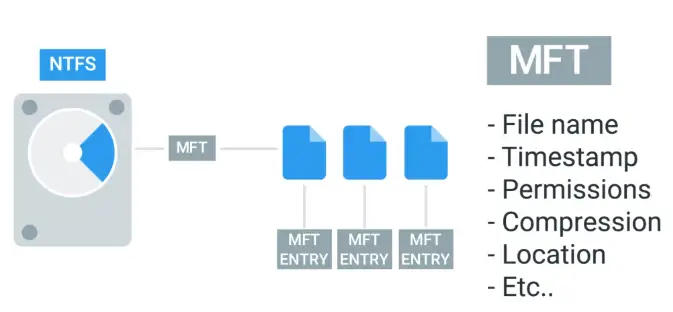
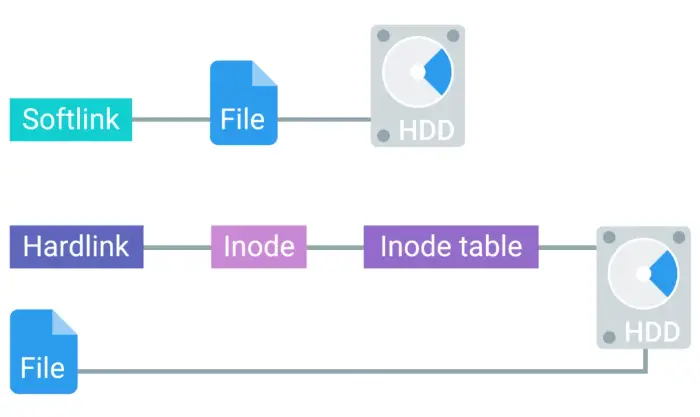
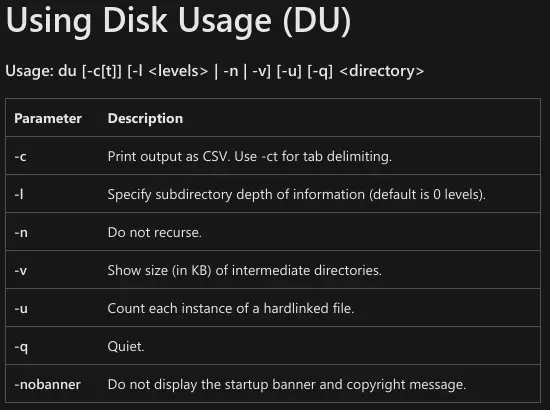
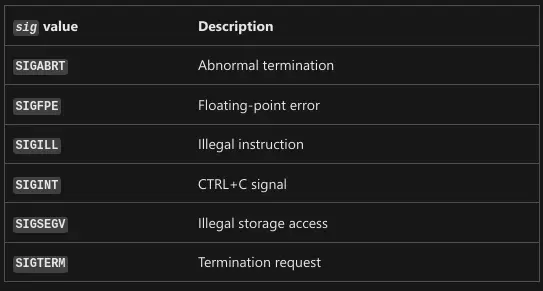

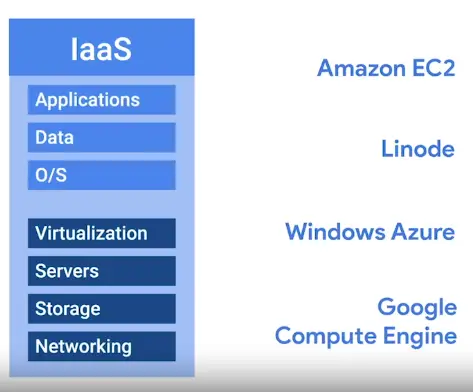


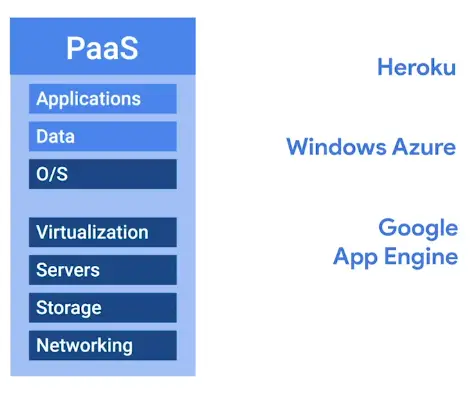
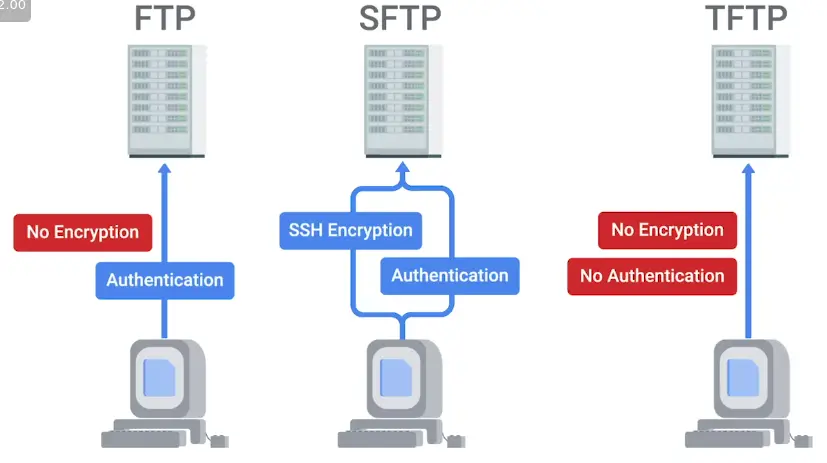
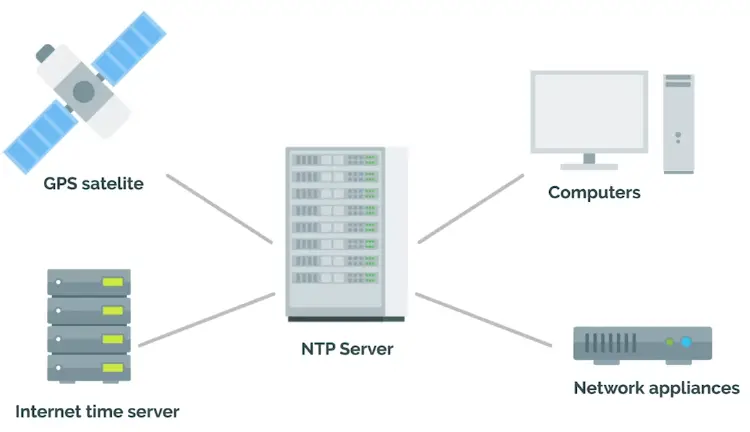
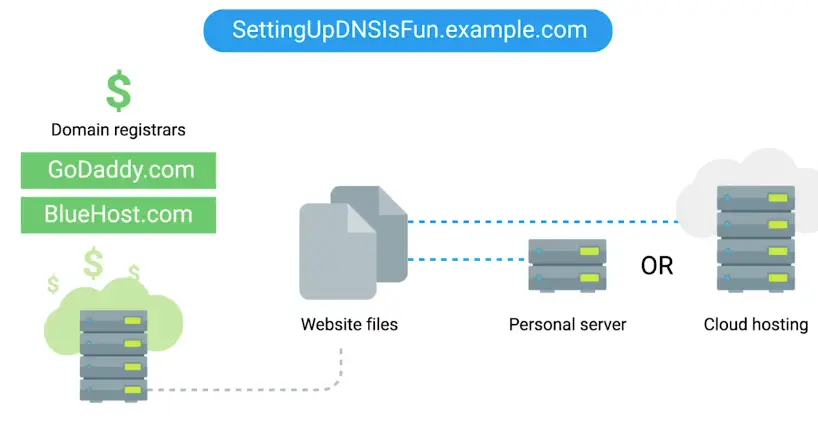
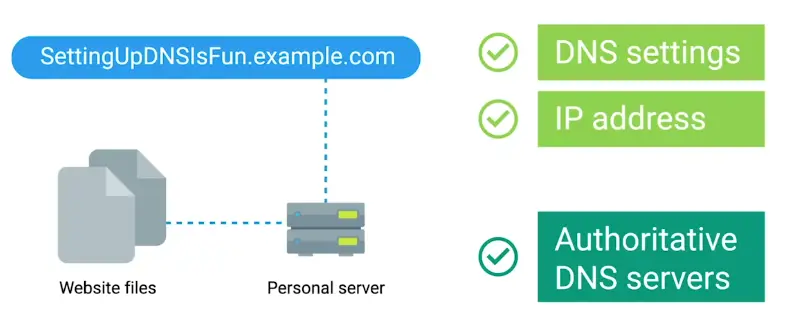
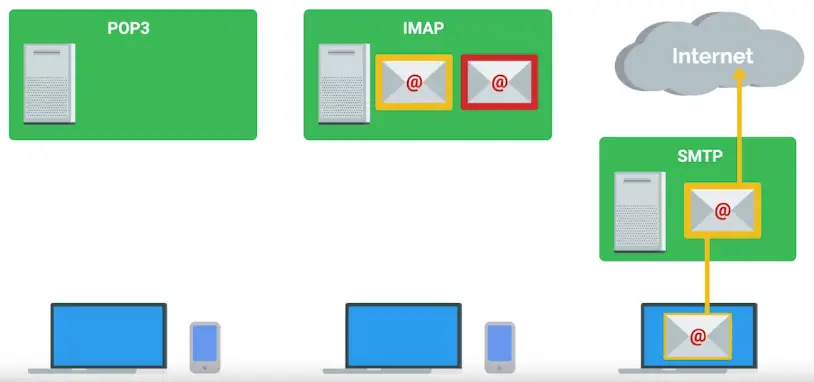
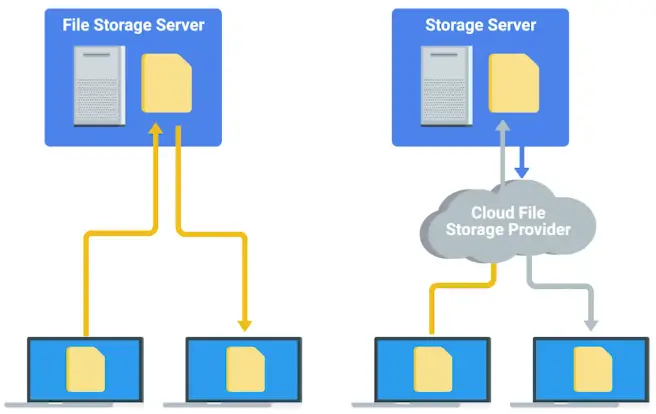
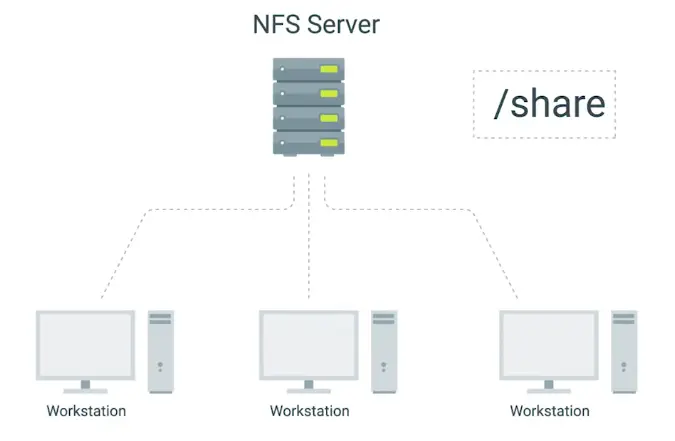
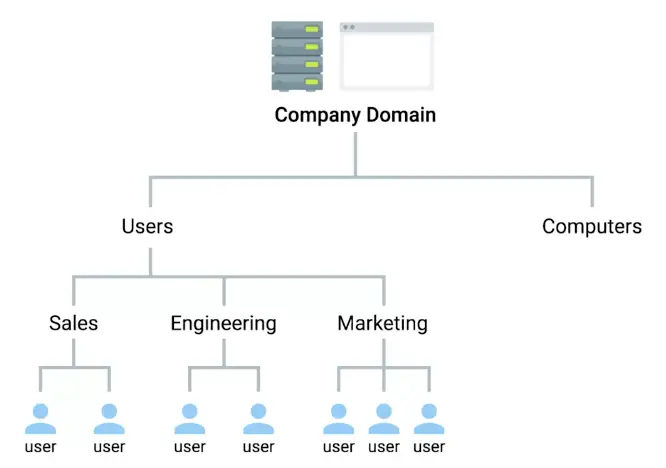

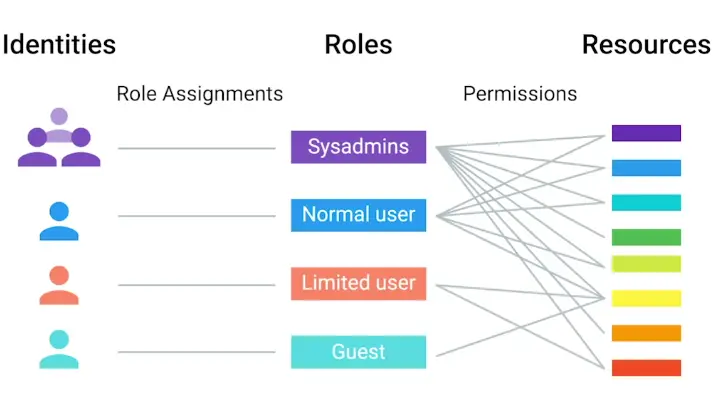
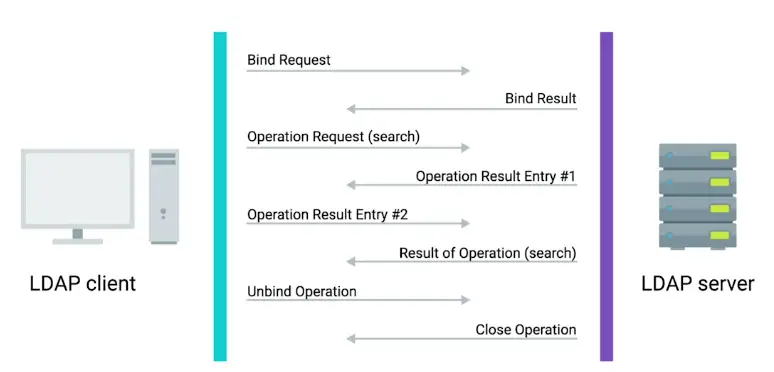
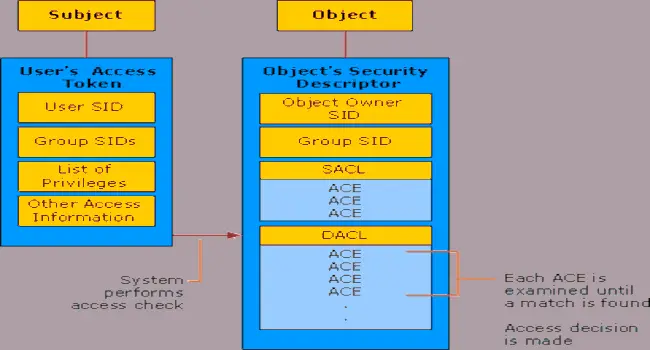

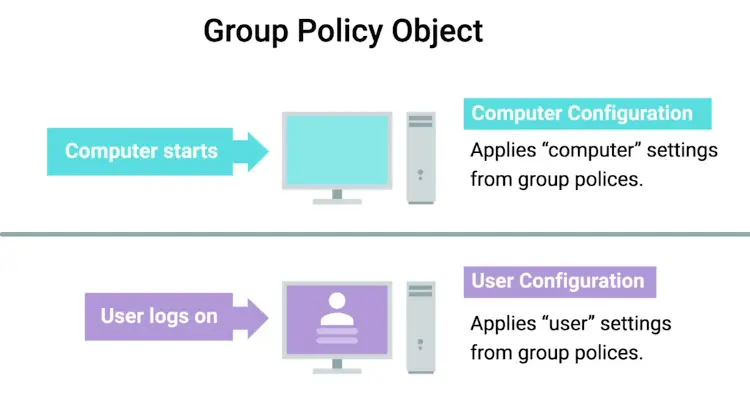
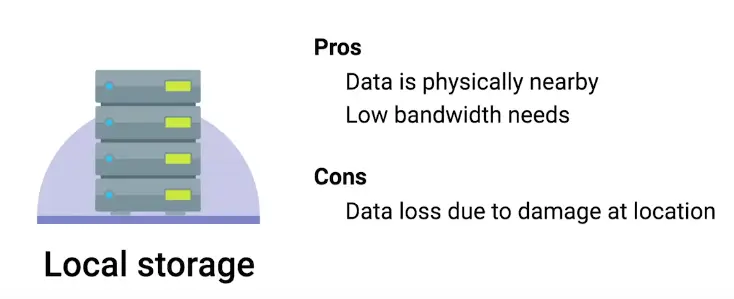

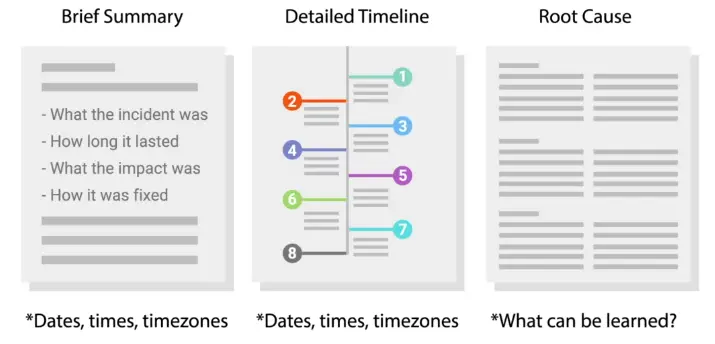
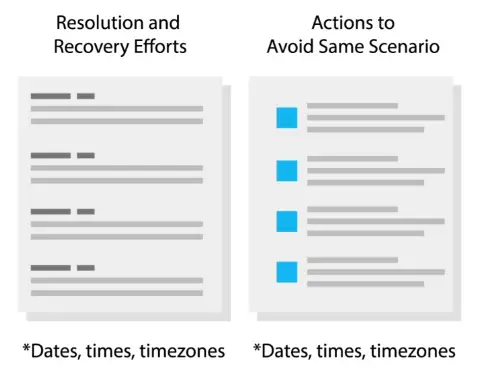



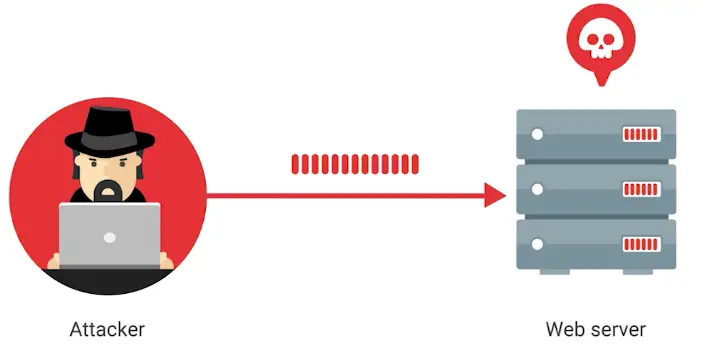
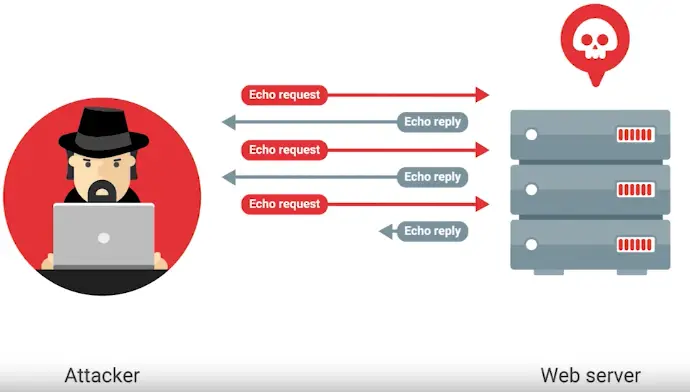
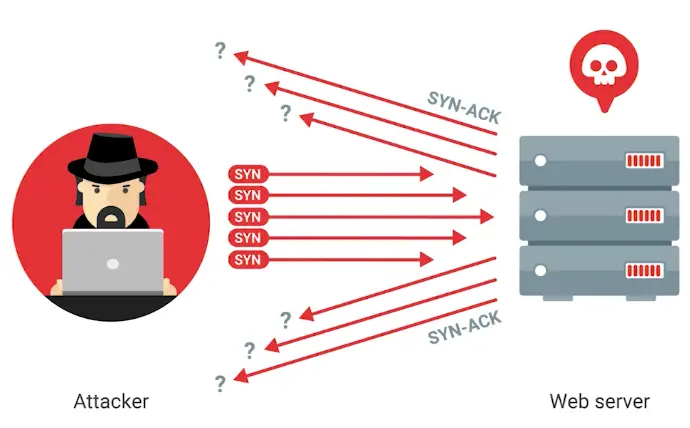



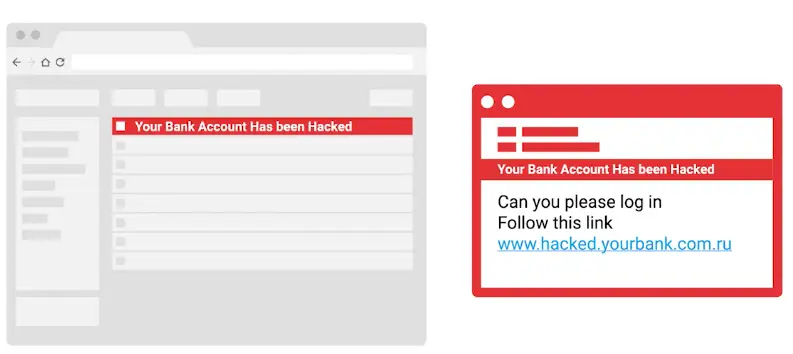
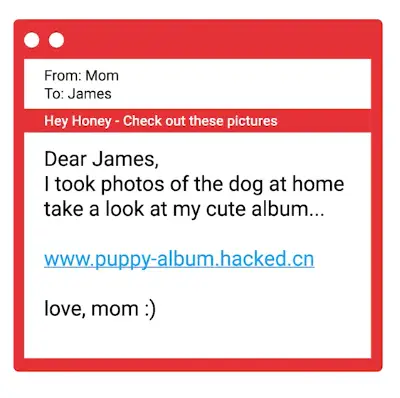
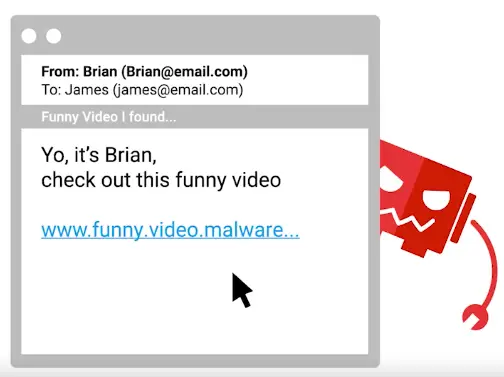

.webp)
-1.webp)
-2.webp)
-3.webp)
-4.webp)
-5.webp)
-6.webp)
-7.webp)
-8.webp)
-9.webp)
-10.webp)
-11.webp)
-12.webp)
-13.webp)
-14.webp)
-15.webp)
-16.webp)